实时离线数仓实战V2是在实时离线数仓实战V1的基础上进行扩展的系列文章。相比V1,V2主要的内容包括数据库表的调整、增加数仓建模的内容扩展、数仓性能调优等内容。

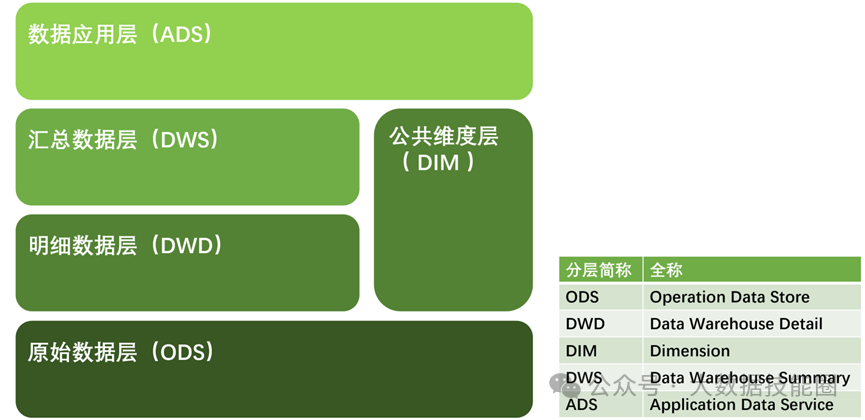
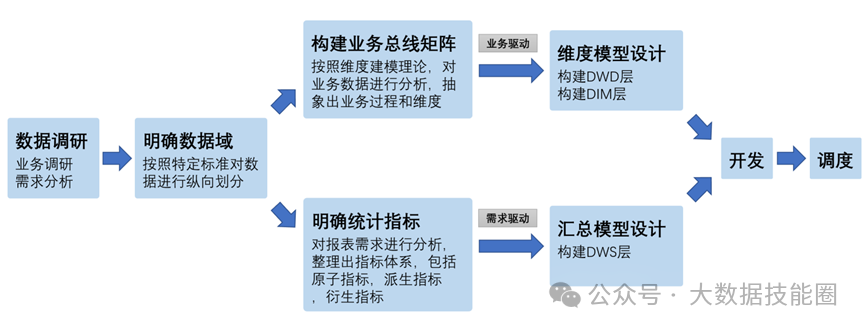
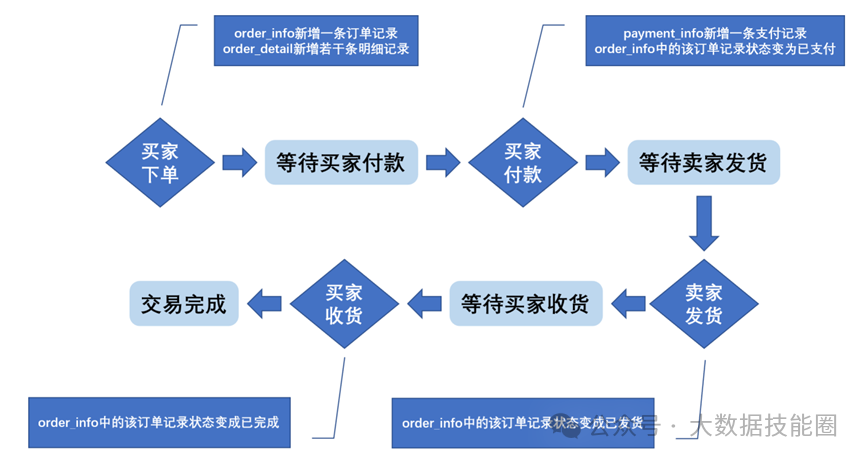
想要使数据仓库中的数据真正发挥最大的作用,必须对其进行分层,数据仓库分层的优点如下。• 将复杂问题简单化。可以将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的任务。• 减少重复开发。规范数据分层,通过使用中间层数据,可以大大减少重复计算量,增加计算结果的复用性。• 清晰数据结构。每个数据分层都有它的作用域,这样我们在使用表的时候更方便定位和理解。• 数据血缘追踪。我们最终向业务人员展示的是一张能直观看到结果的数据表,但是这张表的数据来源可能有很多,如果结果表出现问题,则可以快速定位到问题位置,并清楚危害范围。数据调研的工作分为两项,分别是业务调研和需求分析。这两项工作做的是否充分,直接影响数据仓库的质量。下面以电商的交易业务为例进行演示,交易业务涉及的业务过程有买家下单、买家支付、卖家发货、买家收货,具体流程如图所示。在分析以上需求时,需要明确需求所包括的业务过程及维度,例如,该需求所包括的业务过程是买家下单,所包括的维度有日期、省份、商品分类。数据仓库模型设计除了进行横向分层,通常还需要根据业务情况纵向划分数据域。划分数据域的意义是便于数据的管理和应用。通常可以根据业务过程或者部门进行划分,本数据仓库项目根据业务过程进行划分,需要注意的是,一个业务过程只能属于一个数据
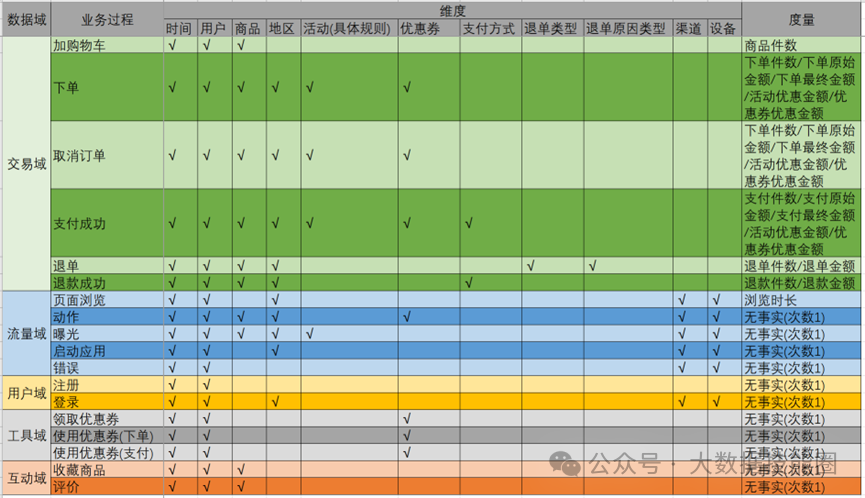
2.3 构建业务总线矩阵
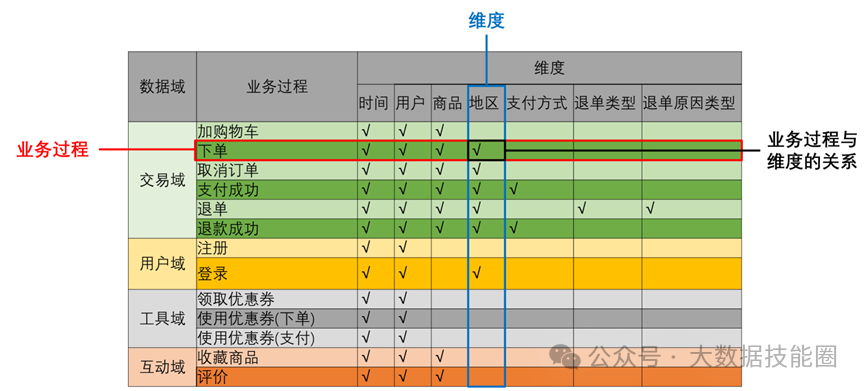
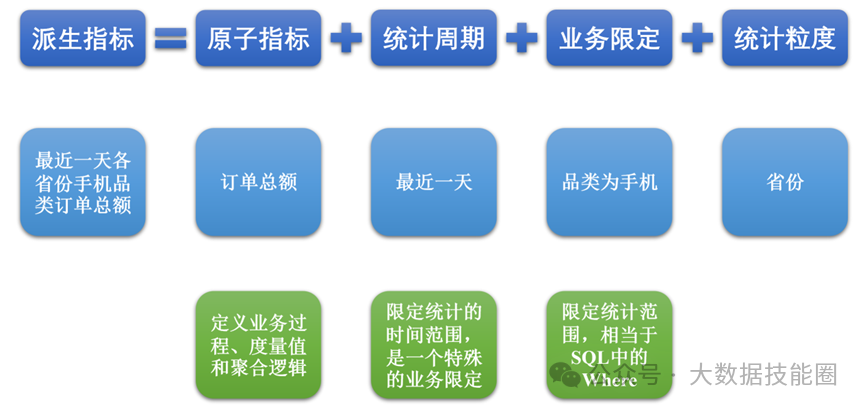
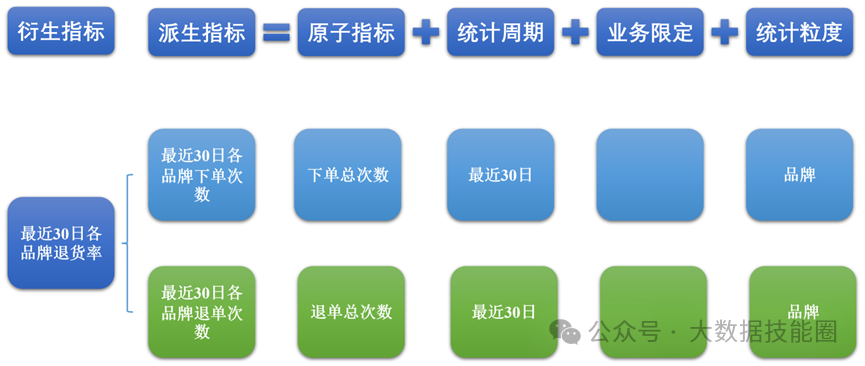
业务总线矩阵中包含维度模型所需的所有事实(业务过程)和维度,以及各业务过程与各维度的关系。如图所示,矩阵的行是一个个业务过程,矩阵的列是一个个的维度,行列的交点表示业务过程与维度的关系。按照事务事实表的构建流程(选择业务过程→声明粒度→确定维度→确定事实),得到的最终的业务总线矩阵如表所示,后续DWD层与DIM层的搭建都需要参考该矩阵。明确统计指标具体的工作是:深入分析需求,构建指标体系。构建指标体系的主要意义就是使指标定义标准化。所有指标的定义都必须遵循同一套标准,这样能有效地避免指标定义存在歧义、指标定义重复等问题。原子指标基于某一业务过程的度量,是业务定义中不可再拆解的指标,原子指标的核心功能就是对指标的聚合逻辑进行定义。我们可以得出结论,原子指标包含三要素,分别是业务过程、度量和聚合逻辑。派生指标基于原子指标,其与原子指标的关系如图所示。派生指标就是在原子指标的基础上增加修饰限定,如日期限定、业务限定、粒度限定等。如图所示,在订单总额这个原子指标上增加日期限定(最近一日)、业务限定(手机分类)、粒度限定(省份)就获得了一个派生指标:最近一日各省份手机分类的订单总额。衍生指标是在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的,如比率、比例等类型的指标。衍生指标也会对应实际的统计需求。如图所示,有两个派生指标,分别是最近30日各品牌下单次数和最近30日各品牌退单次数,通过这两个派生指标之间的逻辑运算,可以得到衍生指标,即最近30日各品牌退货率。维度模型的设计参照上文中提到的业务总线矩阵即可。事实表存储在DWD层中,维度表存储在DIM层中。汇总模型的设计参考整理出的指标体系(主要是派生指标)即可。
汇总表与派生指标的对应关系是:一张汇总表通常包含业务过程相同、日期限定相同、粒度限定相同的多个派生指标。
精彩推荐
实时离线数仓实战No.6 | 雪花模型、星形模型与星座模型详解 →
实时离线数仓实战No.5 | 业务数据生成实战及数据模型梳理 →
Flink面试全攻略:从基础到进阶的必知必会 →
Kafka面试必刷题:核心概念与架构剖析 →
Spark面试必看:核心概念与架构深度解析
请各位读者动动手指点赞、收藏、在看,您的支持是我持续创作的动力,感谢。