




Apache Flink是大数据领域流行的流批处理计算引擎。数据湖是云时代的一种新技术架构。这导致了基于Iceberg、Hudi和Delta Lake的解决方案的兴起。Apache Iceberg目前支持Flink通过DataStream API/Table API将数据写入Iceberg表,并为Apache Flink 1.11.x提供集成支持。
集成Flink+Iceberg+Presto实现基于数据湖的准实时数仓案例。整体设计架构如图所示。

继续使用淘宝用户行为数据集UserBehavior_part.csv来实时生成用户行为数据,使用Kafka作为流数据入口,使用Flink SQL Client执行实时入库操作,使用Presto执行分钟级的OLAP联机分析处理。
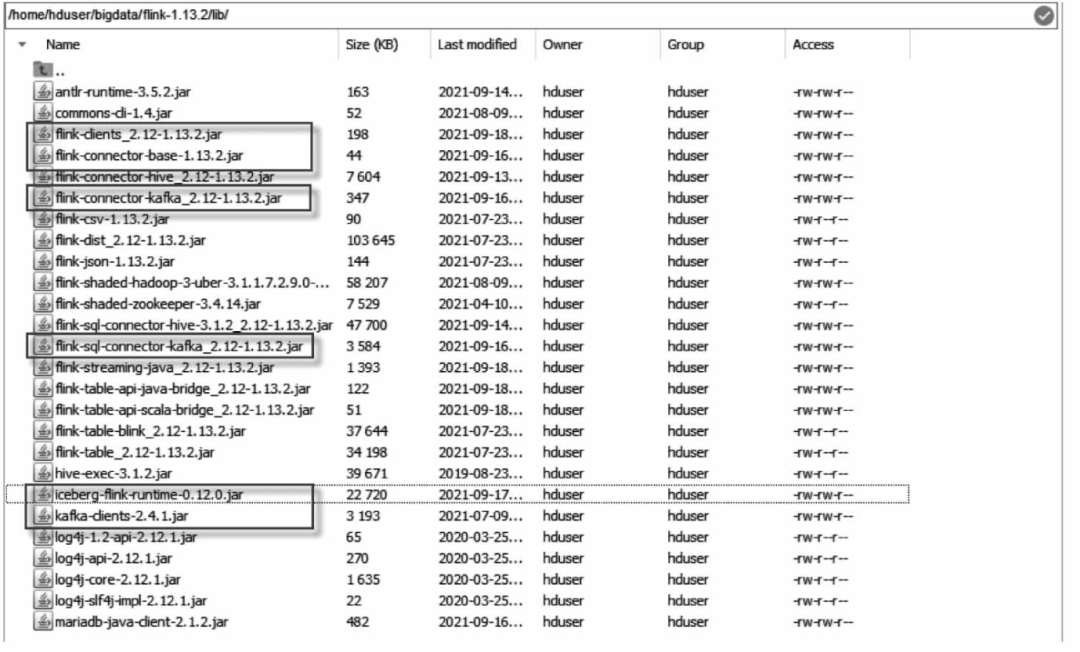
因为这里Flink SQL Client要访问Kafka源表及使用Iceberg表格式,所以需要将相关的JAR包添加到Flink安装路径的lib目录下,包括:
(1)iceberg-flink-runtime-0.12.0.jar。
(2)kafka-clients-2.4.1.jar。
(3)flink-connector-base-1.13.2.jar。
(4)flink-connector-kafka_2.12-1.13.2.jar。
(5)flink-sql-connector-kafka_2.12-1.13.2.jar。
接下来,建议按以下步骤执行:
1.1
环境准备
首先准备好运行环境,包括Hadoop集群、Hive Metastore服务、Kafka集群、Flink on YARN session。建议按以下步骤操作:
(1)启动HDFS集群
在终端窗口中,执行的命令如下:
$ start-dfs.sh$ start-yarn.sh
(2)启动Hive Metastore服务
在终端窗口中,执行的命令如下(保持运行):
$ hive --service metastore
(3)启动Kafka集群
建议按下面的注释说明执行。
#切换到Kafka安装目录$ cd ~/bigdata/kafka_2.12 -2.4.1#打开一个终端,运行ZooKeeper$ ./bin/zookeeper-server-start.sh ./config/zookeeper.properties#另打开一个终端,运行Kafka服务器$ ./bin/kafka-server-start.sh./config/server.properties#再打开一个终端,创建名为user_behavior的Kafka topic$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1-partitions 1 --topic user_behavior#查看已经存在的Topics$ ./bin/kafka-topics.sh --list -- zookeeper localhost:2181
(4)启动Flink集群
(注意,这里使用Flink on YARN session模式)。在终端窗口中,执行的命令如下:
$ cd ~/bigdata/flink-1.13.2$export HADOOP_CLASSPATH='hadoop classpath'$ ./bin/yarn-session.sh --detached
1.2
启动Flink SQL客户端
启动Flink SQL Client。在终端窗口中,执行的命令如下:
$ export HADOOP_CLASSPATH= 'hadoop classpath'$cd ~/bigdata/flink-1.13.2$ ./bin/sql-client.sh embedded --session application_1623048264828_0001
注意,记得将应用程序id修改为读者当前正在运行的应用程序id。
1.3
创建Kafka流表(源表)
在默认catalog下,创建Kafka源表。在Flink SQL Client命令行,执行以下语句:
-- 查看 catalogsshow catalogs;-- 创建Kafka源表DROP TABLE IF EXISTS user_behavior_kafka;CREATE TABLE user_behavior_kafka (user_id bigint,item_id bigint,category_id bigint,behavior string,ts bigint,procTime AS PROCTIME(),eventTime AS TO_TIMESTAMP(FROM_UNIXTIME(ts,'YYYY-MM-dd HH:mm:ss')),WATERMARK FOR eventTime AS eventTime - INTERVAL '5'SECONDS)with('connector'= 'kafka','topic'= 'user_behavior','properties.Bootstrap.servers'= 'xueai8:9092','properties.group.id'= 'testGroup','scan.startup.mode'= 'latest - offset','format'= 'csv','csv.ignore-parse-errors'= 'true','csv.field-delimiter'= ',');show catalogs;
1.4
创建Iceberg Hive Catalog及Iceberg Sink表
Flink会实时读取Kafka的用户购买行为记录并写入Iceberg Sink表中,因此,下面先定义一个可用的Iceberg Catalog,然后在该Catalog中定义数据库和接收表。继续在Flink SQL Client命令行执行以下语句:
定义可用的Iceberg CatalogsCREATE CATALOG iceberg_hive_catalog WITH ('type'= 'iceberg','catalog-type'= 'hive','uri'= 'thrift://localhost:9083','clients'= '5','property- version' = '1','hive-conf-dir'='/home/hduser/bigdata/flink- 1.13.2/cot);-- 切换到 Iceberg CatalogUSE CATALOG iceberg_hive_catalog;-- 创建 iceberg_db数据库CREATE DATABASE IF NOT EXISTS iceberg_db;-- 查看当前Catalog中有哪些数据库show databases;-- 切换数据库use iceberg_db;-- 在看当前Catalog中的当前数据库中有哪些表show tables;-- 创建Iceberg Sink 表DROP TAHLE IF EXISTS iceberg_db.user_behavior_hive;CREATE TABLE iceberg_db, user_behavior_hive (user_id bigint,item_id bigint,category_id bigint,behavior string,ts bigint,ts_date string,ts_hour string,ts_minute string) PARTITIONED BY (ts_date,ts_hour,ts_minute)WITH ('connector'= 'iceberg', 'write.format. default' = ‘ORC');执行实时 ETLINSERT INTO iceberg_db. user_behavior_hiveSELECTuser_id,item_id,category_id, behavior,ts,FROM_UNIXTIME(ts,'YYYY-MM-dd') as ts_date,FROM_UNIXTIME(ts, 'HH') as ts_hour,FROM_UNIXTIME(ts, 'mm') as ts_minuteFROM default_catalog. default_database. user_behavior_kafkaWHERE item_id> 0;
接下来,使用Presto执行OLAP联机分析处理,对iceberg_db.user_behavior_hive表执行聚合操作,每10min统计一次用户的各种行为。
Apache Presto是由Facebook开发的一个分布式并行查询执行引擎,对低时延和交互式查询分析进行了优化。Presto可以轻松地运行查询,而且不需要停机时间,甚至可以从GB级扩展到PB级。
建议按以下步骤配置和使用Presto。
2.1
配置Iceberg连接器
Apache Iceberg连接器允许查询Iceberg表中存储的数据。
要配置Apache Iceberg连接器,需要在Presto安装目录下的etc/catalog/子目录中创建一个catalog目录属性文件iceberg.properties(etc/catalog/iceberg.properties),命令如下:
$cd ~/bigdata/presto-server-0.261/etc/catalog$ nano iceberg.properties
2.2
运行Presto服务器
在前台运行Presto服务器。在终端窗口中执行的命令如下:
$ cd ~/bigdata/presto-server-0.261$ bin/launcher run
2.3
运行Presto CLI客户端
通过Presto CLI连接Presto服务器。在终端窗口中执行的命令如下:
$ cd ~/bigdata/presto-server-0.261$ ./bin/presto-cli-0.261-executable.jar --server localhost:8989
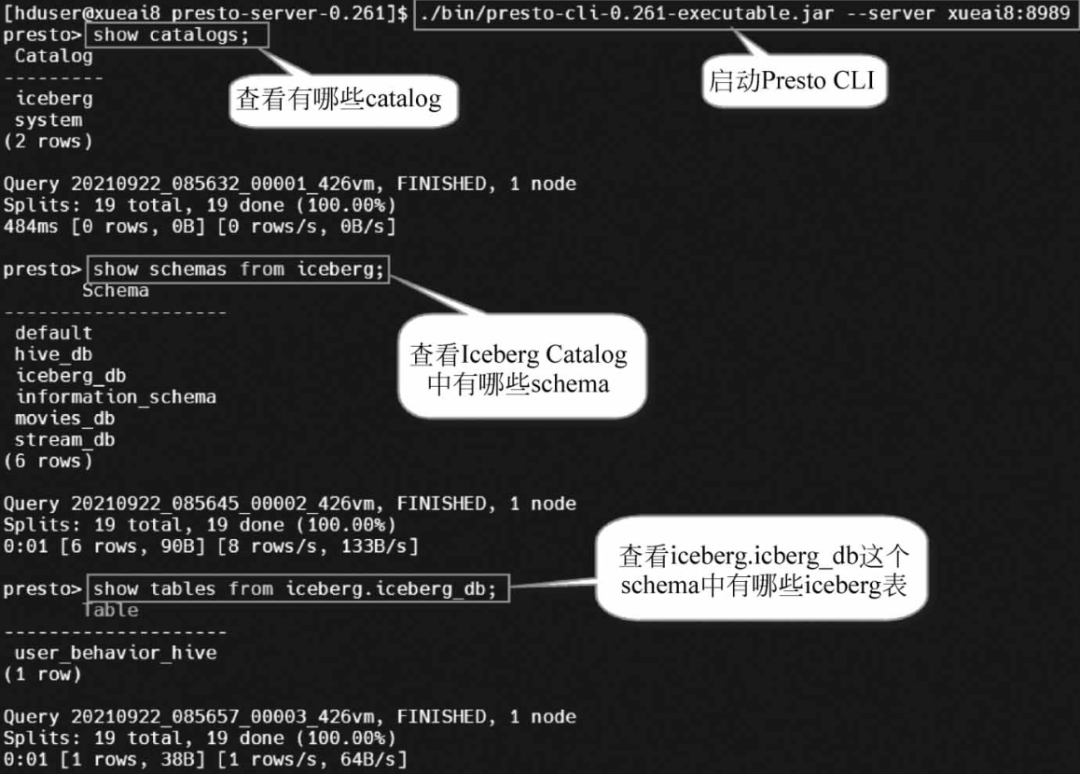
然后在Presto CLI中执行如下SQL语句:
presto> show catalogs;presto> show schemas from iceberg;presto> show tables from iceberg.iceberg_db;
执行过程和结果如图所示。
2.4
执行聚合操作
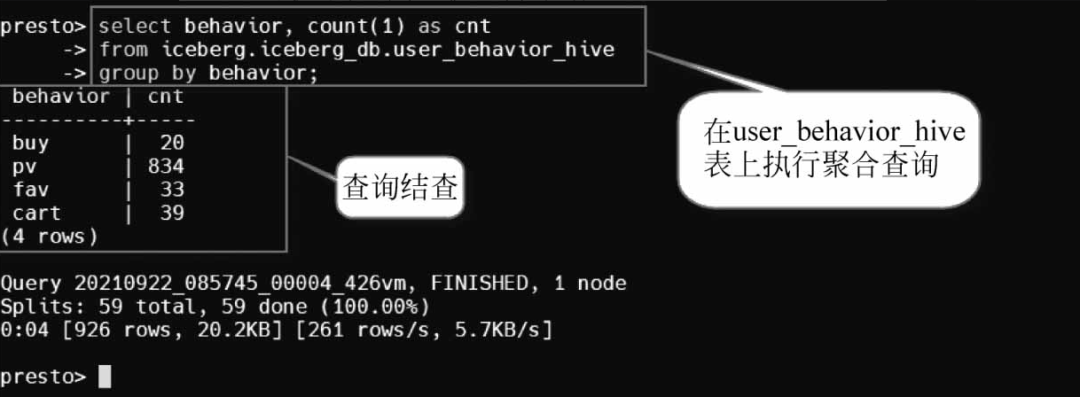
接下来,执行聚合查询,统计各种用户购买行为。在Presto CLI中执行Presto SQL查询,语句如下:
presto> select behavior,count(1) as cnt-> from iceberg.iceberg_db.user_behavior_hive-> group by behavior;
执行过程和执行结果如图所示。
2.5
退出Presto CLI
presto> exit;
2.6
关闭Presto服务器
$ bin/launcher stop
