




大家好啊,最近在做 Flink 消费 Kafka 的性能优化,踩了不少坑,今天给大家分享一下我的实战经验 🚀
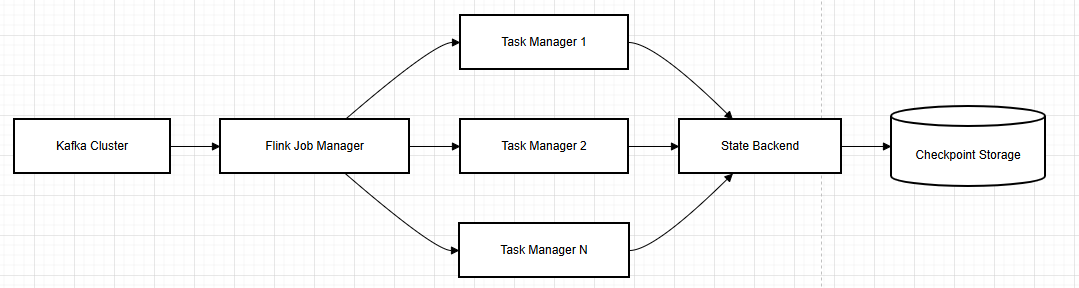
没错,就是这么个经典架构。不过关键不在架构图,而在于怎么调优。说实话,刚开始我也是一脸懵,后来经过无数次线上事故(😅)才总结出这些经验。
💡 重点配置都在这了
Kafka 消费者配置
Properties props = new Properties();// 基础连接配置props.setProperty("bootstrap.servers", "kafka1:9092,kafka2:9092");props.setProperty("group.id", "flink-group");// 消费者配置 - 这些都是我调了很久的最佳实践props.setProperty("fetch.min.bytes", "1048576"); 1MB,别设太小,影响吞吐量props.setProperty("fetch.max.wait.ms", "500"); 我之前设1000ms,延迟太高了props.setProperty("max.partition.fetch.bytes", "5242880"); 5MB,根据数据量调整props.setProperty("max.poll.records", "10000"); 单次拉取条数,太大容易OOMprops.setProperty("receive.buffer.bytes", "1048576"); 网络接收缓冲区props.setProperty("send.buffer.bytes", "1048576"); // 网络发送缓冲区// 消费者重试和超时配置props.setProperty("session.timeout.ms", "30000"); // 会话超时时间props.setProperty("heartbeat.interval.ms", "10000"); // 心跳间隔props.setProperty("max.poll.interval.ms", "300000"); // 最大拉取间隔props.setProperty("request.timeout.ms", "30000"); // 请求超时时间// 序列化配置props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 安全配置(如果需要)props.setProperty("security.protocol", "SASL_PLAINTEXT");props.setProperty("sasl.mechanism", "PLAIN");
Flink 配置
说实话,这块配置最坑了,我调了好久:
# JobManager 配置jobmanager:memory:process:size: 4096m # 给大点,不然元数据多了扛不住jvm-metaspace:size: 512m # 元空间也得够jvm-overhead:fraction: 0.1# TaskManager 配置taskmanager:memory:process:size: 8192m # 总内存,建议8G起步framework:heap:size: 1024m # 框架堆内存task:heap:size: 4096m # 任务堆内存,这个最重要managed:size: 2048m # 托管内存,RocksDB用这个jvm-metaspace:size: 512m # JVM元空间jvm-overhead:fraction: 0.1 # JVM开销# CPU 配置cpu:cores: 4.0 # CPU核心数,根据实际机器配置# 网络配置network:memory:fraction: 0.1request-backoff:initial: 100max: 10000# Checkpoint 配置execution:checkpointing:interval: 180000 # 3分钟一次,太频繁CPU吃不消timeout: 120000 # 超时时间,给够点min-pause: 60000 # 最小间隔1分钟max-concurrent: 1 # 并发checkpoint数量mode: EXACTLY_ONCE # 精确一次语义unaligned: true # 非对齐checkpoint,建议开启externalized:enabled: true # 外部化checkpoint# State Backend 配置state:backend: rocksdb # 用RocksDB准没错backend.incremental: true # 增量checkpointcheckpoints:dir: hdfs://namenode:8020/flink/checkpoints # 存储路径savepoints:dir: hdfs://namenode:8020/flink/savepoints # 保存点路径# RocksDB 具体配置rocksdb:block-cache-size: 256mb # 块缓存大小write-buffer-size: 64mb # 写缓存大小max-write-buffer-number: 4 # 最大写缓存数block-size: 64kb # 块大小compaction-style: LEVEL # 压缩方
🔧 内存配置实战经验
1. 基础配置公式
总内存分配建议:- 任务堆内存:40-50%- 托管内存:30-40%- 框架内存:10-15%- JVM开销:10-15%
taskmanager:memory:process:size: 8gtask:heap:size: 4gmanaged:size: 2g
中规模作业(数据量 100GB-1TB/天)
taskmanager:memory:process:size: 16gtask:heap:size: 8gmanaged:size: 6g
大规模作业(数据量 > 1TB/天)
taskmanager:memory:process:size: 32gtask:heap:size: 16gmanaged:size: 12g
3. RocksDB 场景特殊配置
# RocksDB 优化配置state:backend: rocksdbbackend.memory.managed: truerocksdb:block-cache-size: 256mb # 读缓存write-buffer-size: 128mb # 写缓存max-write-buffer-number: 4 # 写缓存个数taskmanager:memory:managed:fraction: 0.4 # 托管内存占比提高framework:heap:size: 1g # 框架内存可以适当减少

推荐阅读系列文章
建议收藏 | Dinky系列总结篇 建议收藏 | Flink系列总结篇 建议收藏 | Flink CDC 系列总结篇 建议收藏 | Doris实战文章合集 建议收藏 | Paimon 实战文章总结 建议收藏 | Fluss 实战文章总结 建议收藏 | Seatunnel 实战文章系列合集 建议收藏 | 实时离线输数仓(数据湖)总结篇 建议收藏 | 实时离线数仓实战第一阶段总结 超700star!电商项目数据湖建设实战代码 ,拿来即用! 从0到1建设电商项目数据湖实战教程 推荐一套开源电商项目数据湖建设实战代码
文章转载自大数据技能圈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
