




1. DATAX 节点
1.1 综述
DataX 任务类型,用于执行 DataX 程序。对于 DataX 节点,worker 会通过执行 ${DATAX_HOME}/bin/datax.py 来解析传入的 json 文件。
默认会使用python2.7去执行datax.py,如果需要使用其他版本的python去执行datax.py,需要在环境变量中配置DATAX_PYTHON。
1.2 创建任务
•点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
•拖动工具栏的 任务节点到画板中。
1.3 任务参数
任务参数 | 描述 |
json | DataX 同步的 json 配置文件 |
资源 | 在使用自定义json中如果集群开启了kerberos认证后,datax读取或者写入hdfs、hbase等插件时需要使用相关的keytab,xml文件等,则可使用改选项。资源中心-文件管理上传或创建的文件 |
自定义参数 | sql 任务类型,而存储过程是自定义参数顺序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换 sql 语句中 ${变量} |
数据源 | 选择抽取数据的数据源 |
sql 语句 | 目标库抽取数据的 sql 语句,节点执行时自动解析 sql 查询列名,映射为目标表同步列名,源表和目标表列名不一致时,可以通过列别名(as)转换 |
目标库 | 选择数据同步的目标库 |
目标库前置 | 前置 sql 在 sql 语句之前执行(目标库执行) |
目标库后置 | 后置 sql 在 sql 语句之后执行(目标库执行) |
限流(字节数) | 限制查询的字节数 |
限流(记录数) | 限制查询的记录数 |
1.4 任务样例
该样例演示为从 Hive 数据导入到 MySQL 中。
1.4.1 在 DolphinScheduler 中配置 DataX 环境
若生产环境中要是使用到 DataX 任务类型,则需要先配置好所需的环境。配置文件如下:/dolphinscheduler/conf/env/dolphinscheduler_env.sh。
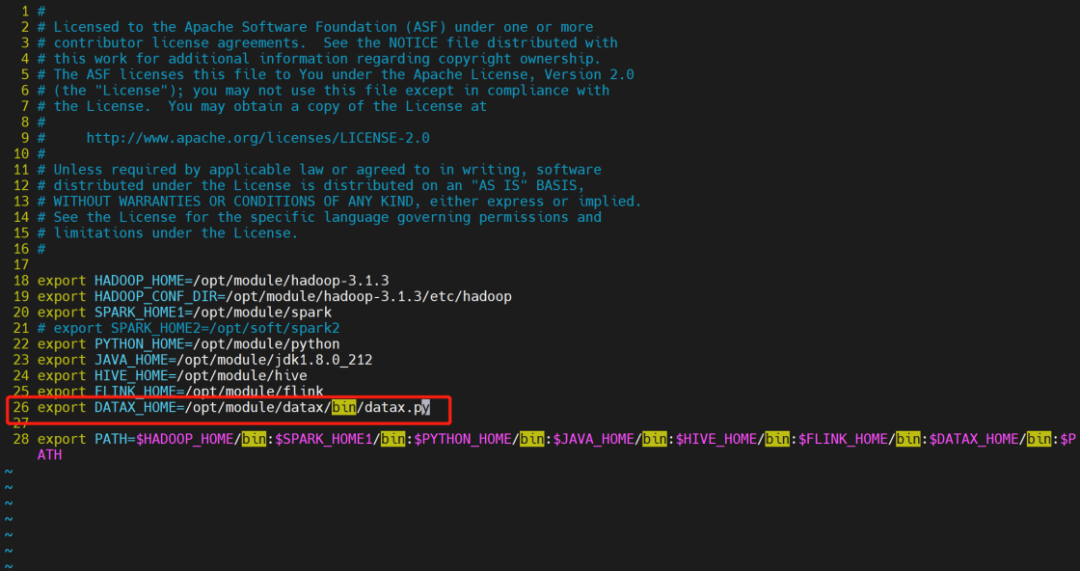
当环境配置完成之后,需要重启 DolphinScheduler。
1.4.1 配置 DataX 任务节点
由于默认的的数据源中并不包含从 Hive 中读取数据,所以需要自定义 json,可参考:HDFS Writer。其中需要注意的是 HDFS 路径上存在分区目录,在实际情况导入数据时,分区建议进行传参,即使用自定义参数。
在编写好所需的 json 之后,可按照下图步骤进行配置节点内容。
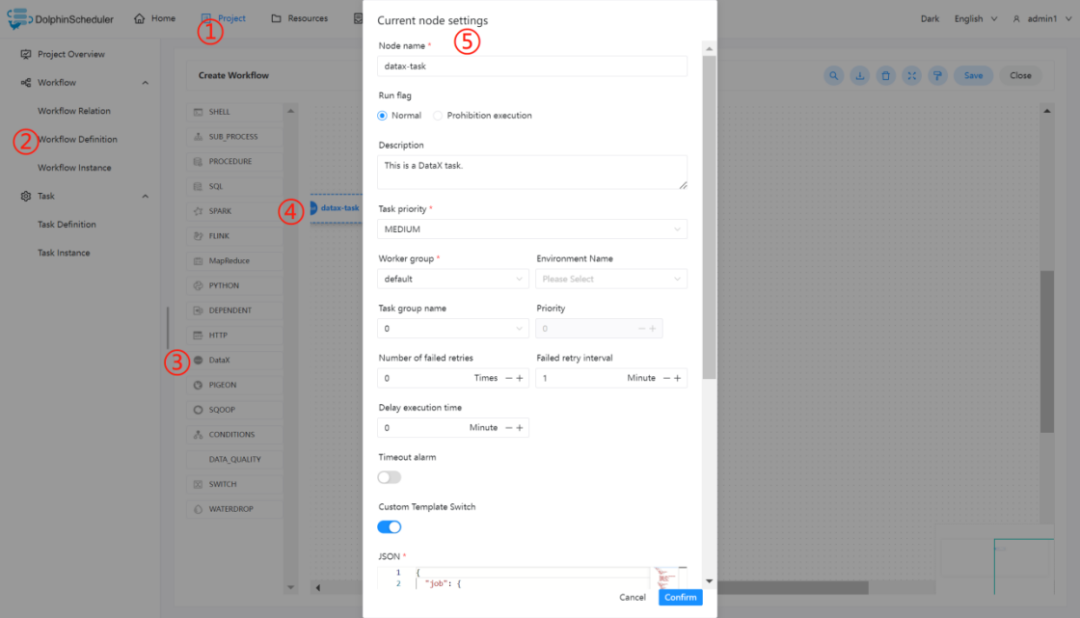
1.4.2 查看运行结果
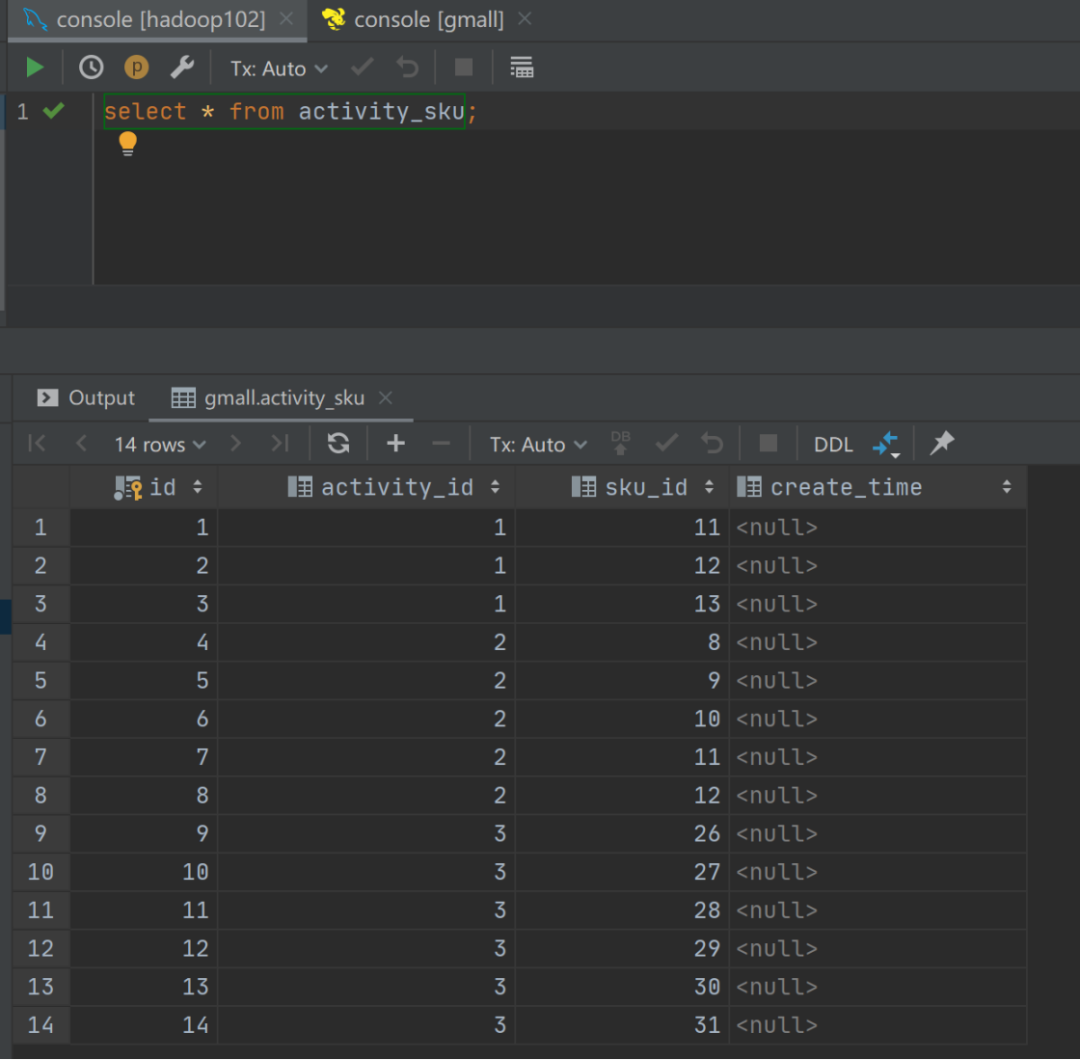
1.4.3 注意事项:
若默认提供的数据源不满足需求,可在自定义模板选项中,根据实际使用环境来配置 DataX 的 writer 和 reader
2. Flink节点
2.1 综述
Flink 任务类型,用于执行 Flink 程序。对于 Flink 节点:
当程序类型为 Java、Scala 或 Python 时,worker 使用 Flink 命令提交任务 flink run。更多详情查看 flink cli 。
当程序类型为 SQL 时,worker 使用sql-client.sh 提交任务。更多详情查看 flink sql client 。
2.2 创建任务
•点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
•拖动工具栏的 任务节点到画板中。
任务节点到画板中。
2.3 任务参数
任务参数 | 描述 |
程序类型 | 支持 Java、Scala、 Python 和 SQL 四种语言 |
主函数的 Class | Flink 程序的入口 Main Class 的全路径 |
主程序包 | 执行 Flink 程序的 jar 包(通过资源中心上传) |
部署方式 | 支持 cluster、 local 和 application (Flink 1.11和之后的版本支持,参见 Run an application in Application Mode) 三种模式的部署 |
初始化脚本 | 用于初始化会话上下文的脚本文件 |
脚本 | 用户开发的应该执行的 SQL 脚本文件 |
Flink 版本 | 根据所需环境选择对应的版本即可 |
任务名称(选填) | Flink 程序的名称 |
jobManager 内存数 | 用于设置 jobManager 内存数,可根据实际生产环境设置对应的内存数 |
Slot 数量 | 用于设置 Slot 的数量,可根据实际生产环境设置对应的数量 |
taskManager 内存数 | 用于设置 taskManager 内存数,可根据实际生产环境设置对应的内存数 |
taskManager 数量 | 用于设置 taskManager 的数量,可根据实际生产环境设置对应的数量 |
并行度 | 用于设置执行 Flink 任务的并行度 |
主程序参数 | 设置 Flink 程序的输入参数,支持自定义参数变量的替换 |
选项参数 | 支持 --jar、--files、--archives、--conf 格式 |
自定义参数 | 是 Flink 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容 |
2.4 任务样例
2.4.1 执行 WordCount 程序
本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。(Flink 的 Releases 附带了此示例作业)
2.4.1.1 在 DolphinScheduler 中配置 flink 环境
若生产环境中要是使用到 flink 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
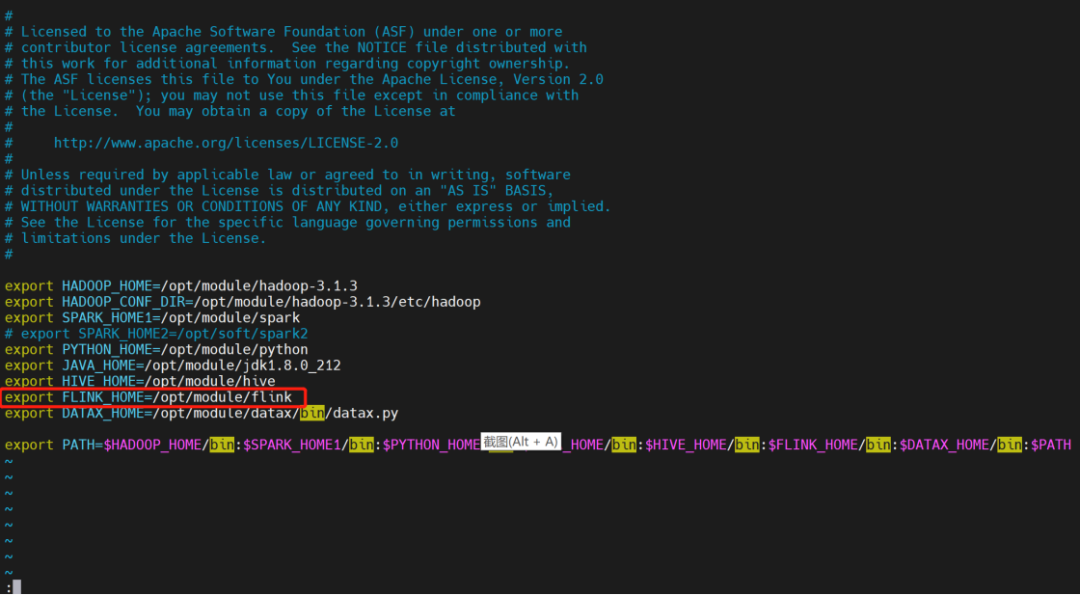
2.4.1.2 上传主程序包
在使用 Flink 任务节点时,需要利用资源中心上传执行程序的 jar 包。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。
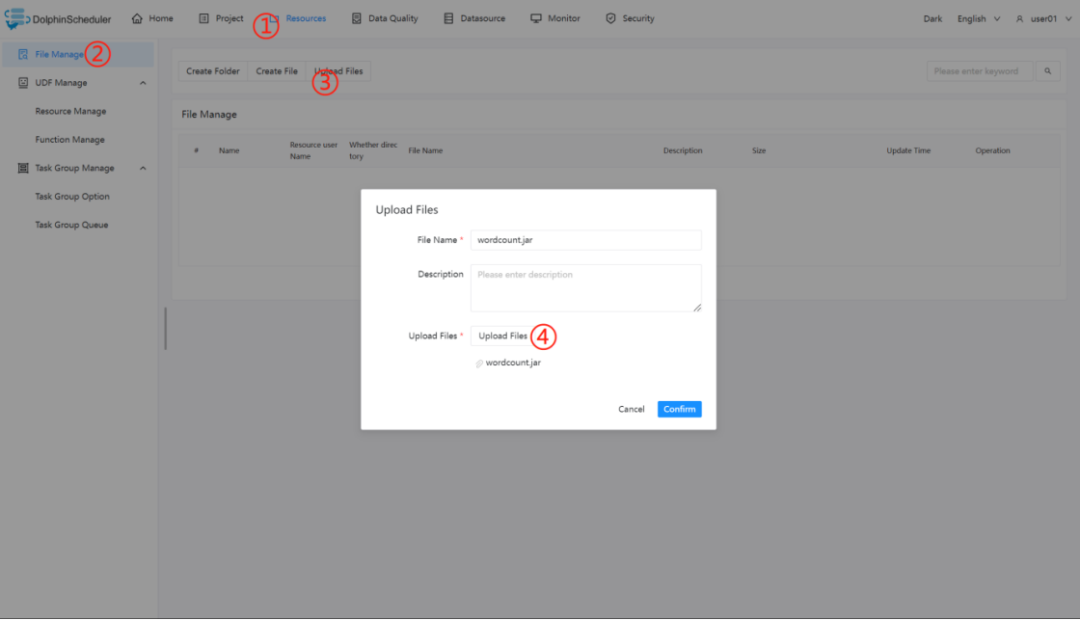
2.4.1.3 配置 Flink 节点
根据上述参数说明,配置所需的内容即可。
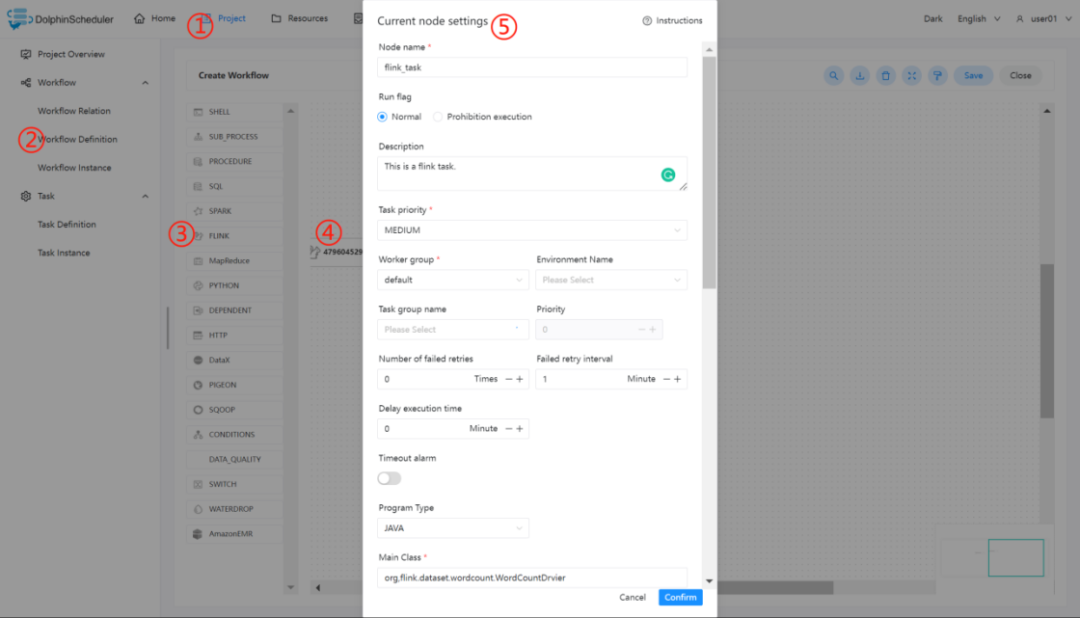
2.4.2 执行 FlinkSQL 程序
根据上述参数说明,配置所需的内容即可。
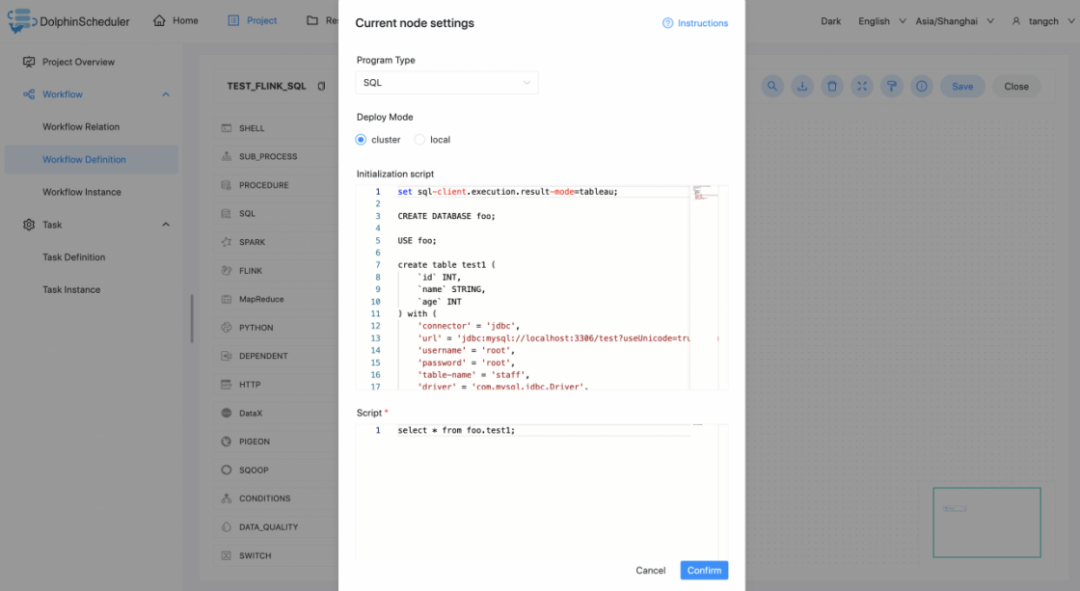
2.4.3 注意事项:
•Java 和 Scala 只是用来标识,没有区别,如果是 Python 开发的 Flink 则没有主函数的 class,其余的都一样。
•使用 SQL 执行 Flink SQL 任务,目前只支持 Flink 1.13及以上版本。
3. Hive CLI
3.1 综述
使用Hive Cli任务插件创建Hive Cli类型的任务执行SQL脚本语句或者SQL任务文件。
执行任务的worker会通过hive -e命令执行hive SQL脚本语句或者通过hive -f命令执行资源中心中的hive SQL文件。
3.2 Hive CLI任务 VS 连接Hive数据源的SQL任务
在DolphinScheduler中,我们有Hive CLI任务插件和使用Hive数据源的SQL插件提供用户在不同场景下使用,您可以根据需要进行选择。
•Hive CLI任务插件直接连接HDFS和Hive Metastore来执行hive类型的任务,所以需要能够访问到对应的服务。执行任务的worker节点需要有相应的Hive jar包以及Hive和HDFS的配置文件。但是在生产调度中,Hive CLI任务插件能够提供更可靠的稳定性。
•使用Hive数据源的SQL插件不需要您在worker节点上有相应的Hive jar包以及Hive和HDFS的配置文件,而且支持 Kerberos认证。但是在生产调度中,若调度压力很大,使用这种方式可能会遇到HiveServer2服务过载失败等问题。
3.3 创建任务
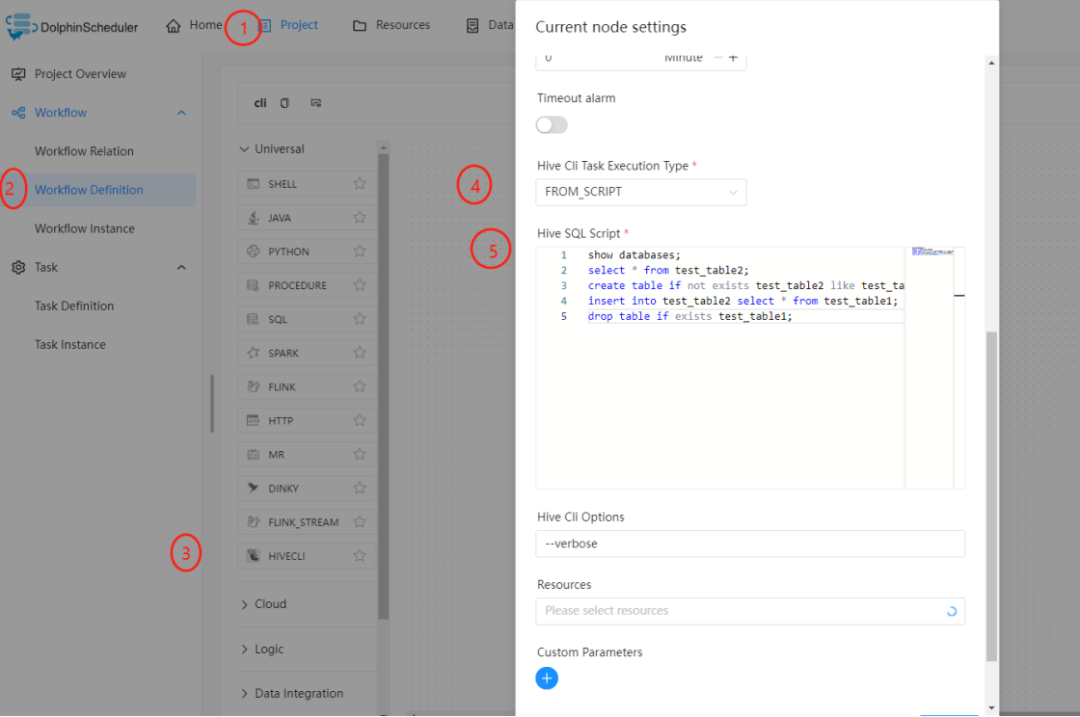
•点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
•工具栏中拖动 到画板中,即可完成创建。
到画板中,即可完成创建。
任务参数
任务参数 | 描述 |
Hive Cli 任务类型 | Hive Cli任务执行方式,可以选择FROM_SCRIPT或者FROM_FILE。 |
Hive SQL 脚本 | 手动填入您的Hive SQL脚本语句。 |
Hive Cli 选项 | Hive Cli的其他选项,如--verbose来查看任务结果。 |
资源 | 如果您选择FROM_FILE作为Hive Cli任务类型,您需要在资源中选择Hive SQL文件。 |
3.4 任务样例
Hive CLI任务样例
下面的样例演示了如何使用Hive CLI任务节点执行Hive SQL脚本语句:
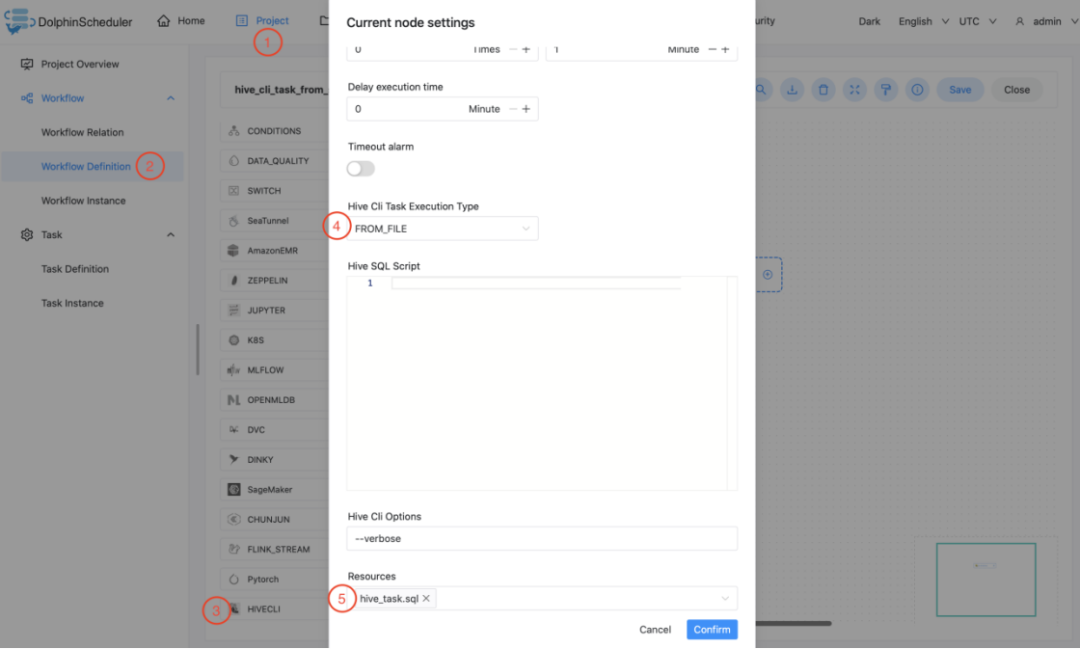
下面的样例演示了如何使用Hive CLI任务节点从资源中心的Hive SQL
更多详情请关注字节智传公众号:
