





conda create --name pyflink python=3.8
输入 y
激活pyflink环境
conda activate pyflink
虚拟环境安装pyflink
python -m pip install apache-flink==1.15.2
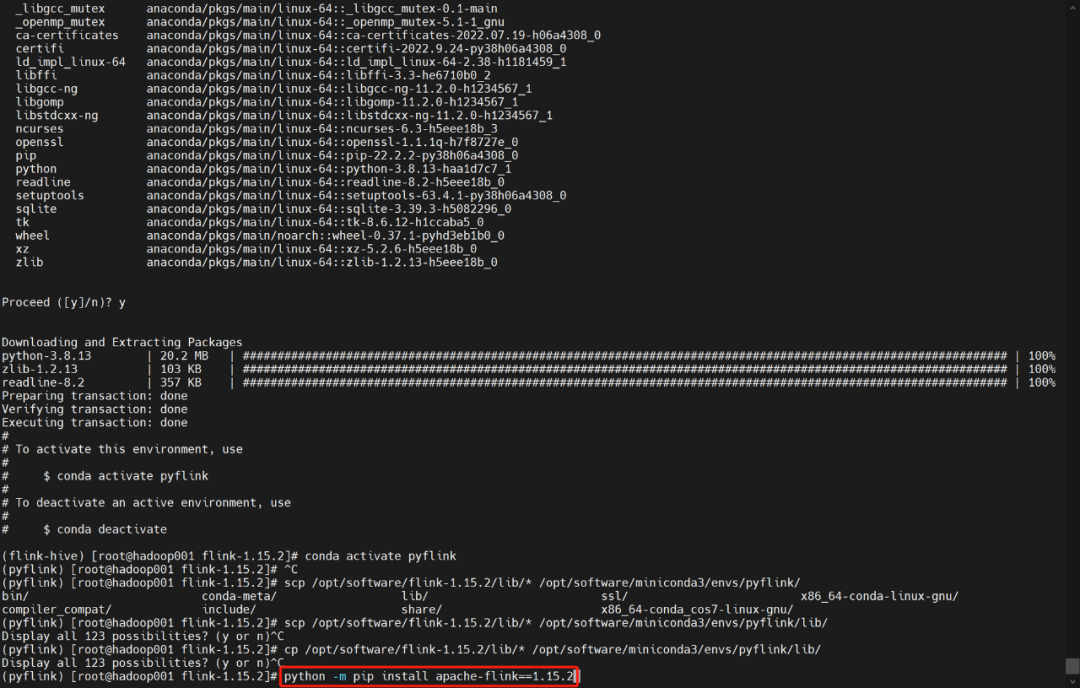
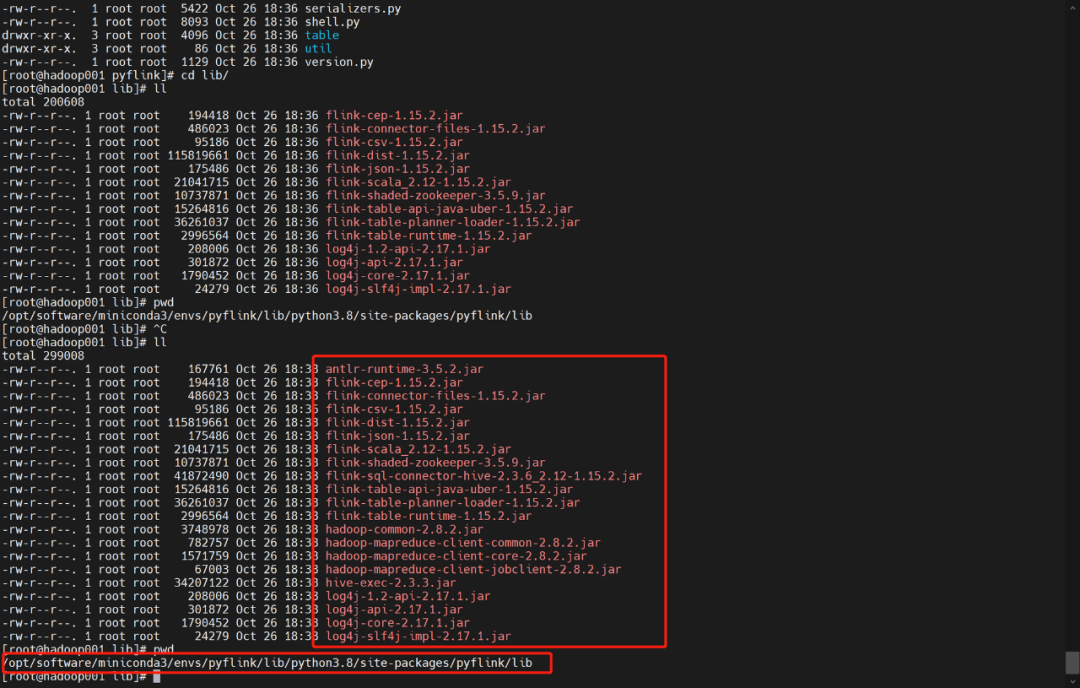
复制flink环境中的jar包到pyflink中
cp opt/software/flink-1.15.2/lib/* /opt/software/miniconda3/envs/pyflink/lib/python3.8/site-packages/pyflink/lib
编写python代码 catalog.py
from pyflink.table import *from pyflink.table.catalog import HiveCatalog, CatalogDatabase, ObjectPath, CatalogBaseTablecatalog = HiveCatalog("myhive","caijing01", "/opt/software/hive/conf")t_env = TableEnvironment.create(environment_settings=EnvironmentSettings.in_batch_mode())t_env.register_catalog("myhive", catalog)t_env.execute_sql("select * from myhive.caijing01.score5").print()t_env.execute_sql("create table myhive.caijing01.score8 like myhive.caijing01.score5")t_env.execute_sql("insert into myhive.caijing01.score8 select * from myhive.caijing01.score5")
或者
from pyflink.table import *from pyflink.table.catalog import HiveCatalogsettings = EnvironmentSettings.in_batch_mode()t_env = TableEnvironment.create(settings)source_ddl = """CREATE CATALOG myhive WITH ( 'type' = 'hive','default-database'='caijing01','hive-conf-dir' = '/opt/software/hive/conf')"""t_env.execute_sql(source_ddl)sql1= """select * from myhive.caijing01.score5"""t_env.execute_sql(sql1).print()
执行py代码
opt/software/flink-1.15.2/bin/flink run -pyexec opt/software/miniconda3/envs/pyflink/bin/python -py opt/software/flink-1.15.2/code/catalog.py
查看flink网页查看运行情况
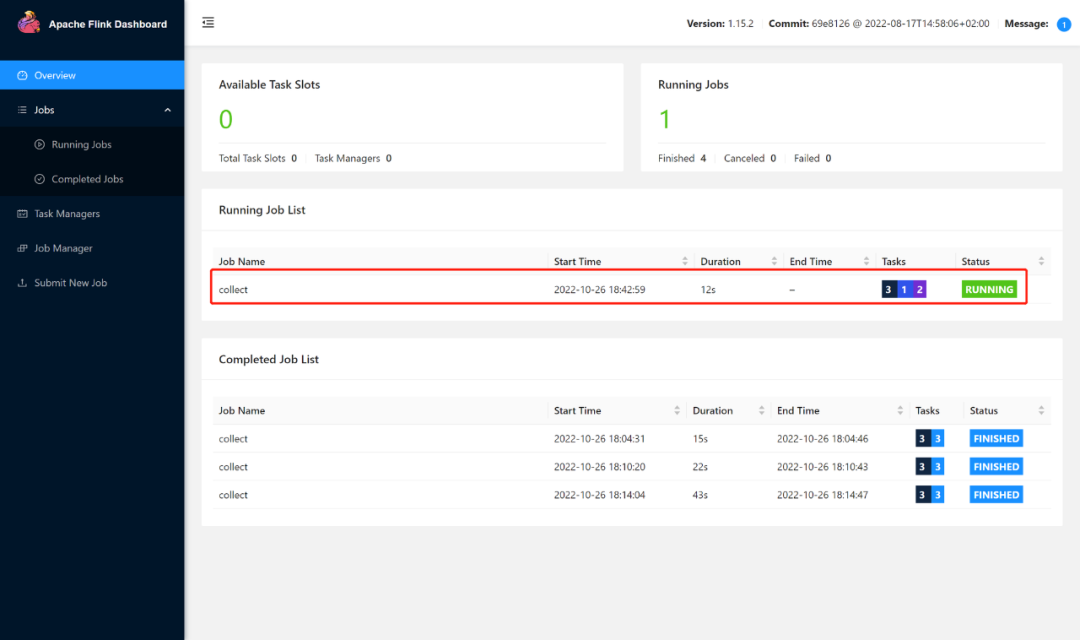
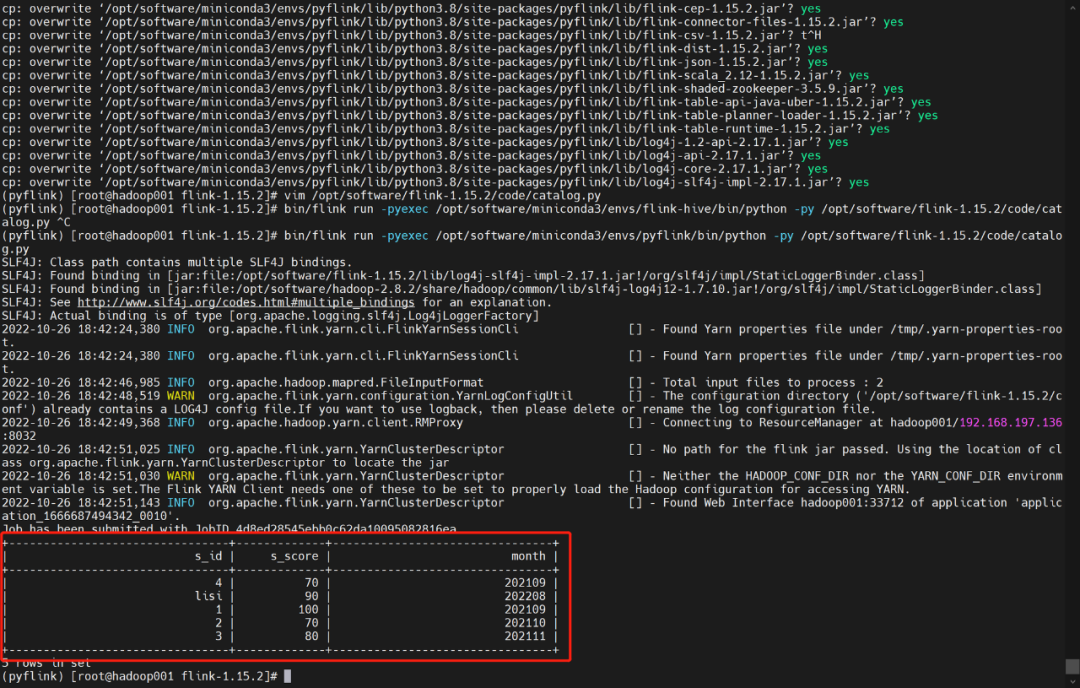
至此,Pyflink 集成 hive catalog模式读写数据完成。
更多实战详情请关注字节智传公众号

往期精彩
文章转载自大数据技能圈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
