





以2022年GPT3.5发布为节点,AGI技术开始了一路狂奔,各种充满想象力的技术概念和实现方案不断涌现,RAG(Retrieval-Augmented Generation,检索增强生成)成为了现有大模型生态中极为关键的一项技术。
通过将预先训练的 LLM 与可随时获取的信息检索系统相结合,RAG能够提供更精确和上下文相关的响应,使得 LLM 或基础模型能够根据尽可能避免幻觉从而生成更符合预期的内容。
在整个RAG系统中,数据库扮演着重要角色,无论是用来承载原始数据的数据库还是承载向量化功能的向量数据库,其性能与运维情况直接决定了RAG系统的效率。
对于企业而言,如果想要实现本地化的RAG系统构建,并在此基础上满足更多的业务需求。数据库管理是必须要走好的第一步。基于Kubernetes云原生技术打造的沃趣QFusion数据库私有云RDS,可以帮助用户轻松高效的完成集群部署、备份、扩容等工作,为企业RAG系统提供坚实的数据基础。
高可用等特性缺失,业务风险巨大
目前企业在部署RAG系统时,往往会将Ragflow或者Dify这类开源成熟的项目作为第一选择。但便利性的背后是高可用、集群化等企业级特性的缺失。
以Dify为例,其在本地部署时,默认使用的是「build in」模式的Weaviate,用户需要手动配置相关参数,且可配置参数也相对较少。
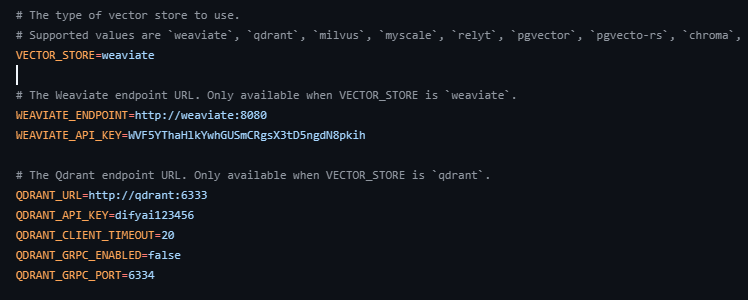
在Dify中配置向量数据库
用户虽然可以选择调整更换不同的数据库,但仍然挑战重重:
RAG系统本身不提供数据库的部署和管理能力,企业需要自行解决数据库的高可用、备份恢复等问题。
当企业需要同时使用多种数据库时(如关系型数据库存储元数据,向量数据库存储嵌入向量),无法通过单一平台进行统一管理。
随着知识库规模扩大,向量检索性能可能下降,但RAG系统不提供数据库层面的性能监控和资源扩展能力。
相比之下,QFusion提供了全面的数据安全与高可用性保障:
全链路备份:支持物理备份(如块级增量备份)与逻辑备份(如Schema导出),冷/热备份灵活切换,确保向量索引与原始数据一致性。
秒级恢复与容灾:基于WAL日志和归档模式,实现PITR(时间点恢复),精准回滚误操作或数据损坏场景;多副本架构支持跨区域容灾,结合归档日志实时同步,RTO(恢复时间目标)可控制在分钟级。
合规审计追踪:备份操作日志与数据库审计日志联动,满足数据留存与可追溯性要求。
部署、运维流程繁杂
当用户想用将自己的向量数据库部署到RAG系统中时,又会遇到哪些问题呢?
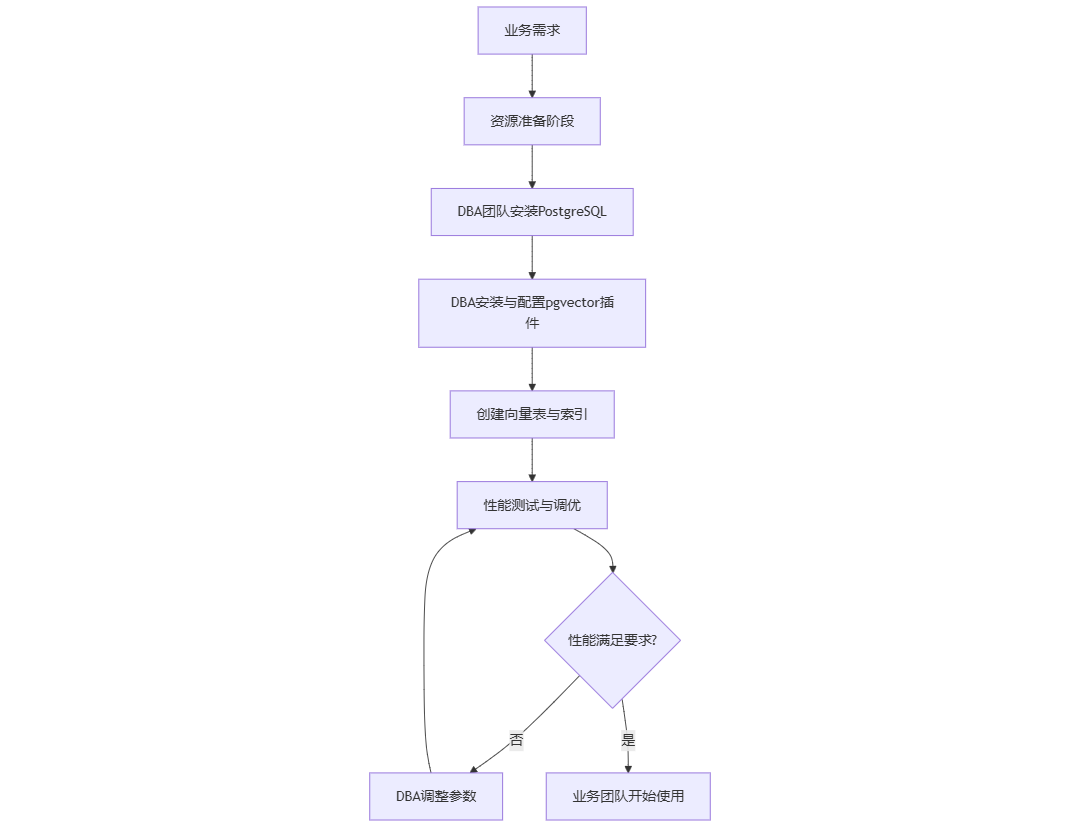
以PostgreSQL为例,如果企业不使用QFusion,部署RAG系统时,仅数据库这一单一流程就繁琐且耗时。
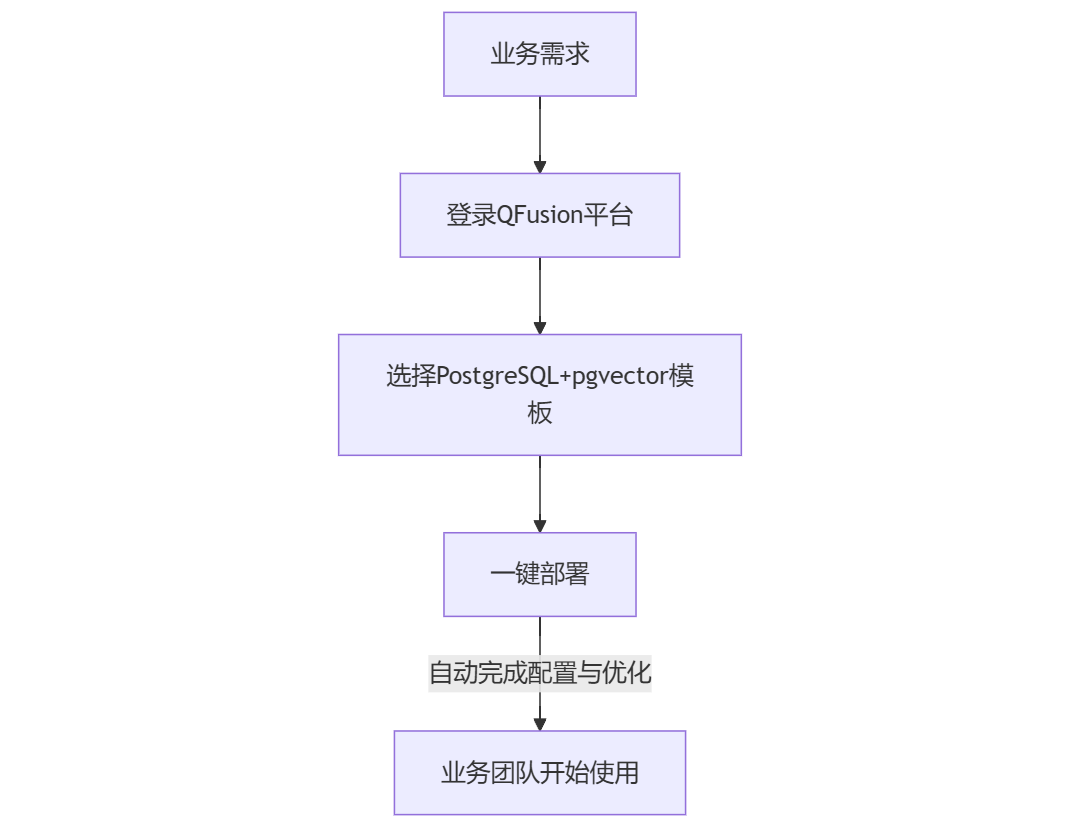
但在QFusion管控下,企业可轻松部署pgvector插件,借助pgvector插件,PostgreSQL可成为RAG系统的高效向量存储引擎,下面是在QFusion管控下的典型应用流程:
QFusion显著简化了数据库的部署、监控、优化与维护流程,特别适合需要同时使用多种数据库技术的RAG系统,同时为企业在RAG数据库管理层面带来更多可能:
动态扩缩容:分布式架构下支持在线扩容存储节点(如elasticsearch动态分片),存储容量与计算资源解耦,按需横向扩展;
混合负载隔离:通过读写分离和资源组配置,隔离备份任务与在线查询的I/O竞争,保障业务连续性;
备份策略自动化:内置策略引擎支持全量/增量/差异备份周期配置,自动清理过期备份文件,根据业务负载预测自动触发扩容或备份任务;
自服务能力:企业用户可按需创建、管理数据库实例,无需依赖人工运维,提高数据库管理效率。
我们可以用一个简单的demo来观察基于PostgreSQL的RAG系统是如何实现向量化的。我们采用 Ollama 提供的 `nomic-embed-text` 模型,将文本数据进行嵌入(embedding)处理,并存储至 PostgresSQL 数据库中。通过 Python 代码,我们自动化解析 Word 文档,抽取关键内容,转换为向量并存储,确保数据处理的高效性和准确性。
import ollama
from docx import Document
import psycopg2
from psycopg2 import sql
def extract_paragraphs_from_docx(docx_path):
"""提取有效段落列表(过滤空内容)"""
doc = Document(docx_path)
return [para.text.strip() for para in doc.paragraphs if para.text.strip()]
def generate_embedding(text):
"""生成段落向量"""
return ollama.embeddings(model="nomic-embed-text", prompt=text)["embedding"]
def batch_insert_paragraphs(paragraphs, db_config):
"""批量插入段落数据"""
conn = psycopg2.connect(**db_config)
cur = conn.cursor()
for para in paragraphs:
emb = generate_embedding(para)
cur.execute(sql.SQL("INSERT INTO documents (content, embedding) VALUES (%s, %s)"), (para, emb))
conn.commit()
cur.close()
conn.close()
在构建本地RAG的过程中,我们还实现了基于 PostgresSQL 向量搜索的高效查询功能。当用户提出问题时,系统会生成对应的语义向量,并在数据库中执行相似性搜索,检索最相关的内容,并以上下文的形式传递给本地部署的DeepSeek-R1模型,回答用户的问题。
import requests
import psycopg2
from psycopg2.extras import execute_values
def get_embedding(prompt):
"""通过Ollama生成文本嵌入"""
try:
response = requests.post(
"http://localhost:11434/api/embeddings",
json={
"model": "nomic-embed-text:latest",
"prompt": prompt
}
)
return response.json()['embedding']
except Exception as e:
print(f"嵌入生成失败: {str(e)}")
return None
def search_documents(embedding, top_k=5):
"""在PG中执行相似性搜索"""
try:
conn = psycopg2.connect(**db_config)
cursor = conn.cursor()
# 使用pgvector的余弦相似度计算
cursor.execute("""
SELECT content
FROM documents
ORDER BY embedding <=> %s::vector
LIMIT %s
""", (embedding, top_k))
results = [row[0] for row in cursor.fetchall()]
return "\n[相关上下文分割线]\n".join(results)
except Exception as e:
print(f"数据库查询失败: {str(e)}")
return ""
finally:
if 'conn' in locals():
conn.close()
def generate_answer(prompt, context):
"""调用本地LLM生成回答"""
try:
augmented_prompt = f"""基于以下上下文:
{context}
请以专业严谨的语气回答这个问题:
{prompt}"""
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": "deepseek-r1:latest",
"prompt": augmented_prompt,
"stream": False,
"options": {
"temperature": 0.3,
"top_p": 0.9
}
}
)
return response.json()['response']
except Exception as e:
return f"生成失败: {str(e)}"
if __name__ == "__main__":
db_config = {
"dbname": "example_demo",
"user": "example_user",
"password": "password",
"host": "localhost",
"port": 80
}
user_prompt = input("请输入您的问题:")
# 流程控制
embedding = get_embedding(user_prompt)
if embedding:
context = search_documents(embedding)
print("\n" + "="*50 + "\n生成回答中...\n" + "="*50)
print(generate_answer(user_prompt, context))
else:
print("无法生成文本嵌入")
在进行上述demo的搭建后,我们可以用一个简单的问题来实验下效果,当我们输入「QFusion平台有什么特性」后,系统在思考后返回了如下内容:

上述demo只是一个很简单的示例,演示如何基于沃趣QFusion实现用自有向量数据库构建企业私有化RAG系统。当然,除了PostgreSQL外,企业还可以选择其他向量数据库来构建RAG系统。
QFusion不仅解决了PostgreSQL向量数据库的管理挑战,其基于K8s的架构同样适用于管理其他类型的数据库,包括Elasticsearch、OceanBase、MongoDB等。这种统一管控能力为企业提供了更大的技术选择灵活性。
随着AGI技术不断向前,RAG已经成为了越来越多企业将业务与大模型结合的利器,在这样的背景下,底层数据库的管理与优化已成为关键挑战。
沃趣QFusion数据库私有云RDS作为基于K8s架构的统一数据库管控平台,通过对20+数据库的深度管控能力支持,无论企业选择何种数据库技术路线,QFusion都能提供一致的自服务能力、弹性扩展和高可用保障,帮助企业快速构建高性能、可靠的大模型数据库基础设施。

延伸阅读:

