





在使用 Doris 过程中,可能会遇到查询报错-230的问题,影响业务的正常运行。别慌!今天,我们将带你一起探索,看看如何快速解决 报错-230,让你的系统重新跑起来!🚀
1. 查询报错-230的常见原因 查询报错-230通常意味着事务在 publish version 这一步卡住,可能是某些线程死掉了、IO瓶颈导致了慢查询,或者事务本身卡死了。问题看似复杂,实际也不简单。但只要我们一步步排查,就能快速找出根本原因。
1
什么情况下会碰到报错-230
1
什么情况下会碰到报错-230
程序 Bug:版本问题会导致 FE 的 publish version 线程卡住。 事务慢:事务没有永久卡死,但因为某些原因,publish version 过程变慢。 业务高频导入:数据写入过快,导致系统负载过高,出现事务堆积。 元数据回滚:执行 metadata_failure_recovery 操作后,导致 FE 和 BE 版本不一致。
你是不是觉得这些原因听起来有挺麻烦?别急,让我们一探究竟!

2. 排查与解决方法
1
版本问题 —— 更新才是王道!
1
版本问题 —— 更新才是王道!
什么情况会出现?
如果你使用的是 Doris 2.1.3 或 2.1.4-rc01/02 版本,程序的 Bug 可能导致 FE 的 publish version 线程挂了。别慌,这个问题会导致大部分事务卡在 commit 状态,处理起来也相对简单。
这时候你可以去fe的日志里面搜一下,如果出现一下的 PublishVersionDaemon.runAfterCatalogReady ... Error ...
就是这个线程挂了~
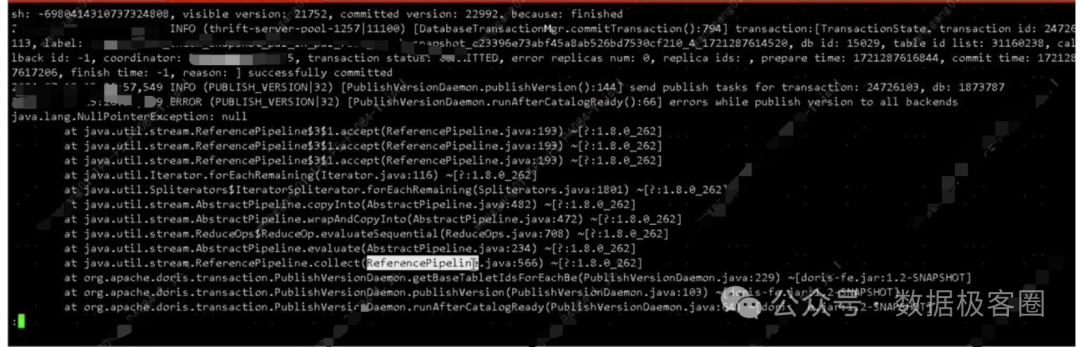
如何解决?
只需要将你的 Doris 升级到 >= 2.1.4-rc03 版本,问题就能迎刃而解!别忘了,及时更新版本,有些bug在3位数小版本都已经fix了!

2
事务卡死或慢 —— 先诊断再治疗
2
事务卡死或慢 —— 先诊断再治疗
当你看到报错-230时,第一个要确认的就是事务是否永久卡死。你可以通过以下命令来查看事务的状态:
//查询报错的tablet
show tablet xxx;
//获取对应的table name和partition name,然后执行下面的sql
show partitions from table_xxx where PartitionName = 'partition_xxx';
//上面sql会打印出partition的visible version
如果 visible version 没有变化,那就可能是卡住了。等一等,如果它恢复了,那就说明没问题。如果长时间(几分钟作为参考)还是没有变化,那事务可能卡死了。来,先冷静排查,再决定下一步行动!
FE publish version 卡慢
如果事务没有卡死,但系统反应慢了,可能是 FE publish version 被拖慢了。检查 FE 的日志,看是否有以下关键字:
DatabaseTransactionMgr.checkAndLogWriteLockDuration
EditLog.logInsertTransactionState
这说明是edit log慢了,一般情况下是fe磁盘忙,可能是高频导入导致写很多edit log, 或者跟be混布be写压力大等等所致。如果是高频导入,直接降导入频率就可以了。如果fe是跟其他进程混布,其他进程写磁盘压力大的,则把混布分开(不推荐FE和BE混部)。
注意⚠️:2.0版本不含这个log信息
如果这时候的io util 比较低,且用户的导入速度低,那就不是磁盘io忙,这时候可能就是由于统计信息会写很多edit log,可能导致edit log慢了。这个已经修复了,推荐升级2.0和2.1的最新版本,还是那句话呀,稳住,别用太久远的版本,有些bug已经fix了
3
事务永久卡死 —— 找出根因
=> running,按commitTime 进行升序排列,看下最早的事务是不是卡死了。如果有很多commitTime 为空的,那按第一列的TransactionId 升序排列也可以,看下它是不是很早的事务了( commit time都可以)。
3
事务永久卡死 —— 找出根因

如果事务的时间commitTime很早,说明可能是卡死了,先把上面这个面板拖到最右边, 拿到它们的ErrMsg。
解决方案
需要根据ErrMsg具体评估如何修复
2.0.3 版本之后事物卡死的情况很少很少见了。
4
高频导入问题 —— 减速带停一停
4
高频导入问题 —— 减速带停一停
当你发现事务提交太频繁,可能是业务数据导入过快,导致Doris处理不过来。可以通过查看 FE 日志中事务提交频率来诊断:
//这里时间XXX要用具体某分钟的时间代替,例如,当天是12月31日10点多,那么可以搜: "12-31 10:01"。
grep "beginTransaction" fe.log | grep 时间XXX | wc -l
通过上面的方法,可以查看一分钟有多少个事务,如果频率太高,那就需要减速了!
解决方案
可以让业务数据攥批再写,以降低写的频次。例如,业务常出现直接insert into 单条记录,可以业务写入到文件里,再定期用stream load导入。这样就能有效降低导入频率,减轻Doris的压力。
5
元数据回滚 —— 别玩儿虚的!
5
元数据回滚 —— 别玩儿虚的!

解决方案
禁止用户使用 metadata_failure_recovery,如果已经执行了,需要通过向 partition 写入数据来恢复。
可以show tablet xxx => detail cmd => 查看各个副本的version,
接着 SHOW PARTITIONS FROM table_name WHERE PartitionName = "p1" 查看partition的visible version。
如果所有副本的version 都大于 partition 的visible version, 那么可以进行修复
(1)往该partition写入一条数据,看下partition visible version 有没有增加,如果有增加,那就继续一直写,直到 partition.visible_version = 副本的version;
(2)如果这种方法不行,那就只能通过truncate partition重导数据的方式了。
6
Backup/Restore —— 不要成为障碍!
6
Backup/Restore —— 不要成为障碍!
这主要是因为事务不卡死, 但是事务涉及的tablet 在BE 端 partition id 跟 FE 端partition id 不一样,导致尽管BE 端publish txn成功了, 但是BE 端汇报fe时,成功的tablet 数会变少,从而fe 端事务从commit 到 visible 大概会花费一分钟(BE report tablet 的周期是一分钟)。
比如,下图这个事务有4个tablet 是publish 成功的(publish version successully on tablet, ...),但是这个事务向fe汇报时只有一个tablet 成功(最后一行日志中successfully publish version ... |ttablets_num=1)。这里4 个publish txn, 但只汇报一个tablet,就是因为有3个tablet,它们在be端的partition id 是错误的,跟fe上的partition id 没对上。

确认fe 端 和 be 端的tablet 的partition id 不一样。可以通过以下方法:
show tablet xxxx => 这里面会拿到fe 端的partition id。 接着执行上面show tablet xxx => detail command => 出来每个副本的情况

curl 每个副本的meta url, 这个出来的结果会拿到tablet 在BE 端的partition id。

可以看到, 同一个tablet,在fe端和be端的parition id 不一样(677627 vs 21675709)
解决方案
确认是否使用了 backup/restore,如果是,检查 BE 和 FE 之间的版本是否匹配。通过调整副本的 partition id 来修复。
可以使用如下方式来修复:
truncate 表或者partition,然后重导数据;
或者使用下面的方式
判断BE 端的parttiion id
(1) 如果BE 端的 partition id = 0, 已经修复,可升级大于2.0.13/2.1.1的版本(升级~);
(2) 如果 BE 端的partition id != 0 (目前已知backup/restore 会引入这个BUG, 导致BE端的partition id 是一个很大的数且跟fe的不一样), 那么需要对出问题的副本挨个执行一下(如果嫌人工挨个检查tablet麻烦, 可以对该partition下的所有副本都执行也是安全的):
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "XXX", "backend_id" = "XXX", "status" = "drop");
执行上面的命令之后, 出问题的副本会下掉,并且添加新副本进来,新进来的副本的partition id 会是正确的。
三. 总结与建议
查询报错-230虽然看起来令人头痛,但通过一步步的排查和优化,我们完全能够找到解决办法。记住,及时升级版本,避免高频导入,才能让 Doris 更稳定的运行,远离报错的困扰!
希望这篇文章能够帮助你解决 Doris 查询报错-230的问题!如果问题依然存在,莫慌,Doris官方社区来兜底!💪
完
Apache Doris社区是目前国内最活跃的开源社区(之一)。Apache Doris(Apache 顶级项目) 聚集了世界全国各地的用户与开发人员,致力于打造一个内容完整、持续成长的互联网开发者学习生态圈!
如果您对Apache Doris感兴趣,可以通过以下入口访问官方网站、社区论坛、GitHub和dev邮件组:
PowerData是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的数据开源社区。
社区群内会定期组织模拟面试、线上分享、行业研讨、线下Meetup、城市聚会、求职内推等活动,同时在社区群内你可以进行技术讨论、问题请教,结识更多志同道合的数据朋友。
社区整理了一份每日一题汇总及社区分享PPT,内容涵盖大数据组件、编程语言、数据结构与算法、企业真实面试题等各个领域,帮助您提升自我,成功上岸。
可以加作者微信直接进去PowrData官方社区群
叮咚✨ “数据极客圈” 向你敞开大门,走对圈子跟对人,行业大咖 “唠” 数据,实用锦囊天天有,就缺你咯!快快关注数据极客圈,共同成长!

点击上方公众号关注我们

