





在 Doris 的分布式架构里,数据划分策略是实现高效存储和查询的关键所在。它主要依靠分区(Partition)和分桶(Bucket)这两层逻辑划分,对数据的分布进行精细化管理。本文将深入探讨这两种策略的设计思路、实际应用场景以及常见问题的解决办法。

一、分区策略:数据管理的逻辑基石
1. 分区的类型
Range 分区:按照指定列的数值范围对数据进行划分,比较适合时间序列数据或者连续数值型数据的场景。例如,我们可以按月对数据进行分区,像 202501、202502 这样的分区设置。
List 分区:依据列的具体值来分配数据,这种方式更适用于离散值的场景,比如根据省份或者城市来进行分区。
2. 分区的模式
手动分区:用户可以通过ALTER
语句来灵活地创建或者调整分区,这种模式在数据管理方面具有很强的可控性。
动态分区:系统会根据预先设定的时间规则自动生成新的分区,不过需要用户提前定义好分区的范围。
自动分区:当数据写入时,系统会自动创建对应的分区,但这种模式需要用户对分区的数量进行严格监控,以防止出现脏数据的问题。
3. 分区的优势
提升查询性能:在查询过程中,系统可以通过分区裁剪快速过滤掉无关的数据,从而减少 I/O 的开销。
简化数据管理:用户能够针对不同的分区进行独立操作,比如删除旧数据或者进行冷热分层存储等。
二、分桶策略:数据分布的物理优化
1. 分桶的方式
Hash 分桶:系统会对分桶列的值计算哈希值,然后根据分桶数量取模,将数据均匀地分布到各个分片中。这种方式适用于 JOIN 或者聚合查询的场景。
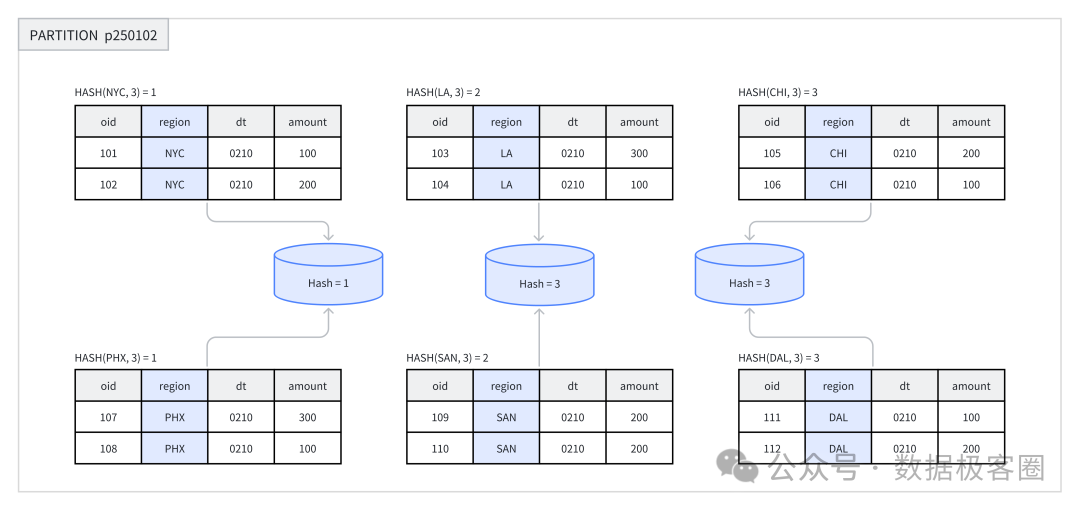 推荐在以下场景中使用 Hash 分桶:
推荐在以下场景中使用 Hash 分桶:
业务需求频繁基于某个字段进行过滤时,可将该字段作为分桶键,利用 Hash 分桶提高查询效率。 当表中的数据分布较为均匀时,Hash 分桶同样是一种有效的选择。
Random 分桶:数据会被随机分配到不同的分片中,当处理小规模数据时,可以使用load_to_single_tablet
参数来优化写入速度。
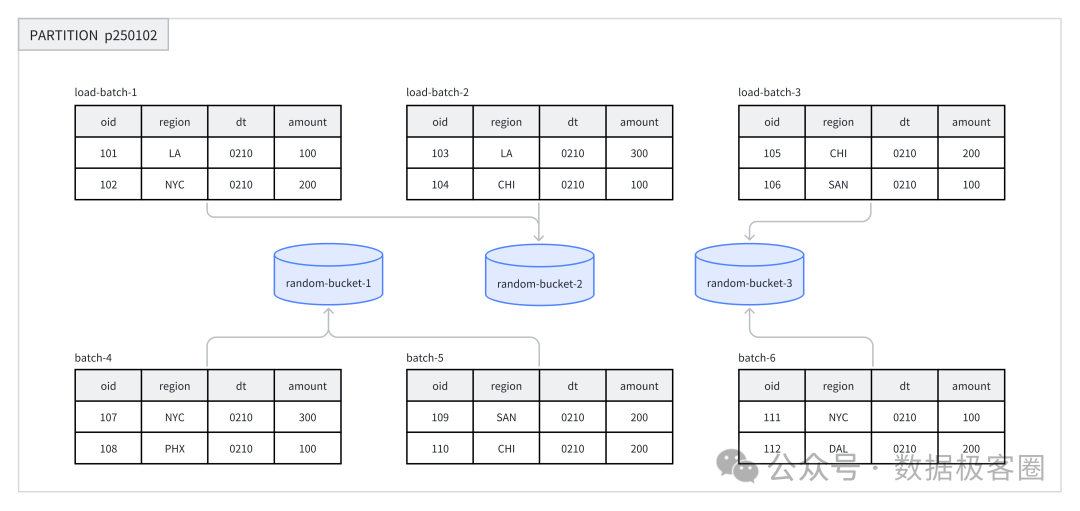 在以下场景中,建议使用 Random 分桶:
在以下场景中,建议使用 Random 分桶:
在任意维度分析的场景中,业务没有特别针对某一列频繁进行过滤或关联查询时,可以选择 Random 分桶; 当经常查询的列或组合列数据分布极其不均匀时,使用 Random 分桶可以避免数据倾斜。 Random 分桶无法根据分桶键进行剪裁,会扫描命中分区的所有数据,不建议在点查场景下使用; 只有 DUPLICATE 表可以使用 Random 分区,UNIQUE 与 AGGREGATE 表无法使用 Random 分桶;
2. 分桶的作用
避免数据倾斜:Hash 分桶能够让数据在物理存储上更加均匀,从而减少热点问题的出现。
增强查询并行度:合理设置分桶数量可以充分利用计算资源,提升查询的并发处理能力。
优化 Colocate Join:如果多个表采用相同的分桶键和分桶数量,那么在进行 JOIN 操作时,可以减少跨节点的数据传输。
三、常见问题及应对策略
1. 数据倾斜问题
当数据分布不均匀时,会导致某些分片的负载过高。可以通过以下方法来解决:
优先选择高基数的列作为分桶键。 适当增加分桶的数量,例如将分桶数设置为 128 个(单个tablet的数据量推荐1-10GB)。 对倾斜的字段进行预处理,比如添加随机前缀。
2. 分片数量过多问题
分片数量过多会增加元数据的管理负担。可以采取以下措施:
控制每个 BE 节点承载的分片数量不超过 2 万个。 对于冷数据,合并小分片。 避免使用过度细化的分区策略。
3. 冷热数据管理问题
可以将热数据存储在 SSD 上,冷数据存储在 HDD 上。
定期删除或者归档历史分区,例如按天删除 30 天前的数据。
利用 TTL(生存时间)策略来自动清理过期的数据。
4. JOIN 性能优化问题
启用 Colocate Join 功能,确保关联表的分桶键和分桶数量一致。
对于小表,可以采用广播 JOIN 的方式。
避免在倾斜的键上进行 JOIN 操作。
四、最佳实践建议
分区策略选择:如果查询条件中包含时间或者地域等范围条件,优先选择 Range 分区;如果需要对离散值进行管理,则优先选择 List 分区。
分桶数量设置:分桶数量建议设置在 32 到 128 之间,并且要根据集群的规模进行动态调整。
数据分布验证:可以通过SHOW REPLICA DISTRIBUTION
命令来检查数据的分布是否均匀。
写入优化:在写入数据时,尽量控制单次写入的分区数量,避免同时写入过多的分区。
通过合理地设计分区和分桶策略,Doris 能够充分发挥分布式架构的性能优势,满足大规模数据分析的需求。在实际应用中,需要根据业务场景的特点,平衡好查询效率、存储成本和管理复杂度之间的关系。
往期推荐
完
Apache Doris社区是目前国内最活跃的开源社区(之一)。Apache Doris(Apache 顶级项目) 聚集了世界全国各地的用户与开发人员,致力于打造一个内容完整、持续成长的互联网开发者学习生态圈!
如果您对Apache Doris感兴趣,可以通过以下入口访问官方网站、社区论坛、GitHub和dev邮件组:
PowerData是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的数据开源社区。
社区群内会定期组织模拟面试、线上分享、行业研讨、线下Meetup、城市聚会、求职内推等活动,同时在社区群内你可以进行技术讨论、问题请教,结识更多志同道合的数据朋友。
社区整理了一份每日一题汇总及社区分享PPT,内容涵盖大数据组件、编程语言、数据结构与算法、企业真实面试题等各个领域,帮助您提升自我,成功上岸。
可以加作者微信(Faith_xzc)直接进PowrData官方社区群
叮咚✨ “数据极客圈” 向你敞开大门,走对圈子跟对人,行业大咖 “唠” 数据,实用锦囊天天有,就缺你咯!快快关注数据极客圈,共同成长!

点击上方公众号关注我们
