




“ 这是尼萌工作室的第【10】篇文章。本文正文1359字,阅读完成约5分钟。”
每个业务系统有其特殊性,推荐系统的数据采集方案依赖于业务数据,我们需要根据具体的业务场景适当裁剪,设计合理的数据采集方案。
巧妇难为无米之炊。garbage in garbage out,数据是算法基石。 在App应用商店推荐系统中,数据分为基础业务数据,埋点日志数据和第三方数据。
基础业务数据容易理解,包括用户,物料App数据。
埋点日志数据根据来源分为客户端埋点和后端埋点。
第三方数据如用户画像可以作为数据的补充。
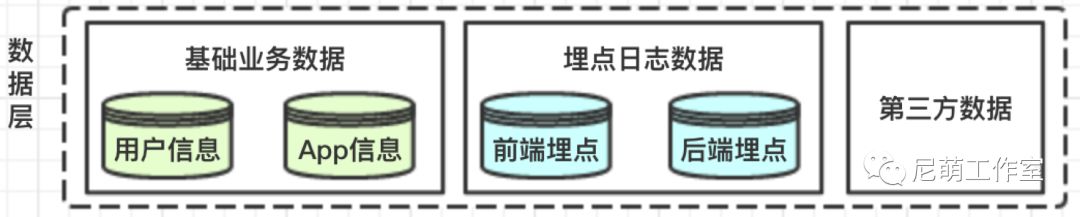
图1. 算法数据分类示意图
因此不同的数据来源我们采取特定的数据采集方案。
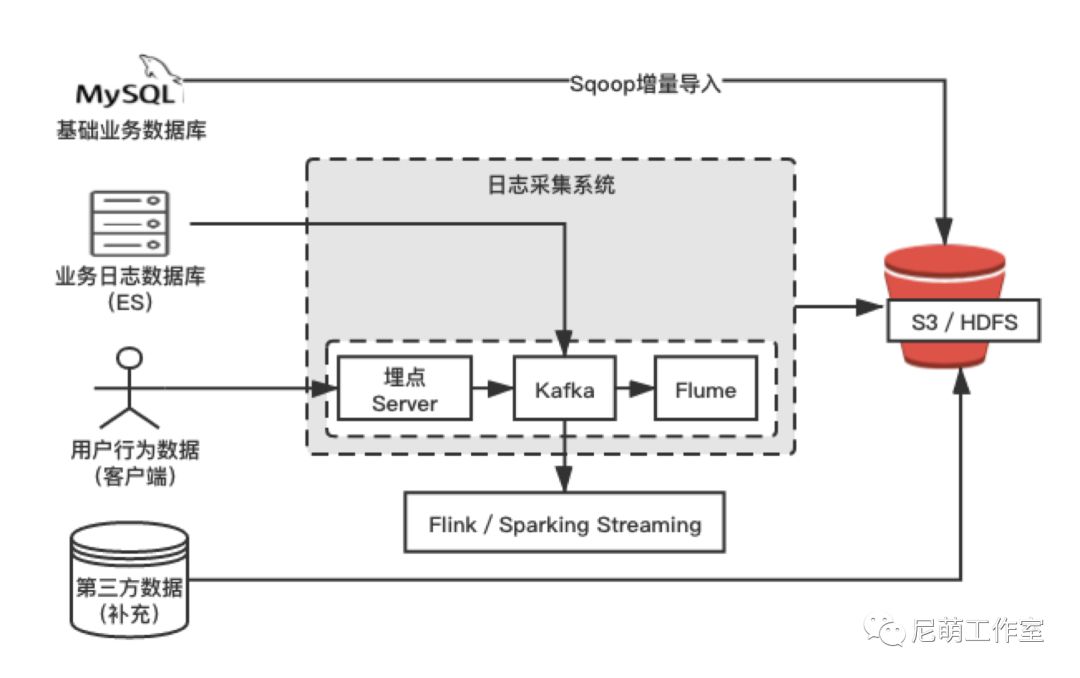
图2. 数据采集方案图
01 基础业务数据
—
基础业务数据一般存放业务系统的关系型数据库(如MySql)中,主要包括用户的数据, App的数据等基础信息。
用户基础数据:用户id,姓名,出生日期,性别,邮箱,电话,国家,省市区,设备移动识别码,网络码,手机品牌型号,激活时间。
App基础数据:Appid,App名字,版本号,内容,安装包,安装包大小,是否收费,所属专题,目录(可分多级),标签,国家,语言,上下架时间,更新时间。
特别注意的是推荐系统本质锦上添花。在生产环境中,为了防止主库被Sqoop抽崩,避免直接连接业务数据库,我们从备库同步一份数据到集群中方便进行数据分析操作,防止对业务造成干扰。
保证实时推荐效果,满足小时级别同步的要求。采用Sqoop工具对基础业务数据进行增量同步。👉可参阅《大数据组件之Sqoop》
根据业务场景,我们采用 lastmodified模式的增量导入方式。
一般Mysql数据库中更新数据会同时修改update_time字段 , 我们选择update_time或其他时间字段,按照用户id/Appid合并避免导入重复的数据。
--incemental lastmodified--check-column update_time--merge-key id--last-value '2020-01-01 10:00:00'
如何设置并发导入参数?
我们知道通过 -m 参数能够设置导入数据的 map 任务数量,即指定了 -m 即表示导入方式为并发导入,这时我们必须同时设置 --split-by 参数指定根据哪一列来实现哈希分片,从而将不同分片的数据分发到不同 map 任务上去跑,避免数据倾斜。
02 埋点日志数据
—
埋点日志是应用中特定的流程收集一些信息,用来跟踪应用使用的状况,后续用来进一步优化产品或是提供运营的数据支撑。
埋点数据对推荐系统十分重要,模型训练和效果数据统计都基于埋点数据,需保证埋点数据的正确无误。
一般用户有很多日志,当前推荐场景统一到用户行为日志中,还有其它业务场景如(下发日志、支付日志) 。
客户端埋点日志
用户在客户端对每一个APP行为可分为曝光,点击,下载,安装,分享,评分/论等。
而用户的搜索行为,需要采集搜索词,搜索结果点击,搜索结果下载等信息,适用于搜索热词推荐 ,搜索热门推荐,搜索无结果时App列表推荐等推荐场景。
关于数据采集和埋点,神策有一套成熟的解决方案,可参阅文末的链接。
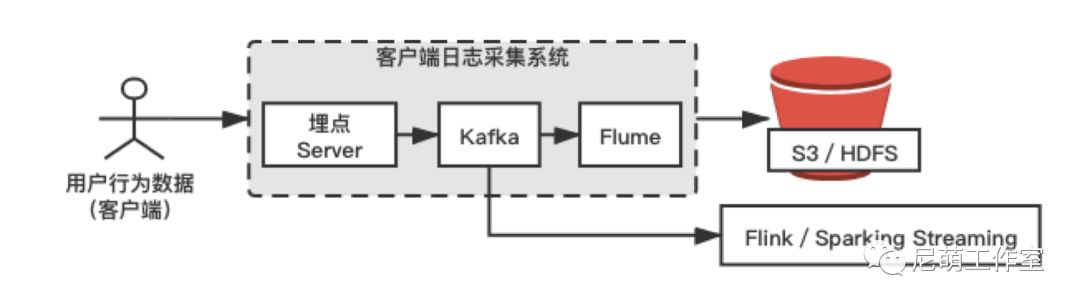
图3. 客户端埋点日志数据采集方案图
服务端埋点日志
服务端日志根据业务场景而定,常见的有请求,响应日志,下发日志,支付日志,分享链接点击进入,广告投放等。一般存放在业务的 ES。
同样的,服务端日志数据抽取需要保证业务正常,我们可选取必要的日志推送至Kafka, 用来补充做离线画像或者实时计算。
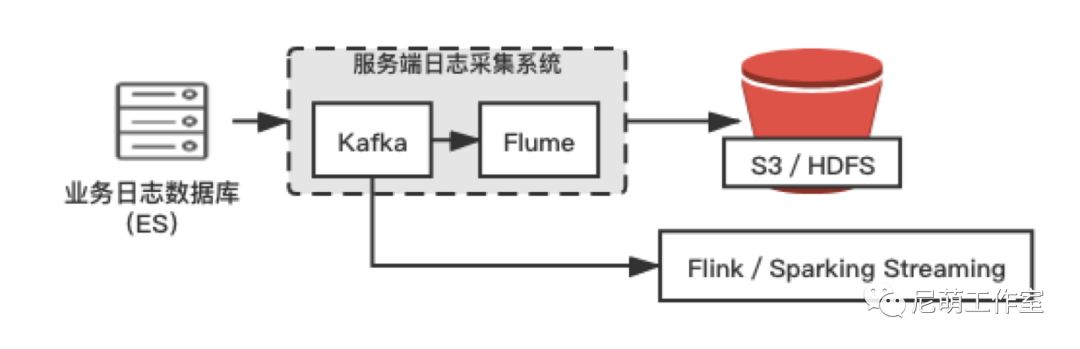
图4. 服务端埋点日志数据采集方案图
03 第三方数据
—
第三方数据可用作用户画像的补充,要注意探测和本业务的用户重合率,否则事倍功半。
reference
神策数据采集与埋点 https://www.sensorsdata.cn/blog/shu-ju-jie-ru-yu-mai-dian/
- END -

谁怕,一蓑烟雨任平生
