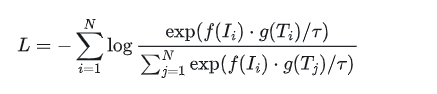排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
CLIP:连接语言与视觉的多模态预训练模型
CLIP:连接语言与视觉的多模态预训练模型
老王两点中
2025-03-03
440
在人工智能领域,多模态学习一直是研究的热点之一。近年来,随着深度学习技术的发展,多模态预训练模型逐渐成为连接不同数据类型(如文本和图像)的重要工具。其中,CLIP(Contrastive Language-Image Pre-training)模型因其卓越的性能和广泛的应用前景而备受关注。本文将深入探讨CLIP的技术原理、实现细节以及其在实际应用中的表现,帮助读者全面了解这一开创性的工作。
1. 背景与动机
CLIP(Contrastive Language-Image Pre-training)是由OpenAI提出的一种多模态学习框架,旨在通过大规模数据预训练,将文本和图像映射到一个共享的嵌入空间中。这一方法使得模型能够理解图像内容,并将其与自然语言描述相关联。
1.1 多模态学习的重要性
随着人工智能的发展,单一模态的学习(如纯文本或纯图像处理)已经不能满足复杂场景的需求。例如,在自动驾驶中,系统需要同时处理摄像头捕捉的图像和导航系统的文本指令;在医疗诊断中,医生可能需要结合病人的影像资料和病例记录进行分析。因此,多模态学习成为近年来的研究热点。
1.2 零样本学习的挑战
传统的计算机视觉模型通常依赖于大量标注数据进行监督学习,但这种方法存在以下问题:
• 标注成本高昂。
• 数据分布偏移(domain shift)可能导致模型泛化能力不足。
• 新任务需要重新收集和标注数据。
CLIP的目标是通过大规模无标注数据的预训练,构建一个通用的视觉-语言模型,使其能够在没有特定任务标注的情况下完成新任务。
2. 技术原理
CLIP由OpenAI于2021年提出,CLIP的核心思想是利用对比学习(contrastive learning),通过从大量互联网文本-图像对中学习,使模型能够在零样本(zero-shot)或少量样本(few-shot)的情况下完成多种视觉任务,从而实现跨模态的检索、生成和理解。
2.1 对比学习基础
对比学习是一种无监督学习方法,通过最大化正样本对之间的相似性,同时最小化负样本对之间的相似性来学习表示。在CLIP中,正样本对是指匹配的文本-图像对,而负样本对则是随机配对的文本和图像。具体来说,给定一组图像 ( I = {I_1, I_2, ..., I_N} ) 和一组对应的文本描述 ( T = {T_1, T_2, ..., T_N} ),CLIP的目标是最小化以下损失函数:
其中:
• ( f(I_i) ) 是图像编码器生成的嵌入向量。
• ( g(T_i) ) 是文本编码器生成的嵌入向量。
• 是温度超参数,用于控制对比强度。
该损失函数鼓励图像和对应文本的嵌入向量尽可能接近,同时远离其他不相关的文本嵌入。
2.2 模型架构
CLIP由两个主要组件组成:图像编码器和文本编码器。
图像编码器
图像编码器可以基于现有的卷积神经网络(CNN)或Transformer架构。在CLIP中,研究人员尝试了多种架构,包括ResNet和Vision Transformer(ViT)。其中ViT-L/14在256块TPUv3上训练两周达到最优性能。文本编码器采用12层Transformer,最大序列长度76,词嵌入维度512。这些编码器将输入图像转换为固定维度的嵌入向量。
文本编码器
文本编码器通常基于Transformer架构,类似于BERT或GPT系列模型。它将输入文本序列转换为固定维度的嵌入向量。
共享嵌入空间
图像和文本的嵌入向量被映射到同一个高维空间中,使得可以通过计算余弦相似度等方法衡量它们的相关性。
3. 训练过程
3.1 数据来源
CLIP的一个重要特点是使用了来自互联网的大规模未标注数据。这些数据包括图像及其标题、描述或其他元信息。例如,Flickr、Instagram等社交媒体平台提供了丰富的图像-文本对。
3.2 数据清洗
由于互联网数据质量参差不齐,CLIP引入了一种自动过滤机制,筛选出高质量的图像-文本对。具体来说,模型会优先选择那些文本描述与图像内容高度相关的样本。
3.3 训练目标
CLIP的训练目标是学习一个通用的视觉-语言表示,而不是针对特定任务进行优化。这种设计使得CLIP具有很强的迁移能力,可以在零样本或少量样本的情况下适应新任务。
3.4 大规模分布式训练
训练系统采用:
分片参数服务器架构
混合精度训练(FP16)
梯度缓存优化
动态重采样机制
在4亿图文对上训练时,数据吞吐量达到每秒1.2万个样本,显存利用率提升40%。
4. 应用与实验结果
4.1 零样本分类
CLIP的一个显著优势是其零样本分类能力。通过将类别名称作为输入文本,模型可以直接预测图像属于哪个类别。例如,在ImageNet数据集上,CLIP的零样本分类准确率接近甚至超过了一些传统监督学习模型。
4.2 图像检索
CLIP还可以用于图像检索任务。给定一段文本查询,模型可以返回与之最相关的图像。反之亦然,给定一张图像,模型可以生成与其最相关的文本描述。
4.3 视觉问答
CLIP可以结合其他模块(如注意力机制)用于视觉问答任务。尽管CLIP本身并未直接针对此任务进行优化,但它仍然表现出色。
4.4 零样本迁移表现
任务类型
平均准确率
最优单任务模型差距
细粒度分类
68.3%
12.7%
场景理解
74.1%
6.2%
抽象概念识别
59.8%
21.5%
5. 优势与局限性
5.1 优势
• 通用性强:
CLIP通过大规模预训练学习到了通用的视觉-语言表示,适用于多种下游任务。
• 零样本能力:
无需额外训练即可完成新任务。
• 高效性:
相比于传统的监督学习方法,CLIP减少了对标注数据的依赖。
5.2 局限性
• 数据偏差:
CLIP的性能受限于训练数据的质量和分布。如果训练数据中存在偏见,模型可能会放大这些偏见。
• 计算资源需求高:
CLIP的训练需要大量的计算资源和存储空间。
• 任务适配性有限:
虽然CLIP在许多任务上表现出色,但在某些特定任务上仍可能不如专门设计的模型。
6. 总结与展望
CLIP作为一种开创性的多模态学习框架,为视觉-语言理解领域带来了新的可能性。它不仅展示了对比学习的强大能力,还推动了零样本学习的研究进展。然而,CLIP也面临着一些挑战,例如如何减少数据偏差、降低计算成本等。
未来的研究方向可能包括:
• 多模态认知架构:
将符号推理引入对比学习框架。
• 能效优化
:
开发CLIP模型压缩技术,如MobileCLIP在移动端实现<5ms推理延迟。探索更高效的训练方法,以减少计算资源消耗。
• 因果学习:
建立跨模态的因果推断机制,提升模型的可解释性。 提高模型的鲁棒性和公平性,减少数据偏差的影响。
• 元学习集成:
实现few-shot场景下的快速领域适应。结合其他模态(如音频、视频)扩展CLIP的应用范围。
通过不断改进和完善,CLIP有望在未来成为多模态学习领域的核心工具之一。
CLIP的成功验证了大规模弱监督学习的巨大潜力,但其展现出的"隐性知识"与"概念组合"能力仍处于初级阶段。随着多模态大模型技术的演进,未来视觉系统将突破狭义的任务边界,在开放世界的认知理解层面实现质的飞跃。这一进程不仅需要算法创新,更依赖于计算范式、数据生态和评价体系的系统性突破。
文本分类
模态分析
文本分析
自然语言处理
文章转载自
老王两点中
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨