




dirsearch的问题
在一些存在默认页面的网站,dirsearch会扫出来大量无效地址,会导致输出的结果非常大,如果批量扫描大量网站时,不但会占用大量磁盘空间,而且在查看结果时也会造成大量干扰。
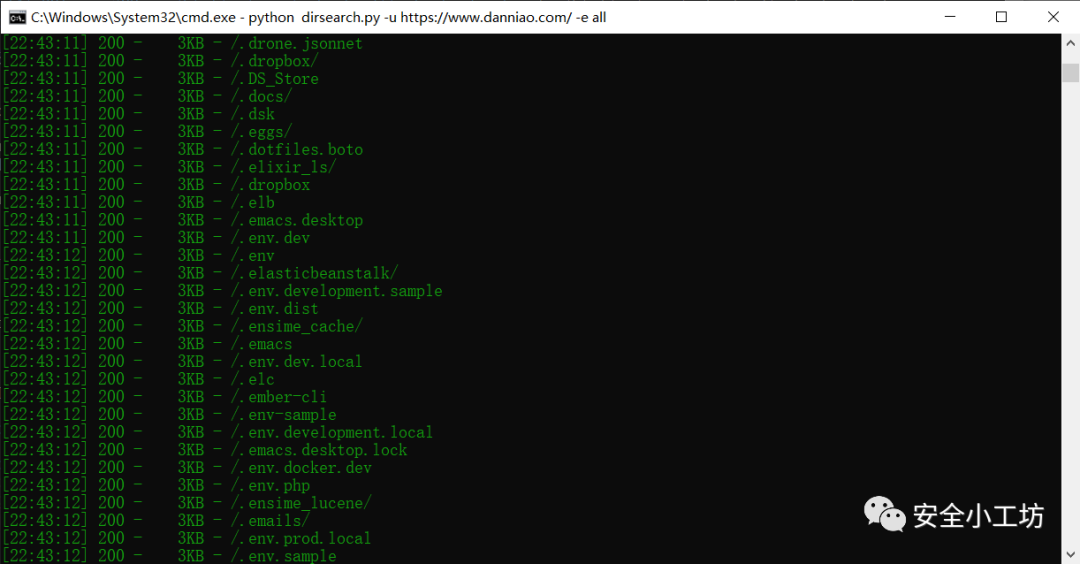
dirsearch扫描部分结果如下:
改造
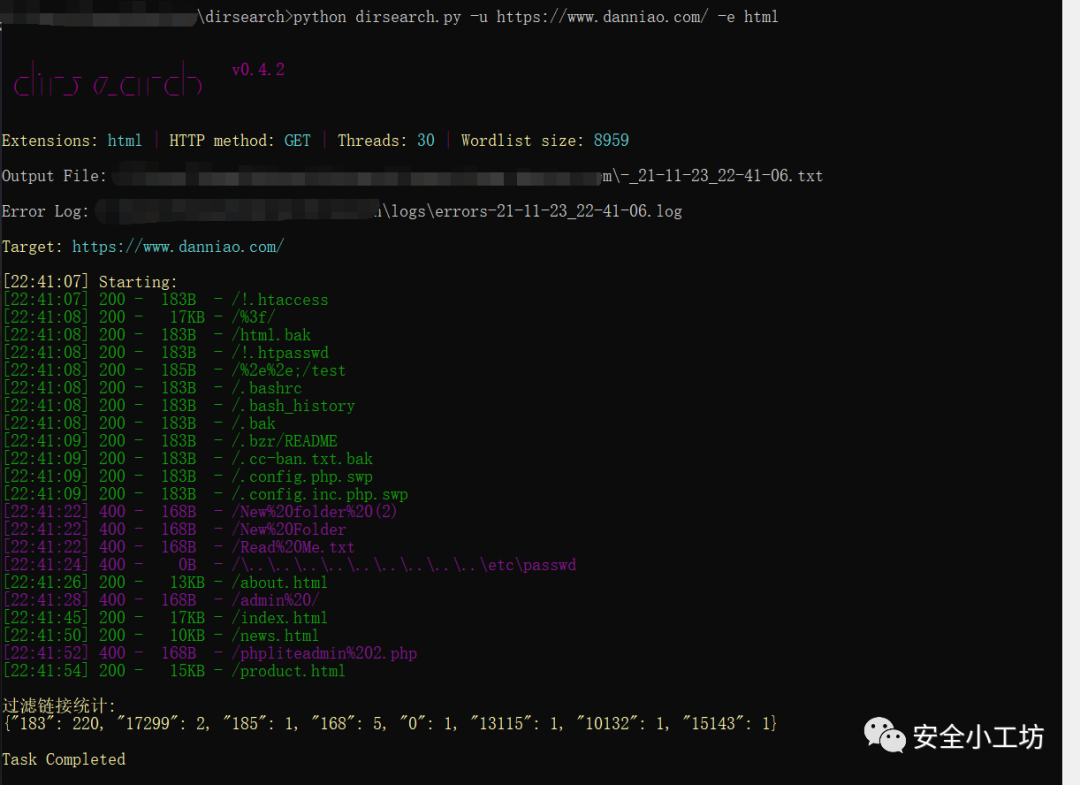
根据上面结果可以发现,扫描出来的页面长度是都是一样的,所以可以将这个作为判断条件进行自动过滤。
在dirsearch扫描到该路径时,标记当前页面的页面长度并计数,当该长度超过一定阈值时,再次扫描出来该长度的路径时直接忽略。
分析代码,保存结果的主要就是controller.py
中的match_callback
函数,修改后代码如下:
# Callback for found pathsdef match_callback(self, path):self.index += 1for status in self.arguments.skip_on_status:if path.status == status:self.status_skip = statusreturnif not self.valid(path):del pathreturnfuzz_length = int(path.length / 10 * 10) # 允许页面长度误差在10以内if fuzz_length not in self.length_counter:self.length_counter[fuzz_length] = 1else:self.length_counter[fuzz_length] += 1if self.length_counter[fuzz_length] > 10: #当统计数量大于10时 跳过该结果returnadded_to_queue = Falseif (any([self.arguments.recursive, self.deep_recursive, self.force_recursive])) and (not self.recursion_status_codes or path.status in self.recursion_status_codes):if path.redirect:added_to_queue = self.add_redirect_directory(path)else:added_to_queue = self.add_directory(path.path)self.output.status_report(path.path, path.response, self.arguments.full_url, added_to_queue)if self.arguments.replay_proxy:self.requester.request(path.path, proxy=self.arguments.replay_proxy)new_path = self.current_directory + path.pathself.report.add_result(new_path, path.status, path.response)self.report_manager.update_report(self.report)del path
改造后的扫描结果如下:
工具获取
关注公众号,回复dirsearch
获取下载链接。
扫描下方二维码
关注我们!

文章转载自安全小工坊,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
