




SELECTpwt.obj_id ......FROMpXXXXX_task pwtINNER JOIN pXXXXcord pr ON pwt.obj_id = pr.patrol_work_task_idWHEREpwt.deleted_state = '0'AND pr.deleted_state = '0'AND pwt.prXXXXXXnd = '01'AND pwt.paXXXXk_state IN ( '02', '04', '05' )AND pwt.coXXXXXr_name LIKE CONCAT ( '%', REPLACE ( REPLACE ( '白新', '%', '/%' ), '_', '/_' ), '%' ) ESCAPE'/'AND pwt.mXXX_crew_id IN ( '8a0f688XXXXXXXXXXXX0f16' )ORDER BY pwt.ctime;
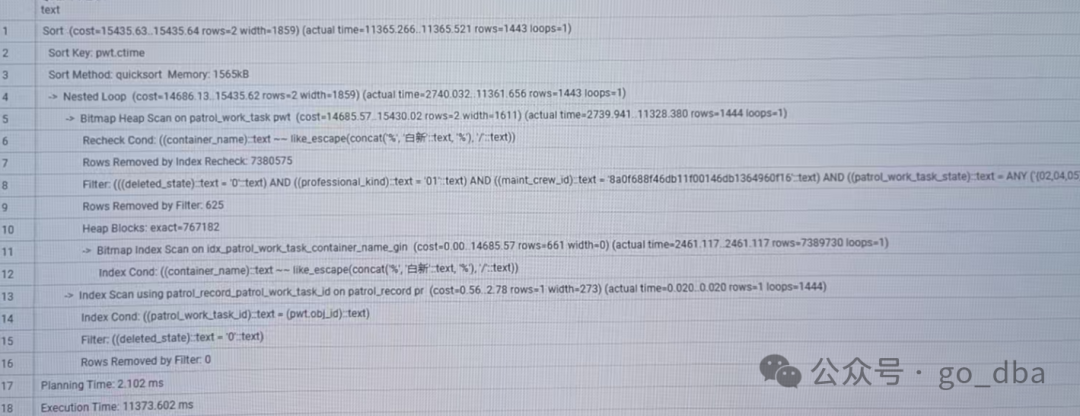 从执行计划中看出 在gin索引过滤 rows估算661条而实际由738W条因此走gin效率非常低整体耗时11S。
从执行计划中看出 在gin索引过滤 rows估算661条而实际由738W条因此走gin效率非常低整体耗时11S。
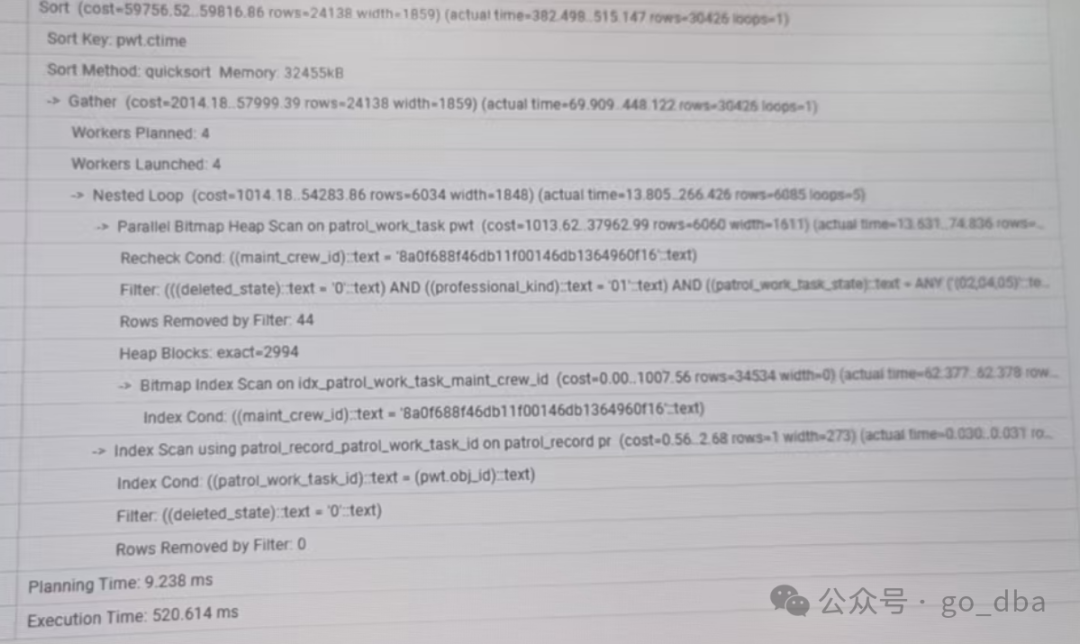
去掉like查询后:520ms
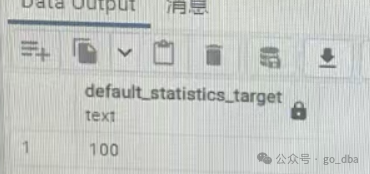
我们知道gin索引缺点就是“短语”检索时候rows估算错误就是缺点之一。 此事调研 show default_statistics_target 发现对于 coXXXXXr_name偏小很多。既然偏小那么通过实验去校正调整。备注:coXXXXXr_name是类似部门名称的业务含义,其数量有限
alter table pXXXXX_task alter column coXXXXXr_name set STATISTICS 2000;ANALYSE pXXXXX_task ( coXXXXXr_name);
调整后的执行计划:3S不到
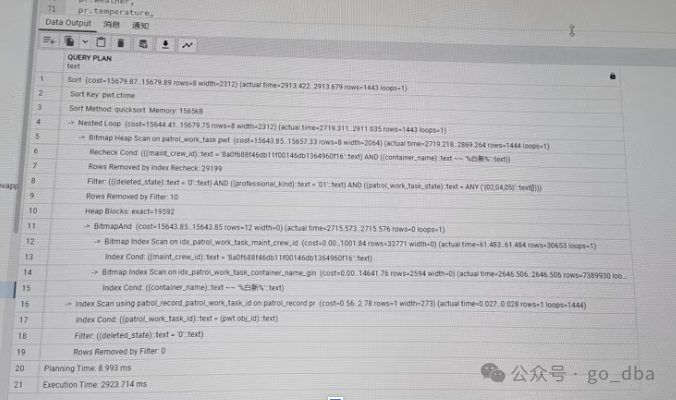
总结:
gin索引对于短语检索 rows估算偏差很大,通过部门name设置STATISTICS是的 rows估算误差偏小一点,但是积极影响到 执行计划选择 mXXX_crew_id的索引,速度提高2倍,但是走了gin索引,并走了索引的位图转换。 此时进一步优化 应该采用 gin索引的组合索引。 估计肯定能将效率能进一步提高, 甚至是500ms左右。
文章转载自godba,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
