




摘要:本文整理自长城汽车云平台研发专家陈玮琦老师在 Flink Forward Asia 2024 闭门会中的分享。内容分为以下三个部分:
- 车联网数据的特征
- 应用场景
- 这些年走过的弯路踩过的坑
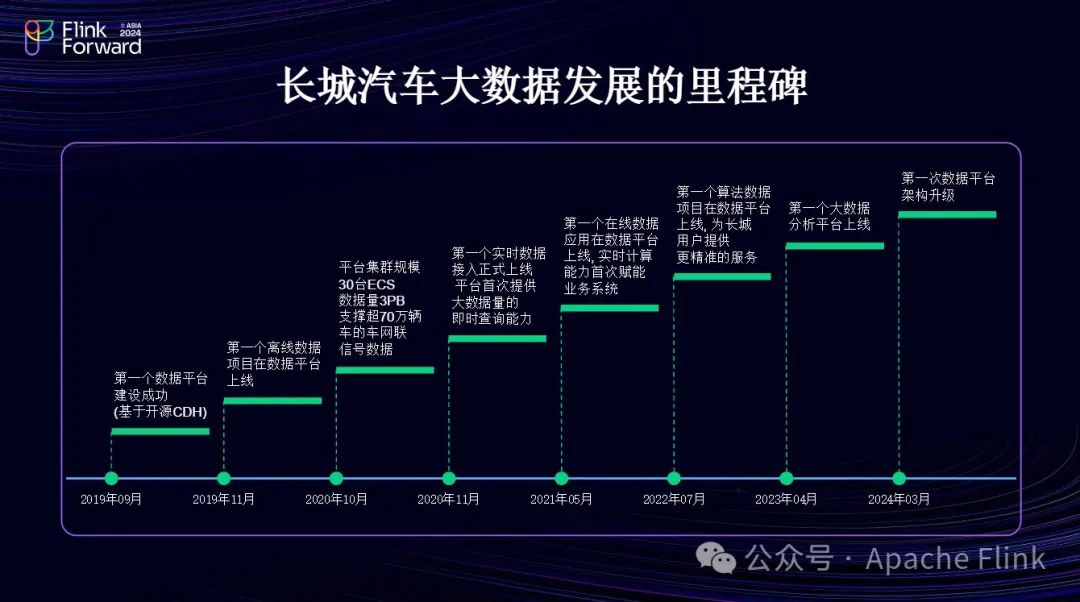
背景与起步(2019年)
长城汽车于2019年开始建立数据平台,使用开源技术组件CDH进行构建。同年,我们运行了第一个离线任务。
车联网数据增长与实时任务启动(2020年)
数据量:到2020年,我们已经搭载了约30万辆车,累积了约3 PB的数据量。
实时任务:启动第一个实时任务,最初使用Spark从Kafka消费原始车况数据,并存储到Hive,同时使用Spark计算引擎处理业务逻辑。
问题显现:随着数据量的增长,发现Spark难以支撑实时应用。
在线数据应用与算法应用场景(2021-2022年)
2021年:开始部署在线数据应用。
2022年:逐步应用了一些算法应用场景。
数据分析平台建设与Flink引入(2023-2024年)
2023年:旨在构建一个数据分析平台,实现闭环。
2024年:现有体系已难以支撑当前业务场景,转而使用Flink处理业务逻辑。
在 Flink 方面,我们积累了一些经验,愿与大家分享。最初我们在处理30万至40万台设备的数据时,能够轻松加载全量数据。但随着数据量的不断增长,这种操作会对 MySQL 造成较大压力,因为早期车辆维度数据都存储在 MySQL 中。因此,我们对此进行了改造:在每个 Flink 算子启动时加载全量数据,然后在数据处理阶段,我们将数据存储在缓存中,在加载过程中还引入了一些算法。起初,我们使用基于 Key by 算子的算法。后来,迭代使用了 CRC 算法,显著减少了每个并行度加载的数据量。通过这些改进,有效地提升了系统的性能和稳定性。
车联网数据的特征

在长城汽车车联网体系中,我们观察到了一些显著的数据特征和面临的挑战:
1. 车辆信号数据量庞大:
每辆车都有超过一千个信号,实际上并未全部采集。如果全部采集,信号数量可能达到五六千个。
由于信号量巨大,选择性采集是必要的,以避免数据处理负担过重。
2. 应用时效性和时序性要求高:
时序性:业务逻辑需要处理信号数据帧间的关联性,确保数据的时间顺序和连续性。
时效性:业务处理过程必须及时响应,确保实时监控和快速决策。
3. 业务关联复杂度较高:
不仅需要关注车况信号,还需与大量业务数据进行关联处理。
例如,在异常发生时,需要考虑天气、海拔等外部因素进行关联分析,以提供更全面的诊断和预警。
4. 硬件设备不统一:
车辆内部的元器件各不相同,且非同一厂商生产,导致每个硬件的适配都不相同。
这种多样性增加了系统集成和维护的复杂性。
5. 信号质量较低:
信号不佳时,上传的数据质量会较差,影响数据的准确性和可靠性。
车辆启动或熄火后,也可能存在信号质量问题,进一步增加了数据处理的难度。

回顾这些数据特征,我们考虑了以下几个关键问题:
1. 如何识别信号?
不同车辆的信号来源和适配各不相同,导致信号识别复杂。我们在信号接入阶段进行了统一梳理,确保信号的一致性和标准化,便于后续处理和分析。
2. 如何存数据?
如果将所有信号直接存储到Hive中,近两年的数据将无法重新计算。目前,车况信号数据按天和车系简单存储在Hive中,但查询单条数据可能需要3到5分钟,无法满足实际应用场景的需求。因此,我们对存储进行了优化,并对信号识别进行了统一梳理,因为不同车辆的信号来源和适配各不相同。我们在信号接入阶段进行了统一梳理。
3. 如何处理数据?
在数据处理方面,我们面临链路问题,即数据如何与数据体系结合。例如,数据打标签后如何回流至实时处理系统进行关联查询,或者在多流 Join 时如何处理等等。
以上这些都是我们在整个过程中的需要考虑的点。
应用场景

基于这些点,我们来探讨长城汽车的应用场景。这些场景虽不是全部,但足以展示 Flink 技术在长城汽车中的起到的作用。
1. 云端异常监控
应用场景:利用Flink进行事件触发,实时监控车辆的异常情况。
具体实现:Flink处理实时数据流,当检测到异常信号时,立即触发警报或通知,确保及时响应和处理。
2. 安全行车监控
应用场景:基于信号进行逻辑触发,将安全事件推送至线索体系。
具体实现:类似于云端异常监控,但具有下推机制。Flink实时处理车辆信号数据,一旦发现安全相关事件(如急刹车、超速等),立即将信息推送至相应的处理系统,确保行车安全。
3. 行程报告生成
应用场景:根据用户的驾驶里程,生成行程报告并推送相关指标。
具体实现:Flink处理用户的实时驾驶数据,生成包含行程距离、速度、时长、油耗等信息的报告。对于新能源车辆,还会包括电耗等信息。这些报告帮助用户更好地了解自己的驾驶习惯和车辆状态。
4. 智能维保
应用场景:分析自上次维保以来的时长、燃油里程,并考虑刹车、空调滤芯等保养项目,通过算法进行智能推送。
具体实现:Flink处理车辆的实时运行数据,结合历史维保记录,分析车辆的使用情况。通过算法计算出需要保养的项目和时间,及时推送维保建议,帮助车主保持车辆的最佳状态。
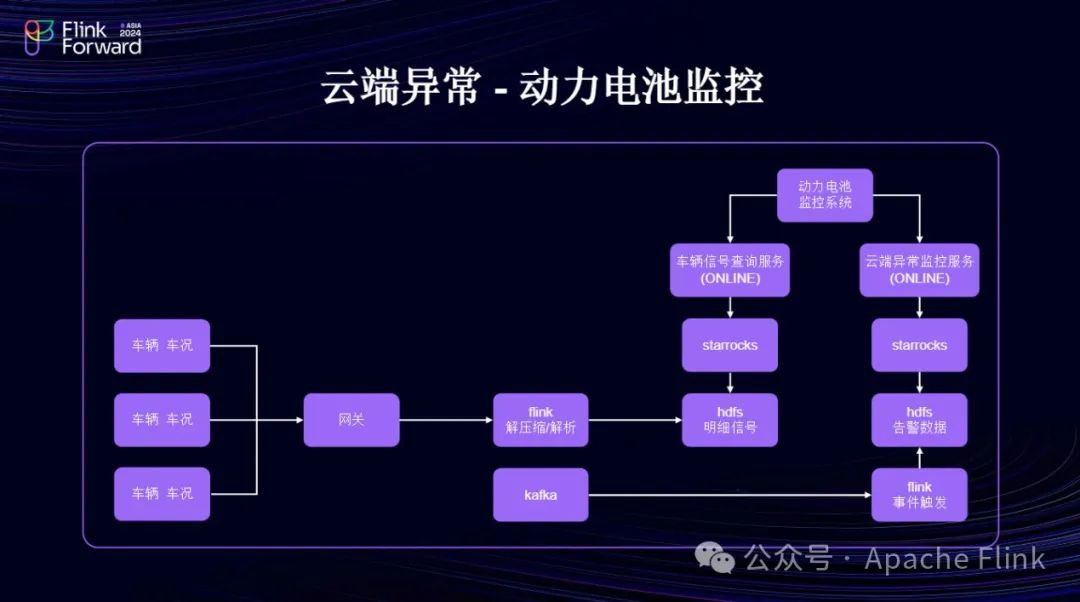
下面,我将重点介绍下在长城汽车车联网体系中,针对云端异常的设计。首先,信号从车辆上传至网关,我们使用 Flink 进行解压缩和解析,解析后的数据存储在 HDFS 中。为了降低成本并提升性能,我们从最初的JSON格式改用Avro序列化。实践证明,这种改变使计算性能提升了50%以上,但这也需要协调上下游的变化。因此,车况信号上报时,我们使用 Map 结构进行上报,解析和解压缩后的数据会被组合成Map结构,便于后续处理。 HDFS 存储时已全部采用 Parquet 格式,支持列存储,性能更优。目前,我们上层使用 StarRocks ,并部署了一些应用来调用存储介质。接下来,我们将讨论长城体系内逐步推进的存算分离架构方案。存储方面,我们使用 HDFS ,并探索使用 OSS ;计算方面,我们采用 MPP 架构的计算引擎,为各应用系统提供业务支持。另外,Flink解析后的数据会再次写入 Kafka 。当前架构相对陈旧,未来可能会集成Paimon, 从 Paimon 接入 Flink ,然后触发事件,将告警数据存储到 HDFS ,供上层应用使用。

在云端异常存储中,由于尚未使用数据湖,我们面临小文件合并的问题,目前通过离线方法解决,并计划在未来架构升级时引入支持这一需求的技术组件。同时,我们对信号存储进行了改造,从原先的按车型和车系单独存储改为从业务线角度进行数据剥离,以满足不同业务部门的查询需求,包括系统内查询和售后客服场景的跨系统查询。此外,我们使用Aviator适配器或逻辑匹配工具进行事件触发和告警,替代了之前存在内存泄露问题的工具。

目前,该系统已搭载约50万辆车,监控胎压、电池温度等指标,并在胎压不稳定或温度异常时向业务线的一线人员提供告警服务。在某些情况下,如发生碰撞,我们还会与客户合作实施救援。此外,我们对600万辆车的蓄电池亏电情况进行离线检测,特别是在疫情期间车辆长期停放可能导致电池损耗的情况下,通过APP端推送通知,建议用户启动车辆。
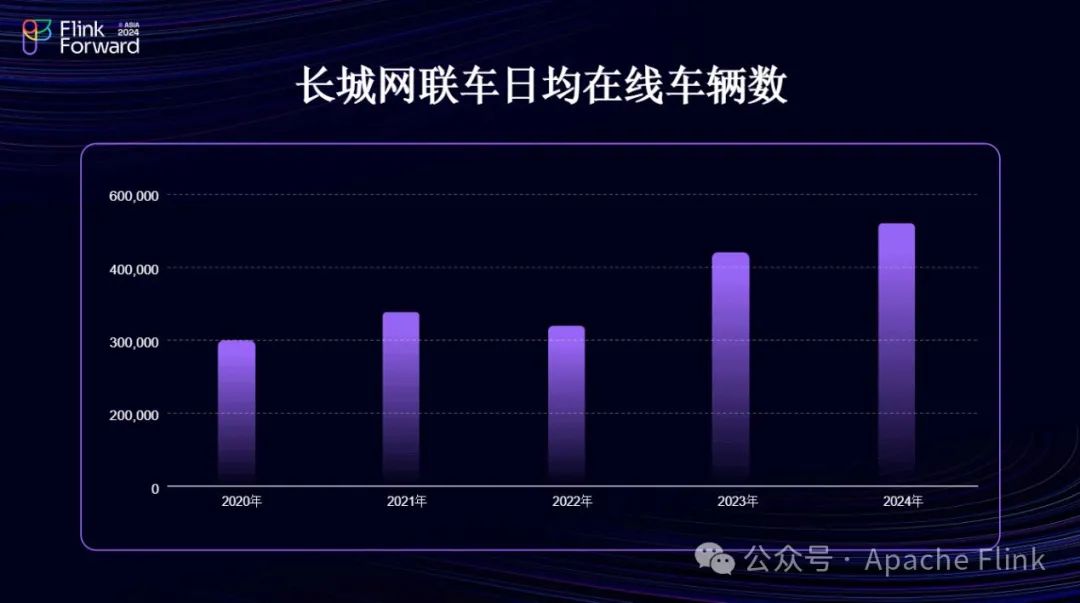
从当前在线车辆数量来看,除了疫情期间,我们每年的车辆数都在增长,系统压力也随之逐年增加。原有的基于Hadoop的架构已难以支撑,特别是在查询数据时表现不佳。因此,我们讨论了架构升级的必要性,并正在采用湖仓一体化的新架构体系进行升级。在升级过程中,我们也在考虑如何平滑地将旧体系迁移到新体系。
这些年走过的弯路踩过的坑

接下来,让我们讨论下这些年我们遇到的一些挑战。第一个挑战是时序问题,在业务处理中形成指标的数据高度依赖于数据的连续性。为解决这个问题,我们通过前端预处理和使用处理时间加触发器的方式进行改进,有效减少了数据量并提高了准确性。具体来说,我们在前端整合30秒的数据包,标记里程的起始和结束点、时间和油耗等,并设置五分钟的触发器来推送行程报告。尽管有时会遇到时序倒叙问题,但通过这些方法显著提升了数据处理的准确性和效率。此外,我们将自建的 Kafka 集群替换为阿里云的 Kafka,并根据业务场景进行信号分流,降低了成本并提高了稳定性。尽管在 Kafka 写入时的一致性解决方案效果不佳,我们在下游业务处理中进行了数据一致性校验,确保数据的准确性和一致性。
在与阿里同事共同参与的 Kafka 优化过程中,我们面临了第二个挑战,即一写多读模式下的高流量和高成本问题。为解决这些问题,我们首先将自建的 Kafka 集群替换为阿里云的 Kafka,显著提高了系统的稳定性和可维护性,并能更容易地发现瓶颈。其次,我们进行了信号分流,根据业务场景和需求进行更细致的划分,例如行程类数据单独分流,触发类信号进一步细分为安全类和监控类。通过这些措施,我们不仅大幅降低了成本,还支持了更多的业务场景。
第三个挑战是数据一致性问题,尽管 Flink 通过 Checkpoint 机制保证实时任务的一致性,但在写入 Kafka 时尝试使用两阶段提交的一致性解决方案效果不佳,导致严重的背压和任务失败。因此,我们在 Kafka 阶段无法实现一致性,会出现数据重复问题。为解决这一问题,我们在下游业务处理中进行了数据一致性校验,使用大状态存储记录某辆车的某个时间戳是否已处理,确保数据的一致性和准确性。尽管这解决了部分问题,但上游任务重试仍会导致下游业务数据重复。未来,我们计划通过湖仓技术等手段进一步解决这些问题。

在整体架构中,我们的数据采集部分包括使用 MQTT 物联网体系上传车辆的 ECU 信号和通过 HTTP 请求进行远程控制,响应时间在毫秒级别。底层存储包括文件数据,如 MQTT 上传的车联网数据、诊断数据和国标数据。我们面临的一个问题是同一元器件产生的信号可能会被重复采集和上报,且结果不一致,因为国标和 MQTT 有不同的采集链路和频率。未来计划是实现底层素材一体化,打通采集与云架构,形成统一架构,一次采集的数据可以同时服务于国标和周期性采集。在数据处理方面,我们使用 Flink 进行实时处理,Spark 进行离线处理。未来规划是实现 Flink 的流批一体,分为两个阶段:第一阶段对信号进行预处理和数据清洗,第二阶段使用 Flink 处理与业务紧密相关的逻辑。在应用层,我们使用 StarRocks 和 Doris 两套集群,应用于不同的场景:数据分析和对外应用。我们将应用分析和实时应用架构分开,因为这两套体系的应用场景不同,如果用同一套技术组件同时进行分析和数据应用,可能会导致资源争夺,从而影响应用的稳定性。因此,我们设计了 Doris 和 StarRocks 两套体系来支撑应用系统和服务,确保系统的高效和稳定运行。
感谢大家的观看!希望本次分享对各位有所助益~



 点击「阅读原文」跳转阿里云实时计算 Flink~
点击「阅读原文」跳转阿里云实时计算 Flink~