




写在文章开头
在当今的数字化时代,数据的高效处理和可靠存储成为了至关重要的需求。而在众多的技术解决方案中,Redis 集群以其独特的魅力和强大的功能脱颖而出。Redis 集群不仅仅是一组普通的服务器组合,它更是一个构建在先进技术之上的复杂而精巧的系统。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
详解分布式集群的基础
Redis分布式集群的作用
缓存中间件的存在就是解决磁盘与内存空间读写效率差异的存在,通过将热点数据缓存在内存中提升系统整理处理性能。但是针对海量热点数据读写的场景,redis
可能会存在如下问题:
内存空间不足导致内存被打满。 高并发读写请求导致 redis-server
无法实时完成指令请求,进而导致系统性能瓶颈。
针对问题1,我们可能可以通过提升硬件配置的方式临时解决问题,但无法解决问题2的操作阻塞,对此,我们提出水平拓展的方式搭建一套redis
集群来分散单节点的压力,所以我们说redis集群
是解决高可用和分布式的终极解决方案:

常见的分布式集群方案
数据发布理论基础
有了整体的架构思路之后,我们再来说一下分布式集群的解决方案,针对集群水平拓展,业界提出了3种解决方案:
节点取余分区 一致性哈希分区 虚拟槽分区
节点取余分区
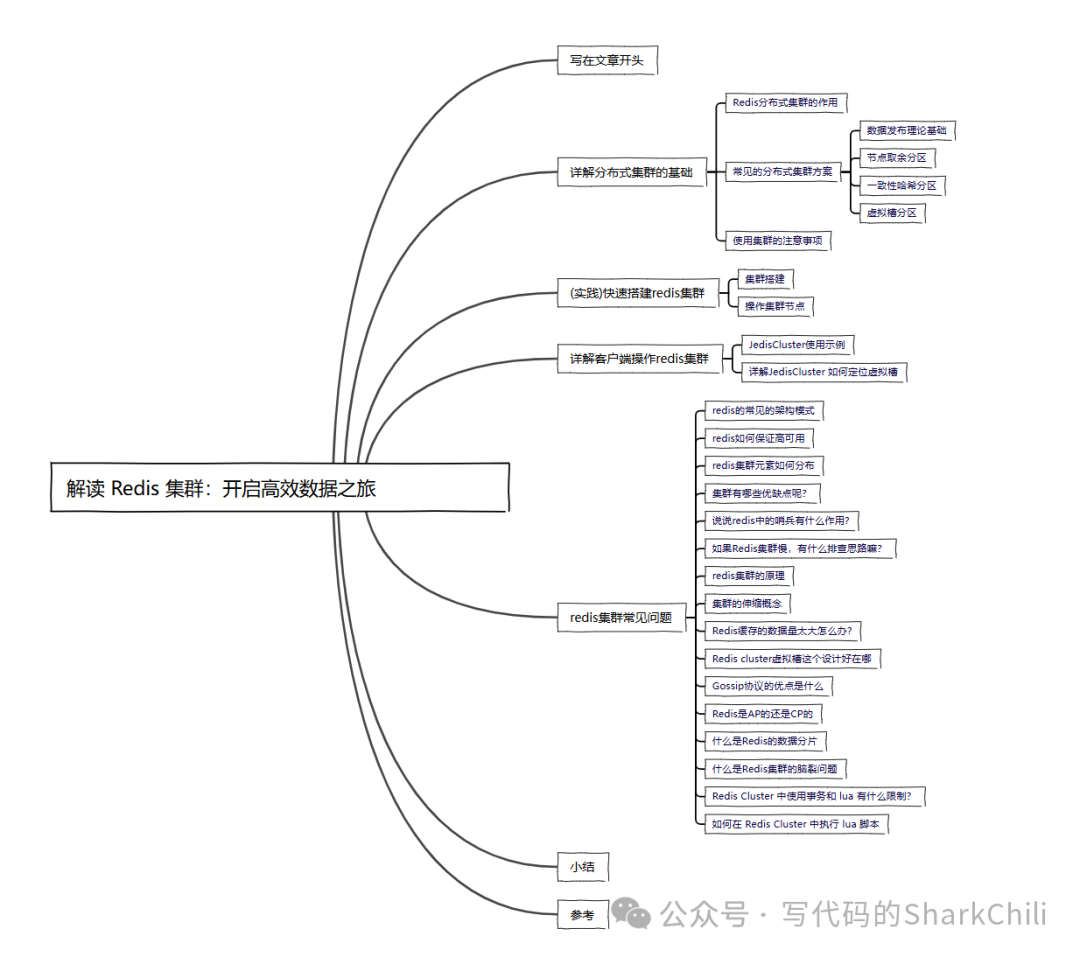
先来说说节点取余法,该方案针对key
进行hash
运算,然后按照节点数进行取模,这种方案虽然方便,但是缺点也很明显,一旦需要针对节点进行扩容即数量发生变化时,节点间的映射关系就会发生很大的变化,导致大范围迁移。 这种方案突出优点是简单性,更适用于那些能够完全预估到业务体量的分库分表的场景,通过预估进行分区再根据负载情况将表数据进行迁移,扩容时也通常会采用翻倍扩容的方式,避免全量数据秦迁移:
一致性哈希分区
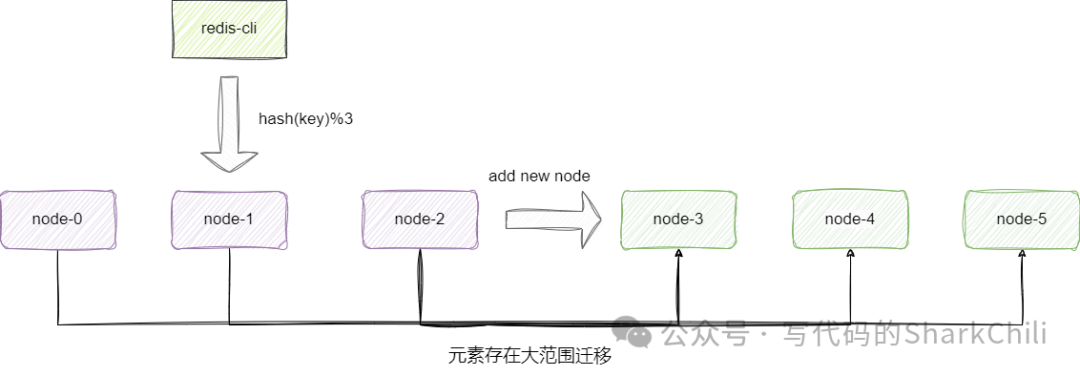
再来说说一致性哈希分区算法,该算法在逻辑上更像是用一个圆环维护所有集群节点,它会针对集群中的每一个节点分配一个token,范围基本处于0~2^32
,当我们需要插入一个元素的时候,通过hash运算得到一个hash值,基于这个hash值到查找第一个大于该hash值的token节点。

这种方案在进行扩容时,我们只需考虑在环上增加一个逻辑节点,影响面也仅仅是相邻的节点,例如我们在node-2
和node-3
之间插入一个node-4
,我们的影响面也仅需处理node-3
部分元素:
这种解决方案的缺陷也很明显,如上所说进行扩容看你会导致部分数据无法命中,所以我们还是需要手动针对附近区域的缓存数据进行迁移管理,并且为了保证均匀的集群拓展,我们还是需要考虑增加1倍的节点,才能保证数据负载均衡。
虚拟槽分区
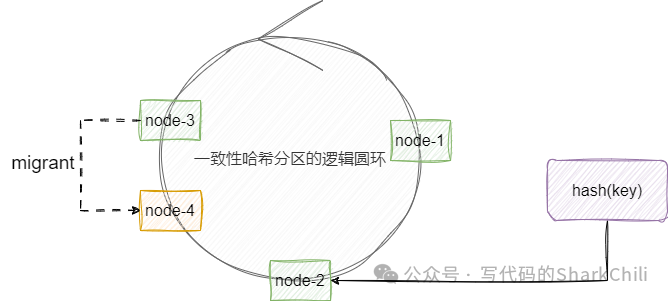
最后就是虚拟槽分区的概念,这就是redis
的解决方案了,该方案在初始化时会为每一个节点分配一个slot区间,以redis-cluster
为例slot
的范围是[0~16383]
,然后将这个slot分布到不同的集群节点上,当元素进行插入时通过高质量的hash算法得到一个slot值并完成插入,由此保证的了数据的均匀分布。
例如我们现在有3个节点,槽位换算后的区间如下所示,我们用redis客户端插入一个节点的过程大体如下所示,即通过crc16这个高质量算法定位得到一个slot
值6918
从而定位到节点3完成数据插入:
使用集群的注意事项
因为通过虚拟槽算法分散了键值对的读写,从微观的角度来看,redis-cli进行操作时需要注意一下几个问题:
引入redis集群的概念之后,进行键值对批量处理 hmset
和mget
等操作时会因为key
所处的节点不同而操作失败,所以redis在集群环境上是不支持直接批量操作的。因为元素的分散,无法很好的解决多key事务操作的原子性。 redis默认情况下有16个db,在集群模式下仅能操作db0(这一点其实无关痛痒)
(实践)快速搭建redis集群
集群搭建
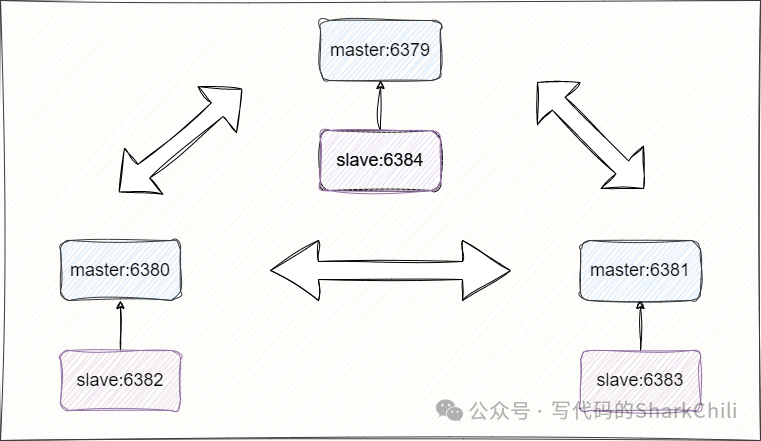
我们接下来通过不同的端口号演示一下redis多主多从集群模式的搭建,通过本节的步骤,我们可以快速构建集群节点并选出主节点和从节点:
我们首先创建一个名为nodes-6379.conf
的文件,用于创建6379
端口号的集群节点,对应的配置内容如下:
# 节点端口
port 6379
# 开启集群模式
cluster-enabled yes
# 节点超时时间,单位毫秒
cluster-node-timeout 15000
# 集群内部配置文件
cluster-config-file "nodes-6379.conf"
daemonize yes
同理基于上述配置创建6380、6381、6382、6383、6384几个节点的conf文件,这里就不多做赘述,然后键入如下指令将节点启动:
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
redis-server redis-6382.conf
redis-server redis-6383.conf
redis-server redis-6384.conf
此时我们可以通过ps -ef|grep redis
命令验证一下集群节点是否都正常启动:

最后我们键入下面这段指令让集群自动选出master并为每个master节点分配一个从节点:
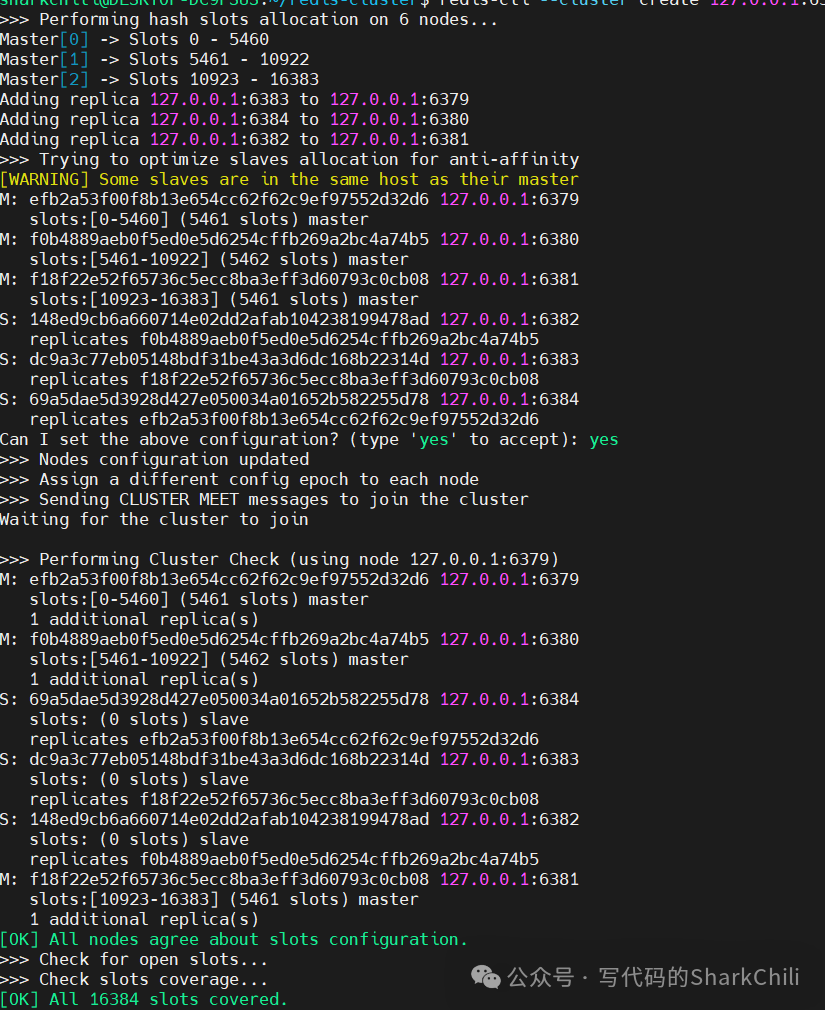
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
完成后就会输出下面这段结果,整体逻辑架构和笔者上图描绘的架构一致:
操作集群节点
我们通过集群模式连接6379:
redis-cli -c -p 6379
我们在6379尝试set一个键值对:
set k1 v1
可以看到这个值落到的端口号为6381
的节点上。
127.0.0.1:6379>
-> Redirected to slot [12706] located at 127.0.0.1:6381
OK
127.0.0.1:6381>
**注意:**一次性设置多值时我们需要,指明这几个值所属组(因为不同的key落到的slot可能不在一个redis节点上)
,否则会设置失败。
# 错误示例
127.0.0.1:6381> mset a1 v1 a2 v2
(error) CROSSSLOT Keys in request don't hash to the same slot
正确示例:
127.0.0.1:6381> mset a1{cust} v1 a2{cust} v2
-> Redirected to slot [4847] located at 127.0.0.1:6379
OK
127.0.0.1:6379>
我们也可以根据slot值找到对应count个数据
127.0.0.1:6379> CLUSTER GETKEYSINSLOT 4847 10
1) "a1{cust}"
2) "a2{cust}"
127.0.0.1:6379>
接下来就是测试阶段了,我们尝试让79主节点挂掉,看看集群中会发生什么变化
# 将79节点挂掉
127.0.0.1:6379> SHUTDOWN
not connected>
然后我们通过80节点操作集群:
# 通过80操作集群
redis-cli -c -p 6380
通过CLUSTER NODES
指令可以看到,过一段时间后,集群感知到6379节点下线了:

此时我们再通过redis-cli --cluster info 127.0.0.1 6380
即可看到84成为新的主节点:

详解客户端操作redis集群
JedisCluster使用示例
基于上述的集群架构,我们用Jedis演示一下java程序如何操作redis集群,首先我们操作工具jedis的依赖包:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
对应的操作示例如下,可以看到笔者这里为了方便演示,直接通过硬编码的方式设置redis实例信息让JedisCluster
完成初始化,然后通过set方法插入一个键值对:
//将所有redis示例都存到set中
Set<HostAndPort> redisServerHostSet = IntStream.rangeClosed(6379, 6384).boxed()
.map(p -> new HostAndPort("127.0.0.1", p))
.collect(Collectors.toSet());
log.info("redis server host:{}", redisServerHostSet);
//初始化 JedisCluster
JedisCluster jedisCluster = new JedisCluster(redisServerHostSet, 6000);
//插入键值对
String res = jedisCluster.set("test", "test");
log.info("redis cluster set result:{}", res);
操作结果如下,最终我们可以在6380节点看到该键值对:

详解JedisCluster 如何定位虚拟槽
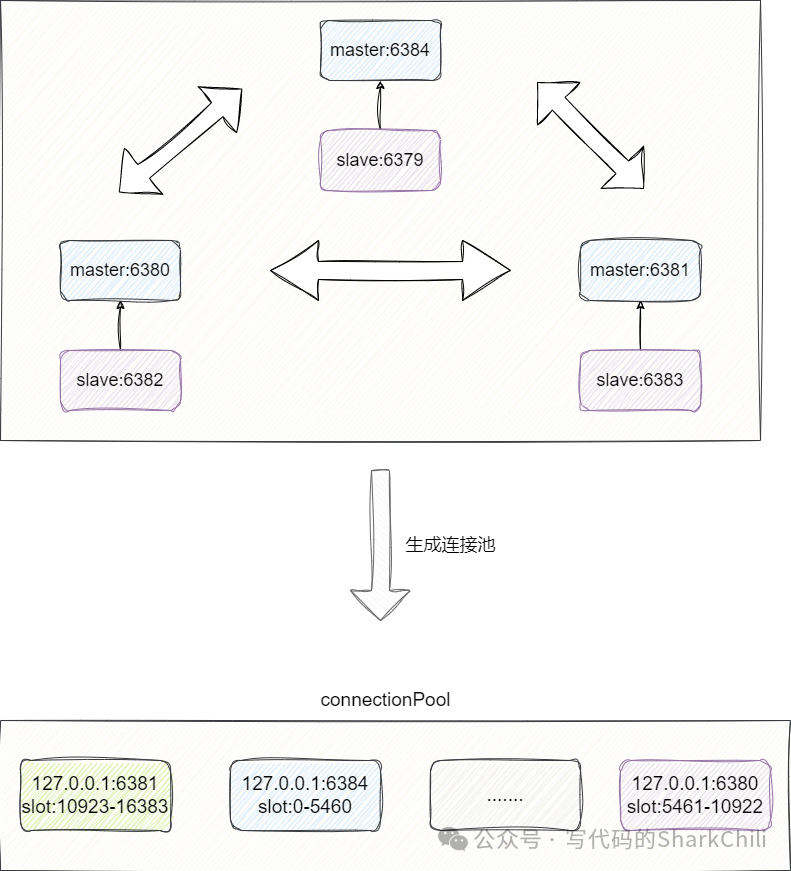
实际上JedisCluster
在构造函数初始化阶段就针对我们给出的实例信息创建了连接信息,并通过 cluster nodes
指令获取每个master
节点的槽信息由此构成连接池:
对此我们给出构建JedisCluster
时内部执行的initializeSlotsCache
,可以看到该方法内部会遍历我们外部传入的startNodes
(上文中创建的redis实例set集合),然后进行如下步骤:
基于遍历得到的 hostAndPort
创建jedis实例。调用 discoverClusterNodesAndSlots
方法,该方法内部会基于当前实例发送cluster nodes
指令获取所有master
节点对应的slot
槽。
之所以要遍历每一个节点进行连接池信息初始化,笔者猜测大体是为了保证可靠性,设计者考虑到可能发送cluster nodes
的实例无法通信亦或者信息可能有所缺失,所以在这一步选择遍历所有实例获取集群信息生成一个可靠的连接池:
private void initializeSlotsCache(Set<HostAndPort> startNodes, GenericObjectPoolConfig poolConfig, String password) {
//遍历创建的节点
for (HostAndPort hostAndPort : startNodes) {
//生成jedis对象
Jedis jedis = new Jedis(hostAndPort.getHost(), hostAndPort.getPort());
//......
try {
//调用discoverClusterNodesAndSlots生成对应实例的连接池和该连接对应的slot
cache.discoverClusterNodesAndSlots(jedis);
break;
} catch (JedisConnectionException e) {
// try next nodes
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}
步入discoverClusterNodesAndSlots
即可看到重点步骤:
上写锁保证操作线程安全。 基于当前 jedis
实例发送cluster nodes
指令获取所有master
实例信息及其负责的slot
槽的范围(源码中用slots
数组表示),注意这个slots
内部每一个元素都是一个数组,数组内部元素自左向右分别是slot
起始值、slot
结束值、master
端口号、slave
端口号。遍历 slots
查看每个slots
对应的实例是否创建连接池,如果没有则基于slots信息定位到对应master的ip地址建立连接并缓存下来方便后续复用。解锁完成操作。
对应的我们给出这段源码核心部分及其注释:
public void discoverClusterNodesAndSlots(Jedis jedis) {
//上写锁保证互斥
w.lock();
try {
//充值连接池信息
reset();
//调用cluster nodes获取master及其对应的slots
List<Object> slots = jedis.clusterSlots();
//遍历slots
for (Object slotInfoObj : slots) {
//将slotInfoObj 强转为列表,这个slotInfo 对应不同索引位置的值分别代表 slot起始值、slot结束值、master端口号、slave端口号
List<Object> slotInfo = (List<Object>) slotInfoObj;
//......
//从索引2开始获取master和slave阶段信息查看这几个实例节点连接池是否存在,若不存在则缓存
for (int i = MASTER_NODE_INDEX; i < size; i++) {
List<Object> hostInfos = (List<Object>) slotInfo.get(i);
//......
//获取节点ip和端口
HostAndPort targetNode = generateHostAndPort(hostInfos);
//查看连接池是否创建,若没有则创建并缓存
setupNodeIfNotExist(targetNode);
//查看索引值是否是2,如果是2说明当前节点是master将其对应的ip端口和slot信息缓存
if (i == MASTER_NODE_INDEX) {
assignSlotsToNode(slotNums, targetNode);
}
}
}
} finally {
w.unlock();
}
}
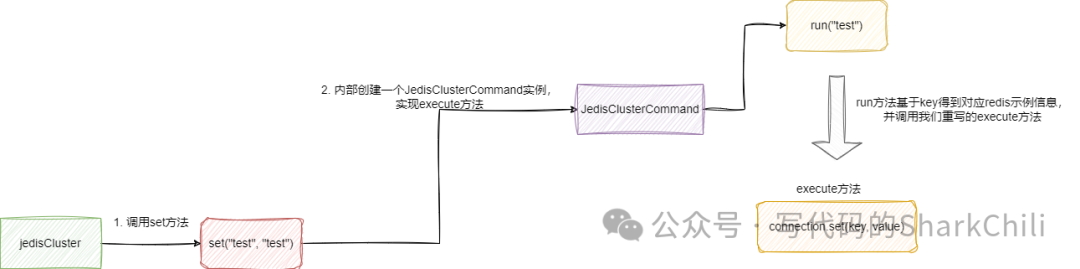
基于上述的初始化之后,在进行set操作时,其底层就会通过CRC16算法定位到这个key的slot,然后从连接池中获取对应实例的信息,从而完成键值对操作:
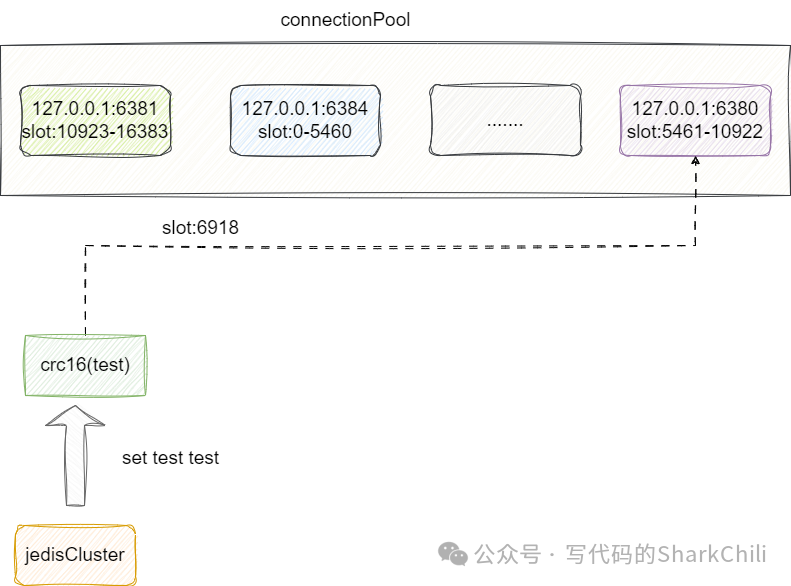
对此我们给出set方法的内部源码,可以看到下面这样一段抽象的代码实现,其实逻辑也很简单,首先我们需要知道JedisClusterCommand
是一个抽象类,该类的run
方法回基于给定的key找到对应的slot的连接,然后调用抽象方法execute
。
所以set方法内部就是创建一个JedisClusterCommand
并实现execute方法,execute的内容就是将run方法给定的key和value存到对应的集群节点上:
@Override
public String set(final String key, final String value) {
return new JedisClusterCommand<String>(connectionHandler, maxAttempts) {
@Override
public String execute(Jedis connection) {
//基于run方法给定的连接源将键值对存入
return connection.set(key, value);
}
}.run(key);//将key传给run方法拿到key所对应的slot的连接源
}
总结一下set方法内部函数实现的设计结构,大体如下所示,读者可以基于笔者的描述理解一下:
redis集群常见问题
Redis的常见的架构模式
redis
集群模型分为以下三种:
主从复制
:主节点负责所有写和读操作,其余从节点对外提供数据读操作,适用于读多写少的场景,但是不保证主节点下线后完成故障转移(可以通过手动实现)。哨兵模式
:为解决主节点故障情况下可以自动完成故障转移和恢复,redis
通过哨兵保证master发生故障之后,通过raft算法在sentinel
集群中选举出leader
,完成选举出新的master
并通知其他节点新的主节点信息。redis cluster
:是一种分布式集群解决方案,redis
提供cluster
的概念,它将按照不同的slot
将数据划分到不同的节点上。同时,redis cluster
通过主从复制模式来提高可用性,每个分片都有一个主节点和多个从节点,并且cluster
能够自动检测节点故障,当一个节点失去连接或不可达时,cluster
会尝试将该节点标记未不可用,然后从中选举一个从节点升级为主节点。详情可参考这篇文章:https://blog.csdn.net/womenyiqilalala/article/details/105145475
redis如何保证高可用
高可用的概念更多强调的是业务连续性,总的来说redis
哨兵模式和集群模式这两套解决方案都是支持高可用的,这两种架构的设计都是符合高可用的要求:
哨兵模式下部署主从节点,保证读写分离避免并发操作阻塞。集群模式则多主多从架构模式保证读写分离和数据水平分散。 哨兵模式通过哨兵集群主观和客观判断进行节点下线分析,再通过raft选举哨兵leader进行故障转移。而集群模式则是通过集群节点进行故障定位和故障转移。 通过rdb、aof等持久化机制一定程度避免数据丢失。
redis集群元素如何分布
如上文我们给出的集群有16384
个插槽,客户端写入数据时都会通过CRC16(key) % 16384
计算该节点已决定最终这个数据落到哪个slot
中,当然即使客户端将读写请求发送到非请求slot的节点时,redis集群也会通过请求重定向的方式告知客户端需要连接的redis集群实例。
如下所示,我们的将6380的写请求通过6382
操作,redis服务端通过计算后告知实际操作地址,然后客户端直接重定向到对应服务端上进行操作:
27.0.0.1:6382> set k v
-> Redirected to slot [7629] located at 127.0.0.1:6380
OK
127.0.0.1:6380> set k v
OK
当然java主流开源工具对于这种问题都做好了优化,即在客户端工具类启动时通过cluster nodes获取所有集群节点的信息并基于此信息生成一份连接池,例如下面这样3个节点的信息,JedisCluster 就会在启动时将每个集群的master地址和slot进行映射分配并缓存:
1. 节点 A(6379) 负责处理 0 号至 5460 号插槽。
2. 节点 B(6380) 负责处理 5461 号至 10922 号插槽。
3. 节点 C(6381) 负责处理 10923 号至 16383 号插槽。
后续程序进行读写操作时都以此为基础进行通信,具体读者可参考笔者上述redis集群操作的工具JedisCluster
示例和源码解析,这里就不多做演示了。
集群有哪些优缺点呢?
优点:
通过水平拓展方式增加节点,避免单节点导致系统吞吐量下降。 无中心化配置部署简单且可以保证可用性。 基于虚拟插槽分区并配合crc16算法数据尽可能的分布均匀。
缺点:
多键操作需要基于组,实现不方便。 不支持事务, lua
脚本不支持。由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至 redis cluster
,需要整体迁移而不是逐步过渡,复杂度较大。
说说redis中的哨兵有什么作用?
哨兵是保证高可用的集群节点,总的来说它有以下几个作用:
监控:监控当前所有redis主从节点 故障转移:一旦redis主节点挂了,哨兵就会选一个leader在众多从节点中出来挑一个新的主节点上位(主从切换) 通知:可通过指令通知其他客户端或者应用程序当前节点下线以及新的master信息。
关于哨兵对于master节点监控和故障转移工作机制,感兴趣的读者可以阅读笔者下面这两篇关于哨兵模式的源码分析:
来聊聊Redis哨兵如何主观认定下线:https://mp.weixin.qq.com/s/YjSfYq3gLjlV_aT-B6DV6Q聊聊Redis哨兵选举与故障转移的实现:https://mp.weixin.qq.com/s/VwkYY2l_QsELxrvB5Na76g
如果Redis集群慢,有什么排查思路嘛?
就针对集群来说,我认为入手点应该是下面3个:
先看看网络IO情况。 再看看CPU负载。 再看看内存情况,看看是不是内存占用过大导致系统负载过重。
redis集群的原理
我们通过redis-cli --cluster create
或者cluster meet{ip}{port}
指令进行集群创建和管理时,集群中的节点就会基于Goossip协议和集群中的各个节点进行握手和信息交换,通过集群中的节点随机通信和扩散传播,将一个个独立的节点构成一个redis cluster
。
随后redis cluster就会按照下述步骤有序执行,构建一个完整的分布式集群架构:
基于参数确定master数,得出对应的slots范围。 选举出master节点。 slave节点分配(按照--cluster-replicas 指定的数量)
这些步骤我们可以根据上述集群创建的输出日志出印证:
再来说说故障转移,假设集群中的某个节点通过ping
通信感知到某个节点已经在cluster-node-timeout
配置的时间内没有收到消息,就会将其标记为主观下线,随后该节点就会基于gossip协议发送询问其他节点对于该节点状态的判断,超过半数以上认定下线后,该节点就会被认为客观开始,开始故障转移流程:
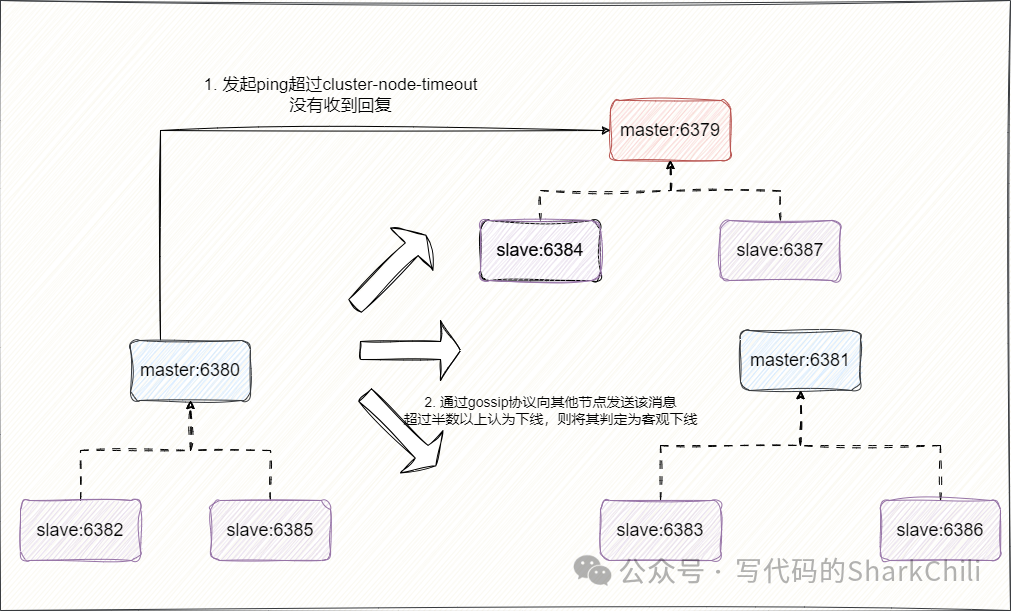
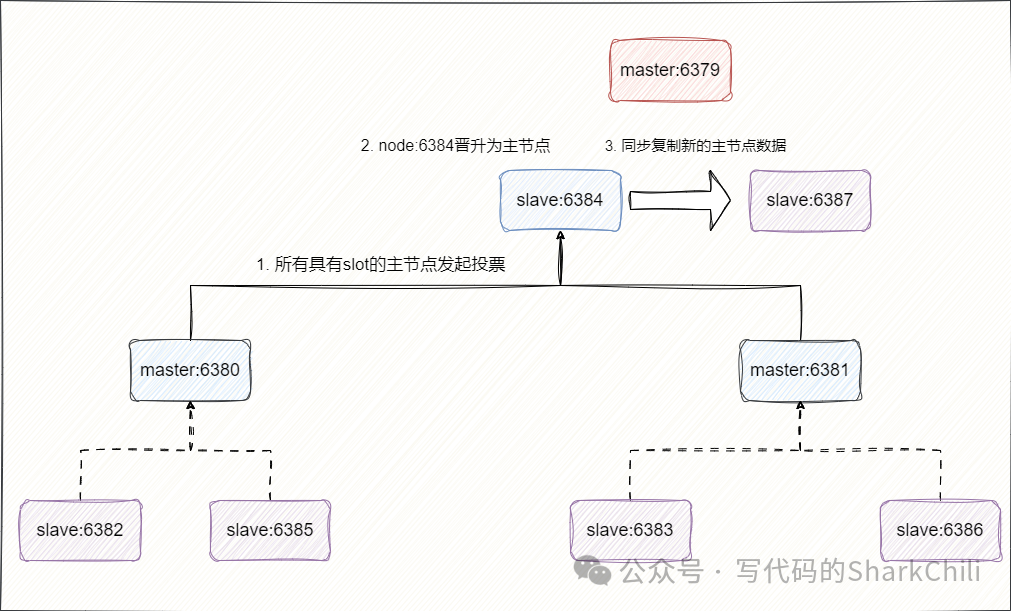
而redis
集群故障转移的大体流程未:
下线的主节点对应的从节点就会检查与主节点断线时间,判断自己是否有资格替换主节点。 超过 failover_auth_time
发起投票选举。所有具有slot的主节点进行投票 得到 主节点总数/2+1
的从节点晋升为新的主节点。
选举新的主节点之后,故障转移就完成了,没选举上的从节点就会同步复制该主节点的消息:
关于redis集群gossip协议的工作机制,感兴趣的读者可以阅读考笔者下面这篇文章:
来聊聊去中心化Redis集群节点如何完成通:https://mp.weixin.qq.com/s/ReOHE4DcMqc8WRHpeRIIfA
集群的伸缩概念
当集群增加新的节点时,基于内部节点会通过共享消息感知到这一点,并为其分配slot,基于最新的slot针对集群节点数据进行自动迁移,注意在迁移期间,节点依然可以对外提供数据读写,整体对外提供服务的大致工作流程为:
对应的 key
没有对应的slot
直接返回错误。如果定位到的slot为当前节点,且节点正在迁出且当前节点没有值,基于ask标识告知客户端到迁出的节点询问,反之直接从当前节点获取值返回给客户端。 如果定位到的slot为当前节点,且节点正在到导入别的节点的数据,并且当前节点没有值,则直接响应错误。 如果定位的slot对应节点是自己且有值,则直接返回给客户端。 如果定位到slot的实例节点是其他节点则发送move请求让客户端到别的节点读取数据。
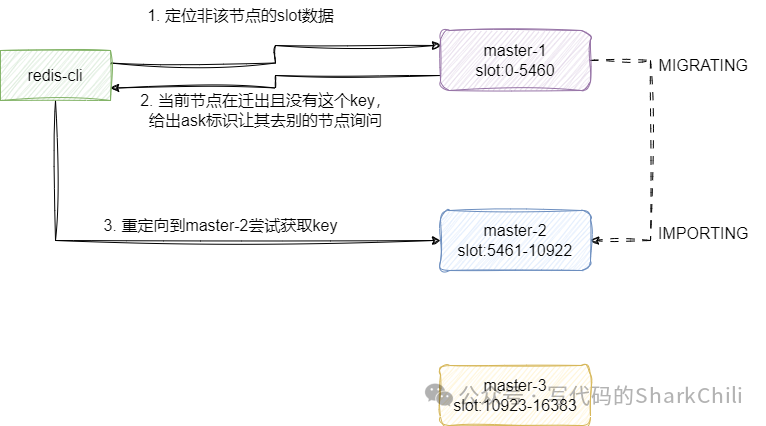
如果对于redis集群迁移实现细节感兴趣的读者,可以参考笔者写的这篇关于集群数据迁移的源码分析:来聊聊redis集群数据迁移:https://mp.weixin.qq.com/s/FVmnhvpIVdbskSDHK3Vq0w
Redis缓存的数据量太大怎么办?
进行一个Redis
切片集群,设置多主多从架构,通过redis高效的哈希算法将key均匀分布到节点中,实现横向扩容,从分散单节点的压力,保证节点高可用。
Redis cluster虚拟槽这个设计好在哪
解耦了数据与节点之间的关联,不像一致性hash算法一样要key & 节点个数
运算,而是用CRC16(key) % 槽的个数
,从而提升数据横向扩展和容错性。
Gossip协议的优点是什么
该协议使得每个节点都维护了集群中某一部分的节点的信息,在指定时间内大家达成数据一致。大家像病毒一样互相将数据如同"传染"传播出去。通过Gossip
协议实现去中心化的方式保证节点间的服务通信、请求转发、自动故障转移等。
Redis是AP的还是CP的
首先需要强调的是讨论CAP
这个问题的前提必须是分布式场景,在分布式的场景下,redis
通过与集群节点进行通信完成数据异步复制,这意味着集群环境下它的数据不能保证实时强一致性,只能保证最终一致性。 并且节点直接复制的一致性问题还可能收到节点故障的影响,当某个节点宕机时,该节点的数据可能还未完全同步到其他节点,导致数据丢失,虽然redis通过
主从节点以及哨兵机制可以保证系统的可用性和容错性,但并不能完全节点数据一致性问题。 所以,笔者认为redis
的CP
的。
什么是Redis的数据分片
上文提到的redis cluster
的概念,本质上,redis的数据分片就是通过hash slot
进行数据分片,通过该算法划分出一批又一批的槽将数据存储到不同的的节点上。 进行数据读写时,现根据key(通过crc1算法然后和16384进行取模)计算出对应的槽编号,然后根据槽编号找到对应的节点,从而完成读写请求的处理。 总的来说,redis的数据分片有以下几个特点:
提升性能和吞吐量:将请求分散到多个节点上,可以并行处理更多的请求,从而提升系统整体性能和吞吐量。 提高可扩展性:分片方案使得redis可以进行水平扩展,针对海量并发场景我们可以通过添加更多的节点和容量来提升集群处理能力。 更好的利用资源:通过分片可以尽可能有效利用每一台服务器。 避免单点故障:通过分片保证及时单台服务器发生故障,其他节点仍然可以正常运行。 数据冗余和高可用:在分片场景下结合主从复制保证即使某个节点发生故障也能通过故障转移恢复,提升系统可用性。
什么是Redis集群的脑裂问题
即一个分布式集群环境下因为网络波动等问题分裂成两个集群,然后每个集群都有自己的master节点,各自处理各自的请求,数据无法保证最终一致性。
Redis Cluster 中使用事务和 lua 有什么限制?
不能跨节点
如何在 Redis Cluster 中执行 lua 脚本
保证操作的节点数据都设置在一个slot节点上
小结
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
参考
一万字详解 Redis Cluster Gossip 协议:https://segmentfault.com/a/1190000038373546
分布式算法 - Raft算法:https://www.pdai.tech/md/algorithm/alg-domain-distribute-x-raft.html
Redis 集群教程:https://www.redis.com.cn/topics/cluster-tutorial.html
Redis变慢的五大原因以及排查方法_skye_fly的博客-CSDN博客_redis读取数据非常慢:https://blog.csdn.net/skye_fly/article/details/119979126
面渣逆袭(Redis面试题八股文)必看👍 | Java程序员进阶之路 (tobebetterjavaer.com):https://tobebetterjavaer.com/sidebar/sanfene/redis.html#_23-集群中数据如何分区
redis应用实战jedis-sentinel,Jedis-cluster原理分析:https://blog.csdn.net/madongyu1259892936/article/details/85237996
超详细的 Redis Cluster 官方集群搭建指南,适用于 redis 5.x, 6.x :https://blog.csdn.net/agonie201218/article/details/123816907
【Redis】Redis 是如何保证高可用的:https://blog.csdn.net/weixin_42201180/article/details/129624041
