前几天数据库训练营一个朋友发了一个2个awr,说看起很怪异,简单看了一眼,2个节点awr数据类似,这里以其中一个节点AWR为例子进行分析说明。
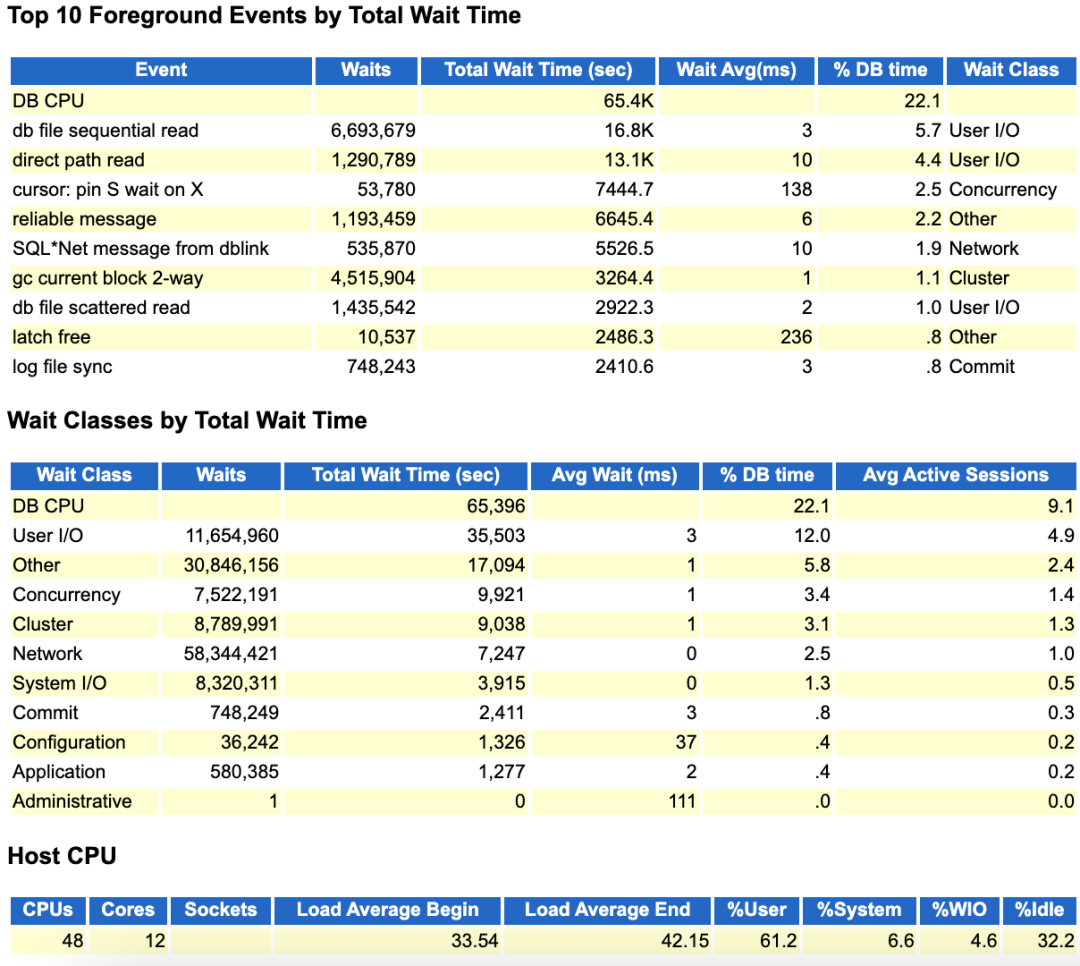
从top event和wait Classes数据来看,DB CPU也就22%左右,确实很低。但是看Host CPU部分的数据,似乎又不太对。
因为CPU Idle只有32.2%了,说明单看cpu的话,系统负载还是比较高的。
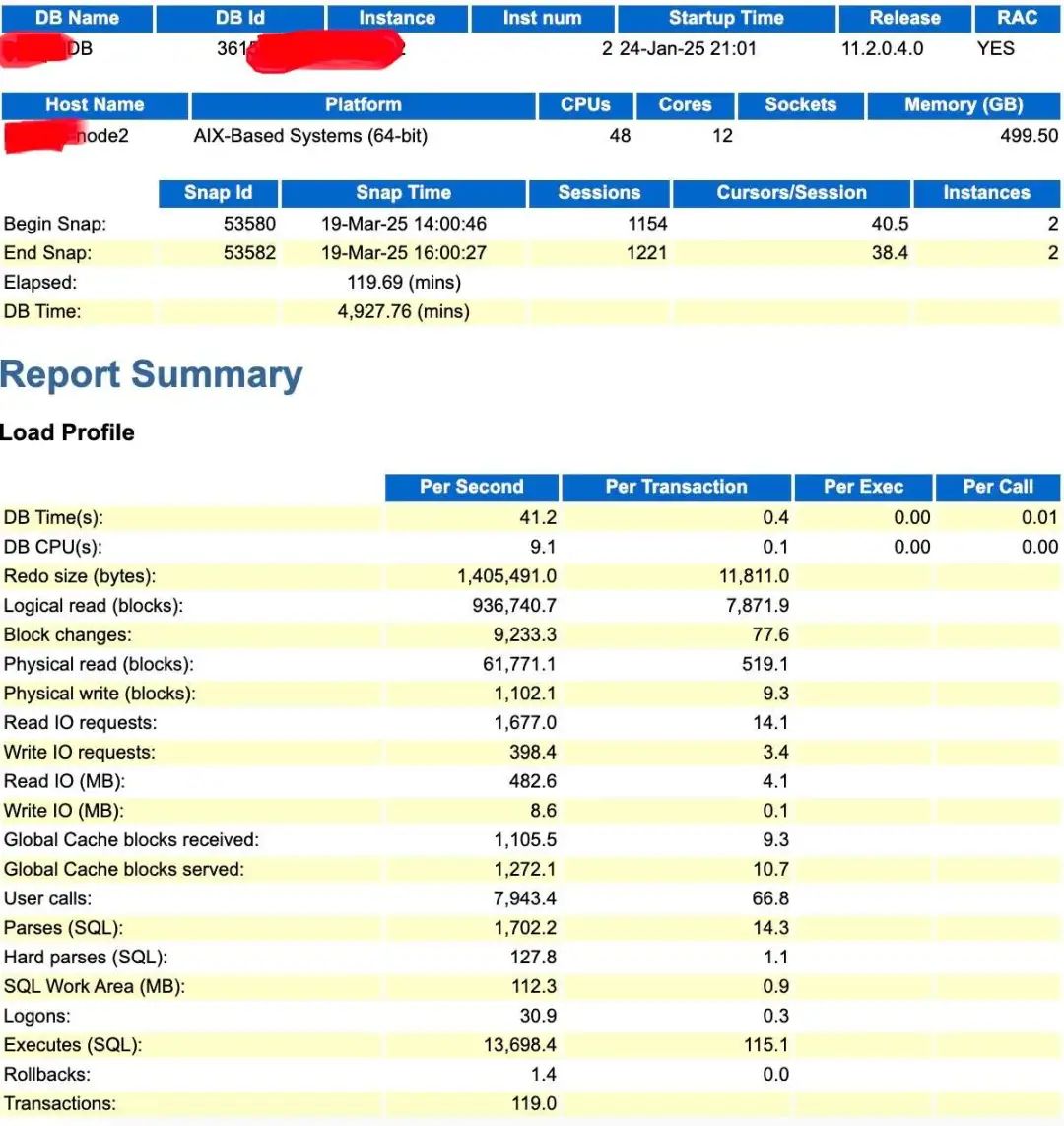
那么这个DB CPU 22.1%是怎么来的?
实际上很简单,DB CPU(9.1)/DB Times(41.2)=22.08%,四舍五入就是22.1%。
我们通常习惯于通使用DB Time来判断一个系统负载的高低,比如这里单节点48c,意味着cpu的处理能力是48*120=5760(mins),而当前DB time是4927min,已经比较接近了,说明负载较高。
同时我们也知道DB time=DB CPU+ FG Wait Time+ Non-Idle Wait。
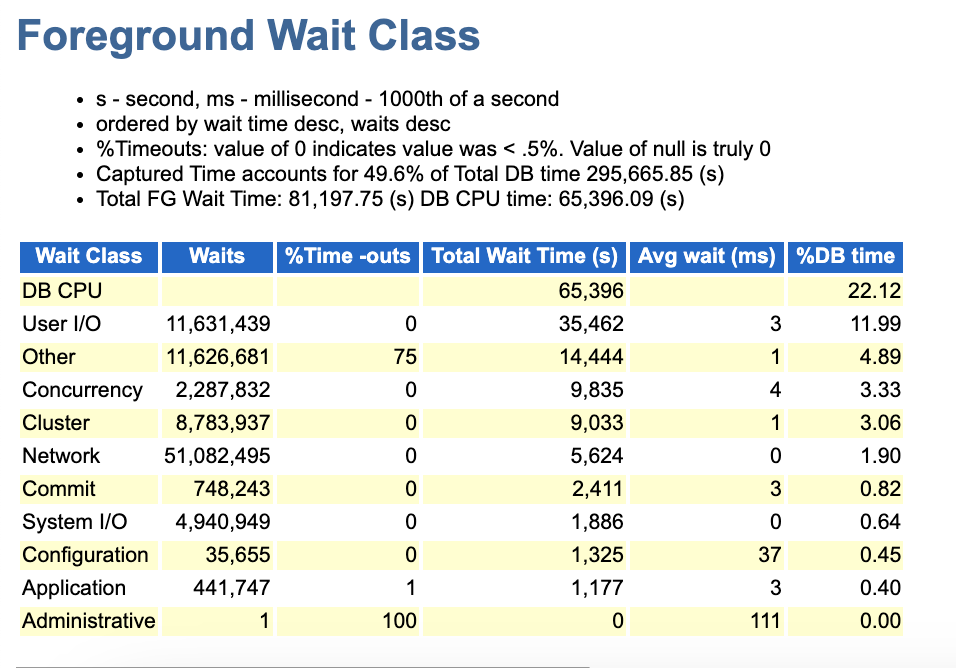
从这里来看Total FG wait time=81197.75s,DB CPU time=65396.09s;两者合计为:146593.84s
然而我们根据这个时间换算一下,146593.84s/60=2443.21mins ,这远小于我们的5760mins。
由此可见其他的时间可能都是在Not Idle wait上,比如进程等待,网络等待这些上面。
那么问题究竟在哪儿呢?
我们接着往下分析分析。
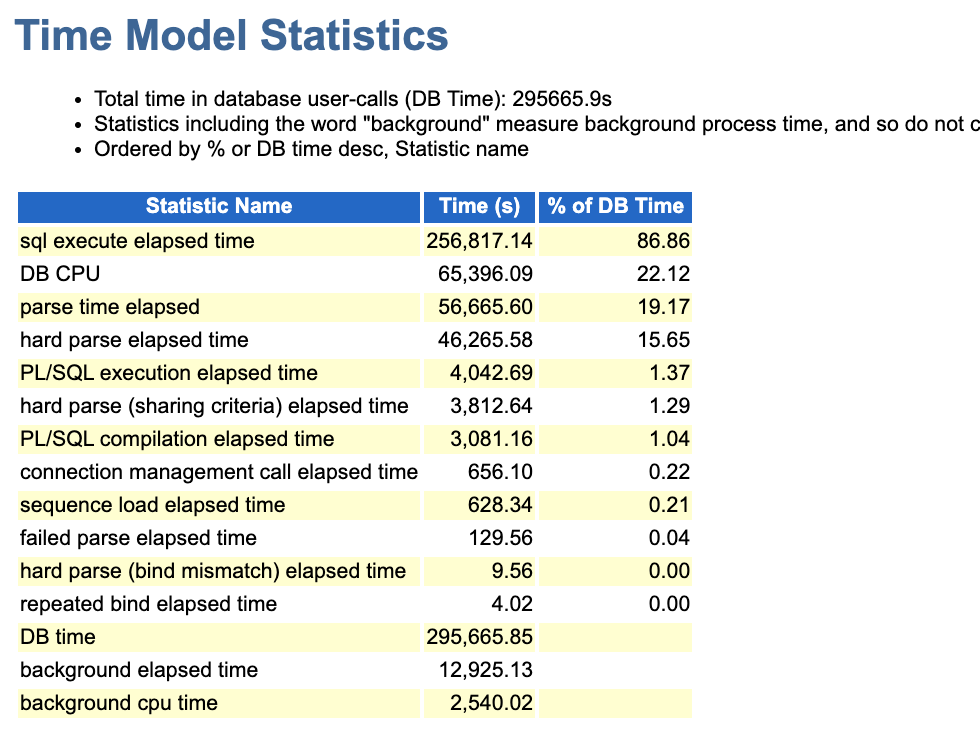
从整个DB time model的数据来看,DB time 一共是29万秒,其中sql execute elapsed time 高达256817万秒。不难看出SQL本身的执行就消耗绝大部分时间,其解析就消耗了56665秒,高达19%,这也是非常高的。
我记得我讲过多次,一个比较良好的系统来讲,parse time应该控制在3-5%,甚至更低【当然这里硬解析也高的离谱】。
同时通os的数据也可以看出,cpu wait是很高的。
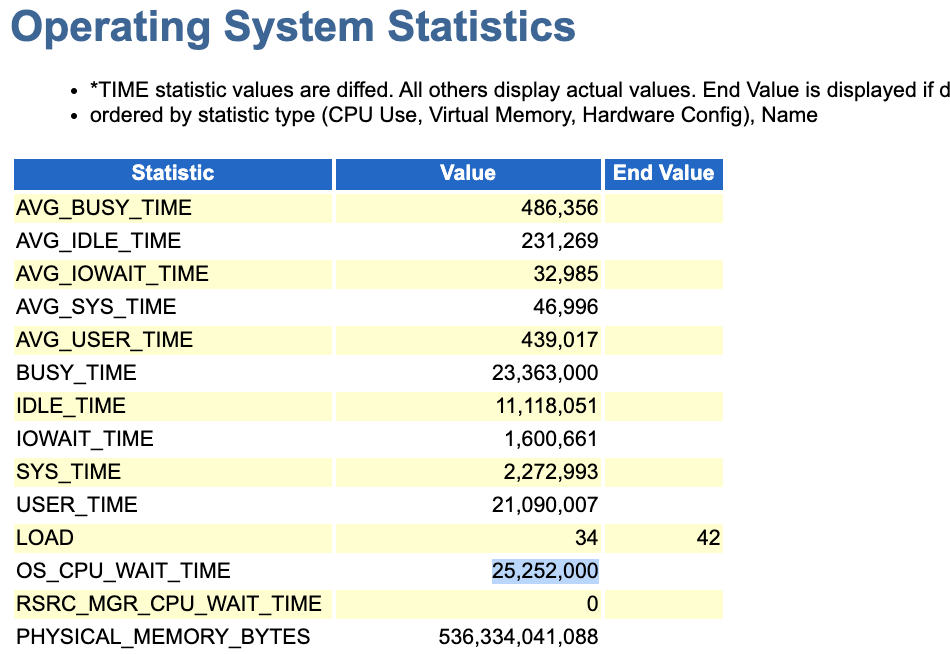
另外结合前面看到的wait class部分以及top event,不能看出dblink的访问也是一个较大的问题,毕竟这部分产生的等待也比较高。
因此我们不能单纯的看 DB CPU + Foreground Wait Events很低,就认为一定是OS的cpu处理能力不足,需要扩容CPU;尽管看上去cpu wait指标也不低。
实际上还应该看看user%+sys%高不高,甚至看看iowait%指标;通常来讲当user%+sys%很高的情况之下,同时iowait%也很低【sys%并不高】,才能直接定性为cpu资源不足。
回到这个案例中来看,实际上把sql解析问题处理掉+top sql优化一下,我认为基本上就ok了。
为什么这样讲呢,看了下参数实际上关闭了直接路径读【_serial_direct_read=never】,但是direct reads还是很高,几乎消耗了整个物理IO的95%。
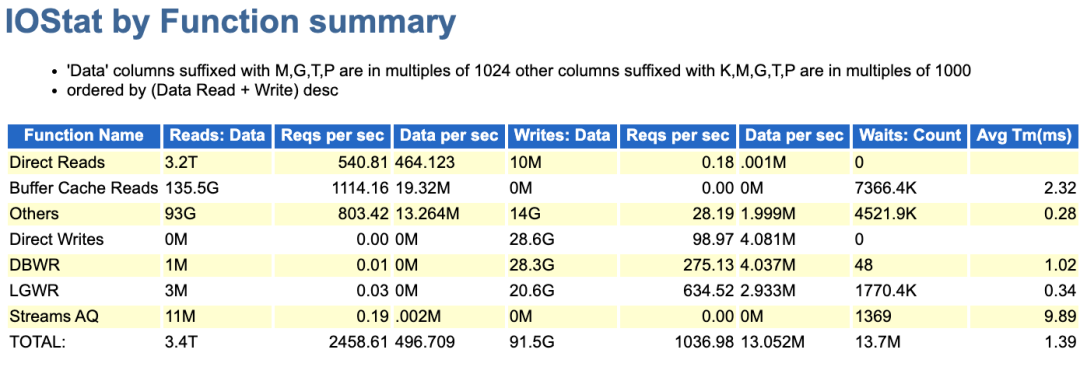
从这里可以确认这库应该有大量的并行查询,实际上看event top 30之后的等待,也能看到大量的PX等待。

当然这个库问题还有其他的问题点,比如drm没关,进而产生的等待都超过1000s。
就分析这么多啦,大家有好玩的案例,可以私信我!