





Tair KVCache 简介
当前大语言模型(LLM)推理的快速发展推高了算力需求,与此同时,推理过程中的 KVCache 技术所需的巨大显存消耗成为显著瓶颈。KVCache 技术通过缓存历史 Token 的 Key/Value 向量矩阵避免重复计算,虽将时间复杂度从 O(n²) 降至 O(n),却导致显存占用随生成长度线性暴增,成为制约长文本生成和批量推理的核心瓶颈。
AI 场景对内存的需求
2.1 HBM容量瓶颈
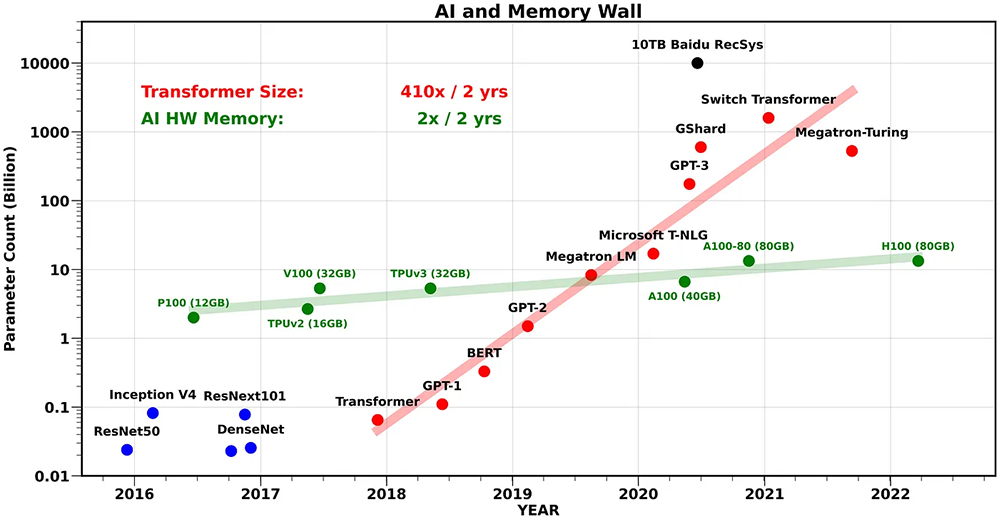
图1:AI和内存墙 [1]
2.2 带宽瓶颈
在大语言模型推理场景中,当尝试将部分计算数据从高速 HBM 内存扩展到本地DRAM、SSD 或通过 RDMA 协议扩展至远端存储时,带宽资源的约束成为核心挑战。由于模型参数和推理过程中动态生成的 KVCache 通常优先驻留在 HBM 中,当模型规模超出 HBM 容量上限时,数据被迫向 DRAM 或 SSD 换入换出,此类低速存储介质的带宽(例如 SSD 带宽仅为 HBM 的百分之一)会严重拖累推理效率。若存储层级间的带宽不足,会导致计算单元频繁因数据等待而空闲,显著降低硬件利用率。
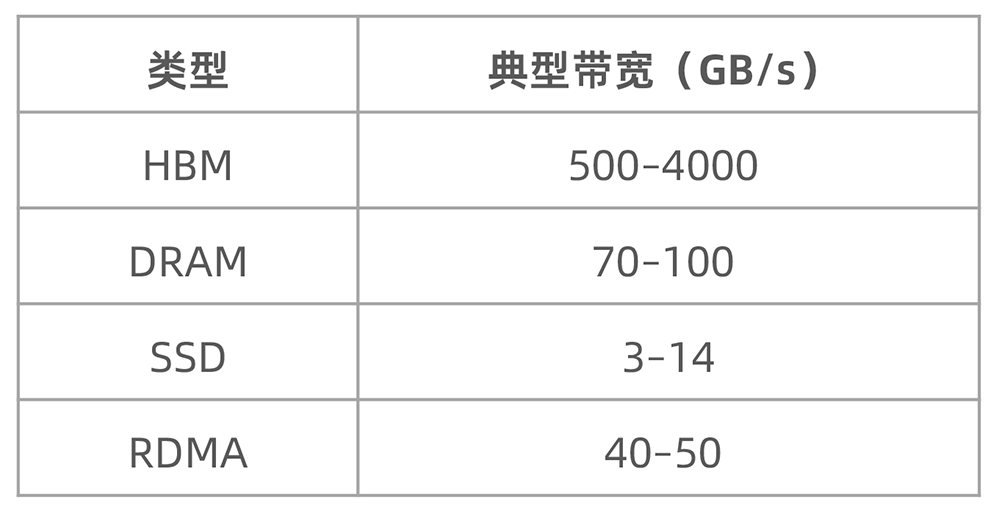
表1:存储介质带宽
为应对这一矛盾,如何基于有限带宽充分挖掘 DRAM 和 SSD 的容量潜力以加速推理服务,成为亟待突破的技术难点。即使通过本地资源扩展技术缓解容量压力,仍可能面临以下问题:
资源利用率不均衡:不同负载场景下易出现局部资源闲置;
本地容量天花板:超大规模模型仍需跨节点资源协同;
分布式扩展代价:构建资源池化架构虽能提升弹性,但会加剧网络带宽竞争,需通过数据亲和性调度优化通信路径。
2.3 产品服务化内存加速需求
队列化负载均衡:由于单个推理请求特别是 Reason 类的模型执行耗时较长(秒级至分钟级),需通过内存队列实现请求缓冲。
分布式协同开销:多节点推理需同步处理任务切分、中间状态同步、结果聚合,跨节点通信延迟易成为吞吐量提升的瓶颈。
多轮对话缓存:针对 LLM 生成式任务(文本续写、多轮问答),需在内存中维持会话状态缓存(Session Cache),支持历史上下文快速检索以保障前端交互流畅性。
动态限流控制:基于令牌桶之类算法实施请求速率限制,防止恶意高频请求(如 DDoS 攻击)过度抢占 GPU 计算资源。
Tair KVCache 通过软硬协同设计的池化实现,完成显存容量的灵活扩展与计算资源的高效解耦;同时上层的调度组件充分利用内存的加速能力,支持如限流、亲和性调度、对话缓存加速、执行预测等产品化服务需求。基于通用的模型和推理引擎,无缝兼容主流大语言模型架构,达成端到端百 GB 级 KVCache 吞吐与毫秒级响应,满足高并发、低延迟的生成式 AI 场景需求。

图2:Tair KVCache 介绍
3.1 分布式内存池化
Tair KVCache 利用 GPU 集群空闲内存组成分布式内存池, 按需计费节省单机空闲内存,同时可以突破单机内存瓶颈。
分布式内存池化的核心目标是通过统一管理多级存储资源(GPU 显存、CPU 内存、SSD、远端存储),实现显存容量扩展 与 计算资源解耦。
KVCache 是 Transformer 推理中除权重以外显存占用主体,其 Offload 设计直接影响大模型推理效率:
通过将 KVCache 卸载至分布式池化存储,单卡显存仅需保留热数据,达到支持: 1)更大 Batch Size:实验显示批处理规模提升 5-10 倍; 2)长上下文处理:如百万 Token 级输入(需数百 GB KVCache)。 计算与带宽优化,以存代算:复用历史 KVCache(如对话缓存),减少重复计算,加速推理,TTFT(首 Token 时间)缩短为原来的 1/10。
3.2 多级 KVCache 分配管理
易用性:提供统一的调用接口与错误处理接口,屏蔽底层物理差异,支持上层 Cache 调度与管理。
高性能:内存热点 Locality 感知,与调度器结合,提高内存资源利用率,充分发挥 KVCache 复用的性能优势,提高算力效率;根据底层互联特性,提供高效数据交互机制实现高带宽的 KVCache 共享。
可扩展:随着后续物理介质和互联协议的持续发展,能充分利用底层内存语义介质(AliSCM)和互联协议(Alink)系统平滑迁移,为 KVCache 提供极致高带宽与低成本,同时支持多样拓扑与分级 KVCache 的调度和管理机制。

图3:内存池化 MemPool 系统

图4:多级 KVCache 分配管理
3.3 服务化支持
▶︎ 队列化负载均衡
利用内存队列 Stream 可以把推理任务投递到 Stream 中,推理引擎做为消费者使用 XREADGroup 命令从所属任务组中按需拉取任务。支持阻塞式读取(等待新任务到达)或批量拉取,避免频繁轮询。多个推理引擎消费者属于同一任务时,Stream 自动将消息分配给不同的消费者,实现并行处理。每个消费者独立维护未确认(Pending)消息列表,确保任务不会被重复消费。

▶︎ 多轮对话缓存
Hash结构来满足:1)快速存取——毫秒级响应,避免对话卡顿;2)上下文关联——支持按会话 ID(Session ID)快速检索完整历史;3)高并发支持——应对海量用户同时发起对话。
初始化会话生成唯一对话标识符
session_id
。创建 Hash 结构并设置初始元数据,如
HSET session:123 metadata '{"user_id": "abc", "model": "XXX"}'
。设置 TTL 实现自动过期,如
EXPIRE session:123 3600
。存储多轮对话,如 SET session:123:turn:5 "What's the capital of France?"。
以恒定速率处理请求,超出桶容量的请求被丢弃或排队。用于:1)防止资源过载:避免计算资源被恶意或异常流量耗尽。2)保障服务质量:确保高优先级请求(如付费用户)的响应时间符合 SLA。
使用List
结构模拟漏桶:
入队:新请求通过
LPUSH
加入队列。出队:通过定时任务以固定速率
PROP
处理请求。溢出控制:检查队列长度(LLEN),超过容量则拒绝新请求。
3.4 兼容性
总结
参考阅读
[1] AI和内存墙:https://arxiv.org/abs/2403.14123



点击 阅读原文 进行 Tair KVCache 业务咨询

