





本文字数:19861;估计阅读时间:50 分钟

Meetup活动
ClickHouse 深圳第二届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!

对于实时分析应用(如仪表盘),流畅的响应速度至关重要。Jakob Nielsen 的研究、心理计时学理论,以及 Steve Henty 的进一步分析总结了人类对系统响应时间的感知标准:
<100ms(瞬时)—— 近乎即时,理想用于筛选或快速更新。
100ms - 500ms(非常快)—— 运行流畅,适用于图表渲染、选项卡切换或摘要计算。
500ms - 1s(可察觉的延迟)—— 用户能明显感受到等待,但对于复杂查询仍可接受。
1s - 2s(缓慢但可容忍)—— 可能会让用户感觉卡顿,建议添加加载指示器。
>2s(过慢)—— 体验不佳,用户可能会失去耐心或注意力。
要在大规模数据集上实现 小于 500ms,甚至小于 100ms 的查询响应时间,尤其是在处理 数十亿个 JSON 文档 时,没有合适的数据库支撑将极具挑战性。随着数据量增长,大多数系统的查询性能都会显著下降,导致仪表盘响应变慢,用户体验受损。
在本文中,我们将通过 三个典型的实时仪表盘场景,展示经过验证的查询加速技术。在这些场景中,所有查询均基于 40 亿个 Bluesky JSON 文档(1.6 TiB 数据) 进行计算,并且 仅运行在一台普通的中等规格服务器上,但仍能实现:
① 确保 ClickHouse 查询始终低于 100ms,提供瞬时响应。
② 无论数据规模增长多少,查询速度始终保持稳定。
③ 始终运行在最新数据上,且延迟极低。
④ CPU 和内存占用极低,仅消耗 KB 级到低 MB 级的 RAM。
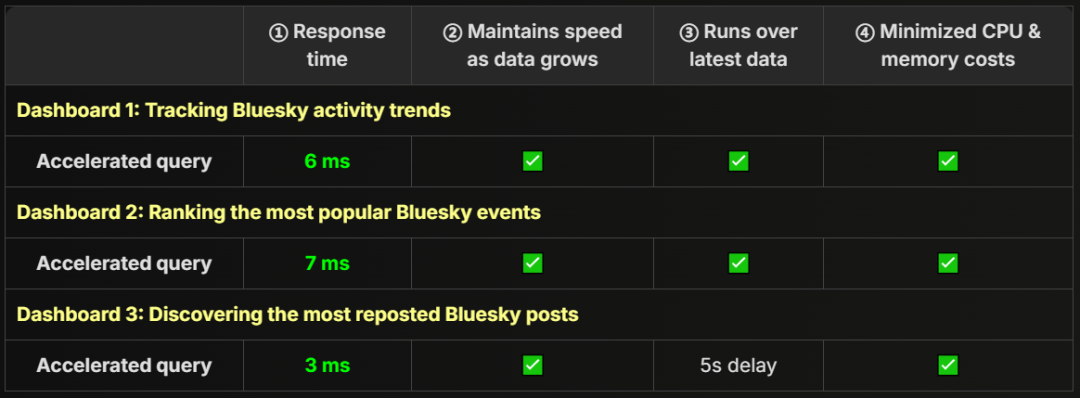
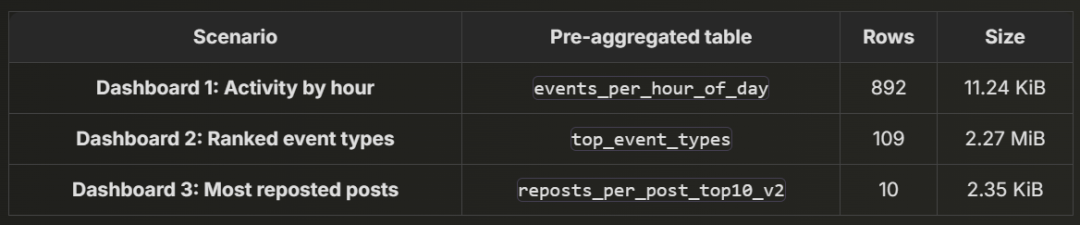
下表展示了我们将要实现的优化效果,证明 ClickHouse 即使在 数十亿 JSON 文档规模下,依然能够保障实时仪表盘的高性能。
在探讨优化方案之前,我们先介绍 Bluesky 数据集及其运行环境。然后,我们将通过三个典型的实时仪表盘场景,详细解析如何在 任何数据规模下 实现并保持 <100ms 的瞬时查询性能。
TL;DR?直接查看关键要点!
如果你想跳过详细过程,直接查看最终结果和优化分析,请前往:
目标达成:稳定实现 <100ms 查询。
我们的示例数据集来源于 Bluesky,这是一组 实时 JSON 事件流,捕获自 知名社交媒体平台。正如我们在另一篇文章中介绍的,该数据集会 持续接收 新的事件,如 帖子、点赞、转发。
如何在 ClickHouse 中存储 Bluesky JSON 数据
下方是 ClickHouse 存储 Bluesky 数据集的表结构,该数据集会 不断增长,并可在 ClickHouse SQL playground 中访问:
CREATE TABLE bluesky.bluesky(kind LowCardinality(String),data JSON,bluesky_ts DateTime64(6))ENGINE = MergeTreeORDER BY (kind, bluesky_ts);
data 列采用 新版 JSON 类型 存储 原始的 Bluesky JSON 文档。
过去,为了加速查询,我们曾将 事件类型 和 事件时间 提取为顶层列,并用于排序。不过,现在已经不需要这样做了,因为 新版 JSON 类型已支持直接使用 JSON 路径作为排序键和主键列。
数据集的规模有多大?
数据摄取始于 去年 12 月下旬。截至 2025 年 3 月,表中已存储 40 亿+ 条 Bluesky 事件 JSON 文档,未压缩数据总量超过 1.6 TiB。
SELECTformatReadableQuantity(sum(rows)) AS docs,formatReadableSize(sum(data_uncompressed_bytes)) AS data_sizeFROM system.partsWHERE active AND (database = 'bluesky') AND (table = 'bluesky');
上述查询结果基于 2025 年 3 月的数据。
┌─docs─────────┬─data_size─┐│ 4.14 billion │ 1.61 TiB │└──────────────┴───────────┘
数据集增长有多快?
目前,该表 每月新增约 15 亿条数据:
SELECTtoStartOfMonth(bluesky_ts) AS month,count() AS docsFROM bluesky.blueskyGROUP BY monthORDER BY month DESCLIMIT 10SETTINGS enable_parallel_replicas=1;
由于 数据摄取始于去年 12 月下旬,该月份的数据量相对较少。 2025 年 2 月只有 28 天,数据量也比其他月份略少。
当前,该表每天新增约 5000 万条 Bluesky 事件:
SELECTtoStartOfDay(bluesky_ts) AS day,count() AS docsFROM bluesky.blueskyWHERE day < toStartOfDay(now())GROUP BY dayORDER BY day DESCLIMIT 10SETTINGS enable_parallel_replicas=1;
如此快速的增长意味着,如果缺乏合理优化,查询速度必然会下降。
那么,如何在数据量持续增长的同时,依然保持实时查询性能? 继续阅读...
或者,直接让博客为你执行查询。
本博客涉及的所有 Bluesky 表、查询加速技术和示例查询,均可在 ClickHouse SQL playground 中运行,您可以自行探索,亲自执行每个示例。
事实上,本博客中的 所有查询 都会 实时执行,让您边阅读边查看查询结果。
我们的 公共 ClickHouse SQL playground 设有限制(如 配额、访问控制、查询复杂度),确保所有用户都能 公平使用资源,防止个别用户占用过多计算能力。因此,高开销查询可能会受限。
为了提供 完整且准确的查询执行统计信息,本博客中的部分查询 由 ClickHouse Cloud playground 上的管理员用户运行,并通过 clickhouse-client 连接到无约束权限环境 执行,以便展示完整结果。
我们的 ClickHouse SQL playground 运行在 ClickHouse Cloud 上,拥有至少 三个计算节点,每个节点配备 59 核 CPU 和 236 GiB 内存。虽然 ClickHouse Cloud 具备 高可用性和可扩展性,但本博客中的 所有仪表盘查询 均运行在 单个计算节点,因为我们 未启用 ClickHouse Cloud 的并行副本。除了 ClickHouse Cloud 采用共享对象存储 这一点外,本博客的查询性能 可与具备类似 CPU 和 RAM 的独立 ClickHouse 实例相媲美。
在接下来的内容中,我们将展示 如何在这种硬件环境下,实现并稳定保持 <100ms 的 ClickHouse 查询响应时间,无论 Bluesky 表的数据量增长到多少亿条 JSON 文档。 我们将通过 三个实时仪表盘场景,逐步解析 查询优化的核心技术。
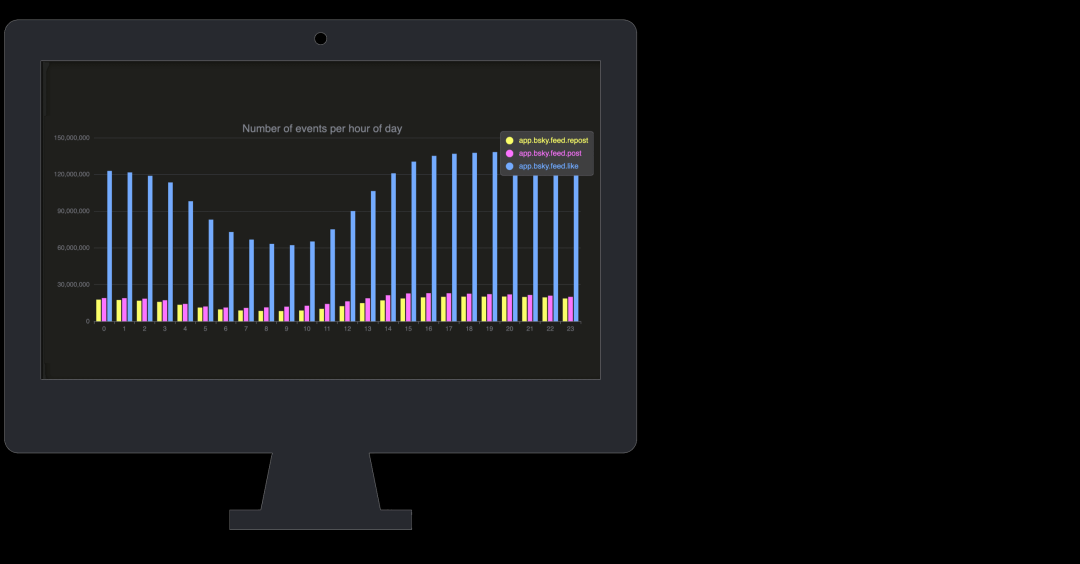
本案例是一个 实时仪表盘,按 小时 统计 最受欢迎的 Bluesky 事件类型,直观展示 一天中用户的活跃时间。
基础查询:按小时统计事件(44 秒)
仪表盘查询逻辑基于 事件类型计数,计算 最受欢迎的 Bluesky 事件:
SELECTdata.commit.collection AS event,toHour(bluesky_ts) AS hour_of_day,count() AS countFROM bluesky.blueskyWHERE kind = 'commit'AND event in ['app.bsky.feed.post','app.bsky.feed.repost','app.bsky.feed.like']GROUP BY event, hour_of_day;
⚠️ 直接运行该查询可能无法顺利执行,因为它 很可能超出 我们 公共 playground 设定的查询时间限制和复杂度阈值。
无限制环境下的查询执行情况:
Elapsed: 44.901 sec. Processed 4.12 billion rows, 189.18 GB (91.84 million rows/s., 4.21 GB/s.)Peak memory usage: 775.96 MiB.
在 ClickHouse Cloud playground 中,通过 clickhouse-client 运行该查询(无查询限制),结果如下:查询耗时:44 秒,内存占用:776 MiB,性能远不能满足仪表盘的实时交互需求。
>2s(过慢)—— 体验不佳,用户容易失去专注。
尽管 ClickHouse 处理 Bluesky JSON 数据的速度 远超 其他主流 JSON 数据存储,但即便在 高性能硬件 上,其最大吞吐量也仅为 91.84M 文档/秒(4.21 GB/s)。
然而,面对 40 亿+ 文档且不断增长的数据量,仅靠全表扫描无法直接实现 <100ms 查询。如果我们能在 新事件到达时 预先 聚合数据,是否就能避免每次查询都扫描数十亿行数据呢?这正是 增量物化视图(incremental materialized views) 发挥作用的关键!
增量聚合如何提升查询速度
要实现 瞬时查询,我们需要 实时增量聚合数据,让 聚合结果随着新的 Bluesky 事件到达而持续更新:
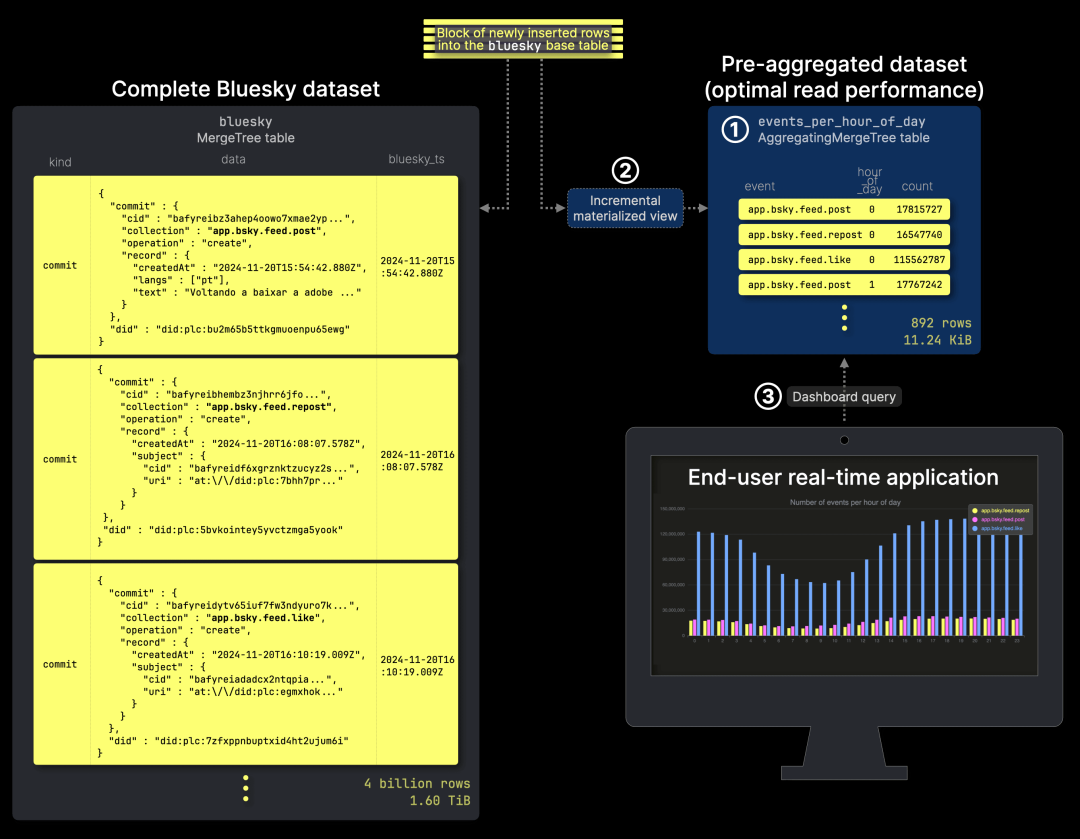
我们将 预聚合的数据 存储在 ① events_per_hour_of_day 表中,③ 该表用于支持仪表盘查询。同时,② 增量物化视图 负责 监测源表数据变更,并自动更新预聚合表,确保数据始终保持最新。
基于 物化视图的增量聚合 极大提升资源利用率,特别是在 源表包含数十亿甚至数万亿行数据 的情况下。与其在每次查询时 重新扫描整个数据集并计算聚合,ClickHouse 采用 增量计算 方法,仅对新插入的数据执行局部聚合,并在后台将这些聚合状态与已有数据增量合并,大幅减少计算开销。
以下是 events_per_hour_of_day 表的 DDL 语句,用于存储 预聚合数据:
CREATE TABLE bluesky.events_per_hour_of_day(event LowCardinality(String),hour_of_day UInt8,count SimpleAggregateFunction(sum, UInt64))ENGINE = AggregatingMergeTreeORDER BY (event, hour_of_day);
同时,以下是 增量物化视图的 DDL 定义。它的核心逻辑是 每当 Bluesky 数据集有新数据插入时,自动触发转换查询,预聚合新增数据后,将结果写入目标表 events_per_hour_of_day,并让 ClickHouse 在后台持续执行增量合并,实现 高效、低延迟的聚合查询。
CREATE MATERIALIZED VIEW bluesky.events_per_hour_of_day_mvTO bluesky.events_per_hour_of_dayAS SELECTdata.commit.collection::String AS event,toHour(bluesky_ts) as hour_of_day,count() AS countFROM bluesky.blueskyWHERE (kind = 'commit')GROUP BY event, hour_of_day;
预聚合对存储的影响
我们来检查 events_per_hour_of_day 目标表的存储占用,当其数据 与 40 亿+ 行 Bluesky 数据集完全同步时——无论是 实时更新,还是 在已有表上新增物化视图后进行回填:
SELECTformatReadableQuantity(sum(rows)) AS rows,formatReadableSize(sum(data_uncompressed_bytes)) AS data_sizeFROM system.partsWHERE active AND (database = 'bluesky') AND (table = 'events_per_hour_of_day');
上述查询结果基于 2025 年 3 月的数据。
┌─rows───┬─data_size─┐│ 892.00 │ 11.24 KiB │└────────┴───────────┘
可以看到,预聚合数据表的存储占用远小于完整的 Bluesky 数据表,无论是 行数 还是 未压缩总数据量。
预聚合数据的存储占用与源表规模无关:物化视图 在 新数据到达时会实时更新目标表,但在数据 完全合并后,表的 行数和总大小将保持恒定,不会随着 完整 Bluesky 数据集的增长 而增加。
这一特性至关重要,它使 ClickHouse 查询能够始终保持 <100ms 的瞬时响应。为什么?因为 物化视图目标表的最大合并后大小,仅取决于唯一的 Bluesky 事件类型数量(当前 109 种) × 每天 24 小时,而不会随着 完整数据集的增长 而增加。
由于 数据规模恒定,优化后的查询执行时间也能保持稳定!
*并非所有事件类型都会出现在一天中的每个小时。
实现 6 毫秒查询性能
现在,我们可以直接在 events_per_hour_of_day 预聚合表 上运行查询:
SELECT event, hour_of_day, sum(count) as countFROM bluesky.events_per_hour_of_dayWHERE event in ['app.bsky.feed.post','app.bsky.feed.repost','app.bsky.feed.like']GROUP BY event, hour_of_dayORDER BY hour_of_day;
查询执行统计(无约束 clickhouse-client):
Elapsed: 0.006 sec.
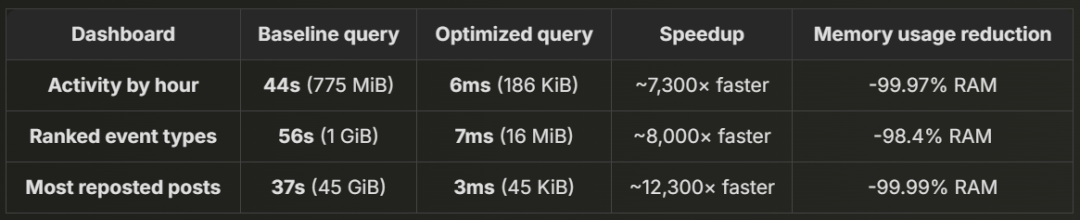
查询时间 从 44 秒缩短至 6 毫秒,完全满足 <100ms“瞬时查询”阈值 的要求。由于 输入表由增量物化视图实时更新,查询始终基于 最新数据 运行,并且 查询时间不会随数据增长而变化。
<100ms(瞬时)—— 适用于筛选和快速更新,用户几乎感觉不到延迟。
内存占用情况(186 KiB vs 776 MiB)
为了更直观地了解 优化后的查询效率,我们可以拆解 从原始 JSON 数据摄取到实时仪表盘查询 的完整数据流。下方示意图展示了整个流程,并详细解析各阶段的 内存占用:
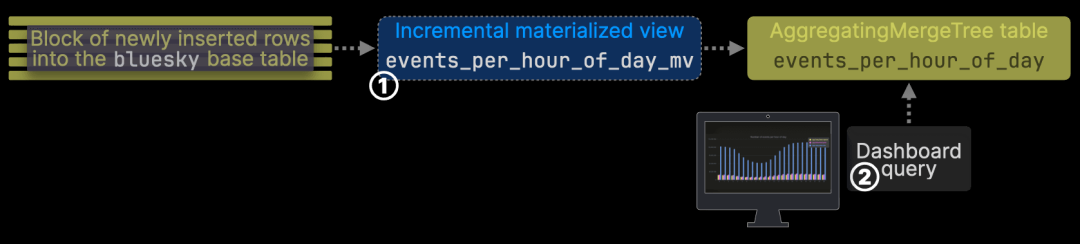
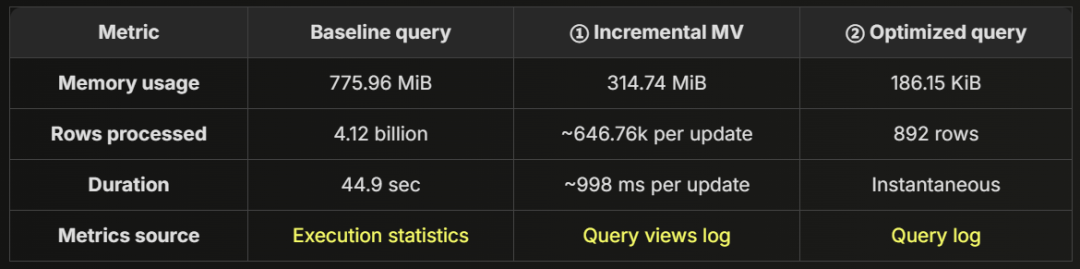
最终查询仅消耗 186 KiB 内存,相比基线查询的 775.96 MiB,减少了 99.98% 的内存占用。即使加上 增量物化视图在处理新数据时使用的 314 MiB,整体内存消耗仍然远低于基线查询,确保了 大规模数据场景下的实时查询能力。
这一结果证明,增量预聚合不仅能显著减少查询延迟和资源占用,还确保了仪表盘在数据规模持续增长时依然保持流畅响应。
在第二个场景中,我们构建了实时仪表盘,按事件类型统计最常见的 Bluesky 事件,并计算 每种事件的唯一用户数。
基础查询:计算唯一用户数(56 秒)
我们在 完整的 Bluesky 数据集 上执行查询,在 仪表盘 1 的 count 聚合 逻辑基础上,新增 uniq 聚合,不仅统计 每个事件的总次数,还计算 涉及的唯一用户数。
SELECTdata.commit.collection AS event,count() AS count,uniq(data.did) AS usersFROM bluesky.blueskyWHERE kind = 'commit'GROUP BY eventORDER BY count DESC;
查询执行统计(无约束 clickhouse-client):
Elapsed: 55.966 sec. Processed 4.41 billion rows, 387.45 GB (78.80 million rows/s., 6.92 GB/s.)Peak memory usage: 1000.24 MiB.
>2s(过慢)—— 体验不佳,用户容易失去专注。
56 秒的查询时间过长,远不能满足实时仪表盘的需求。 为了应对数据增长,同时保持低查询延迟,我们需要更高效的方案。 与其每次查询都扫描完整数据集,不如 通过预聚合构建优化表,提升 实时分析性能。
从慢查询优化到实时分析
与 第一个仪表盘 类似,我们新增 ① top_event_types 预聚合表, ③ 该表用于支持第二个示例仪表盘的查询。 同时,② 增量物化视图 会 监测源表数据变更,并持续更新该表,确保 查询始终基于最新数据 运行:
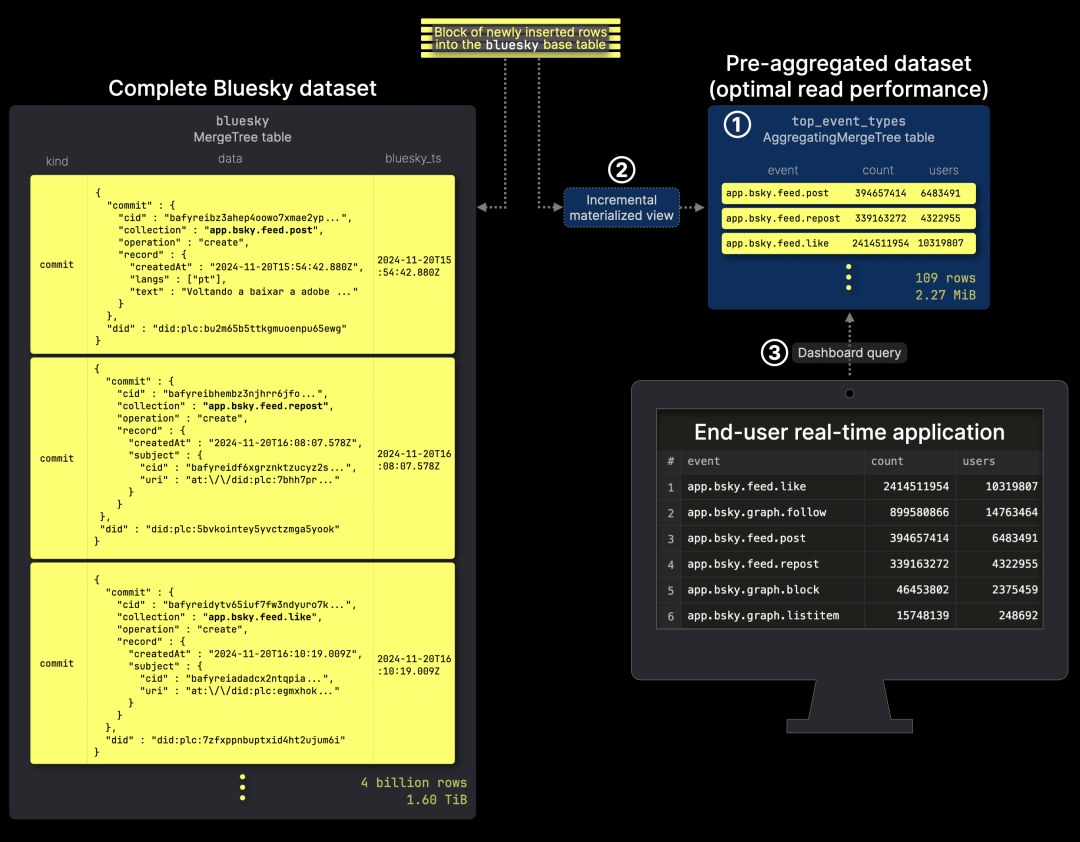
以下是 top_event_types 预聚合表 的 DDL 语句, 用于存储 按事件类型聚合的分析数据:
CREATE TABLE bluesky.top_event_types(event LowCardinality(String),count SimpleAggregateFunction(sum, UInt64),users AggregateFunction(uniq, String))ENGINE = AggregatingMergeTreeORDER BY event;
以下是增量物化视图(incremental materialized view) 的 DDL 语句,该视图用于将预聚合数据写入 top_event_types 表:
CREATE MATERIALIZED VIEW bluesky.top_event_types_mvTO bluesky.top_event_typesASSELECTdata.commit.collection::String AS event,count() AS count,uniqState(data.did::String) AS usersFROM bluesky.blueskyWHERE kind = 'commit'GROUP BY event;
预聚合数据占用多少空间?
我们检查 top_event_types 目标表的大小,当其数据 与 40 亿+ 行的完整 Bluesky 数据集完全同步时:
SELECTformatReadableQuantity(sum(rows)) AS rows,formatReadableSize(sum(data_uncompressed_bytes)) AS data_sizeFROM system.partsWHERE active AND (database = 'bluesky') AND (table = 'top_event_types');
上述查询的静态结果基于 2025 年 3 月的数据。
┌─rows───┬─data_size─┐│ 109.00 │ 2.27 MiB │└────────┴───────────┘
预聚合数据的存储占用不会随源表规模增长而变化 : 同样,目标表在 完全合并后,其 大小和行数 都将 保持恒定, 不受 Bluesky 数据集增长 的影响,它的大小 仅受唯一 Bluesky 事件类型数(当前 109 种)影响。
这一特性保证 无论 Bluesky 数据集如何增长, ClickHouse 查询始终能稳定保持 <100ms 响应时间。
最终优化后查询:7 毫秒响应时间
我们在 top_event_types 预聚合表上执行优化后的查询:
SELECTevent,sum(count) AS count,uniqMerge(users) AS usersFROM bluesky.top_event_typesGROUP BY eventORDER BY count DESC
查询执行统计(无约束 clickhouse-client):
Elapsed: 0.007 sec.
查询时间从 56 秒缩短至 7 毫秒,大幅优化性能。
<100ms(瞬时)—— 适用于筛选或快速更新,用户几乎感觉不到延迟。
优化后查询的内存占用对比(16 MiB vs 1 GiB)
为了直观展示 优化效果,下表对比了 各阶段的内存占用情况,证明增量物化视图如何显著减少查询开销。
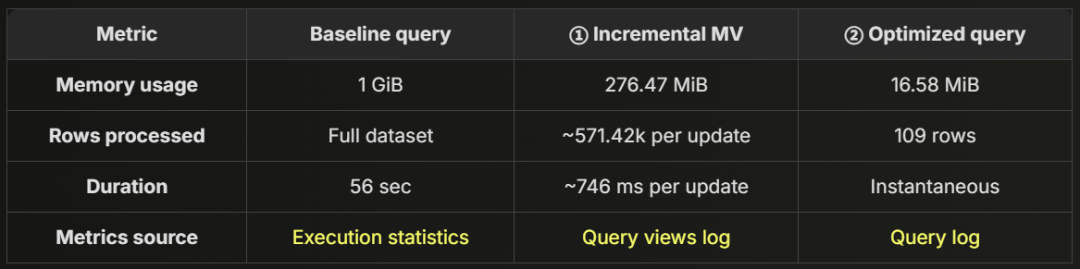
优化后查询仅消耗 16 MiB 内存,相比基线查询的 1 GiB,减少 99% 以上。 即使考虑 增量物化视图处理新数据的 276 MiB,整体内存占用仍显著降低,确保 高效、快速的实时分析能力。
再次证明,增量预聚合不仅能极大减少内存占用,同时保持低查询延迟,让大规模 JSON 数据分析更加高效。
在 第三个场景 中,我们构建了一个 实时仪表盘,用于展示被转发次数最多的 Bluesky 帖子。
识别转发事件的技术挑战
乍一看,找出被转发最多的帖子似乎是个简单问题。 但在实现过程中,我们需要解决几个关键难题:
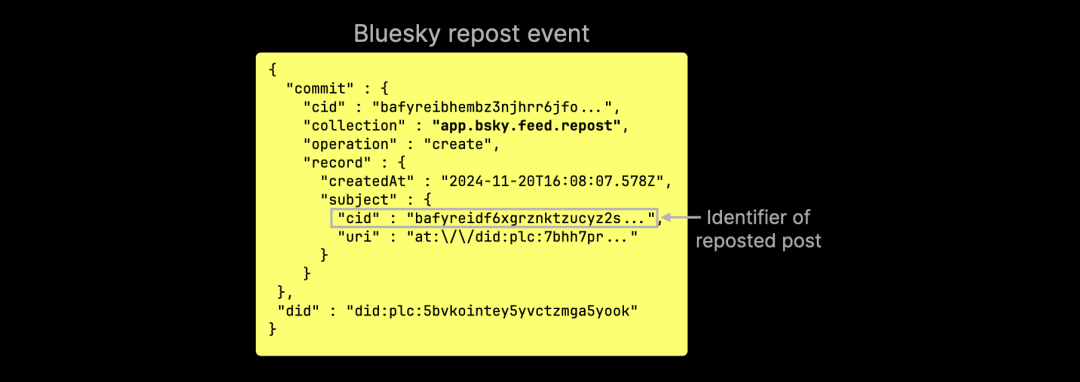
1. 转发事件不包含原始帖子的内容:转发事件仅存储原帖的 CID(内容标识符),但不会携带任何文本信息:
2. 计算转发次数的开销较大:必须对高基数 JSON 字段 `cid` 进行聚合,这会显著拖慢查询速度。
3. 帖子不包含用户的用户名或句柄:Bluesky 事件 JSON 仅记录 DID(去中心化标识符),而不会存储用户的实际名称:
在优化之前,我们先来看一个 基础查询,用于查找最热门的转发帖子。
为什么转发查询如此缓慢?(基线查询:37 秒)
在优化之前,我们先执行一个基础查询,获取 转发次数最多的前 10 篇帖子,之后再解决补充帖子内容和将 DID 映射到用户名 这两个问题。
SELECTdata.commit.record.subject.cid AS cid,count() AS repostsFROM bluesky.blueskyWHERE data.commit.collection = 'app.bsky.feed.repost'GROUP BY cidORDER BY cid DESCLIMIT 10;
查询执行统计(无约束 clickhouse-client):
Elapsed: 37.234 sec. Processed 4.14 billion rows, 376.91 GB (111.26 million rows/s., 10.12 GB/s.)Peak memory usage: 45.43 GiB.
>2s(过慢)—— 体验不佳,用户容易失去专注。
很明显,这种查询方式 过于缓慢。由于 `cid` 是高基数 JSON 字段,查询耗时 37 秒,内存占用 45 GiB,远远达不到实时仪表盘的性能要求。要提升转发查询的效率,我们需要更优的解决方案。
与之前的优化方案一致,我们在 ① reposts_per_post 表中存储和更新 预聚合数据,③ 该表作为仪表盘查询的输入。同时,② 增量物化视图会实时更新该表,确保数据始终与源表同步:
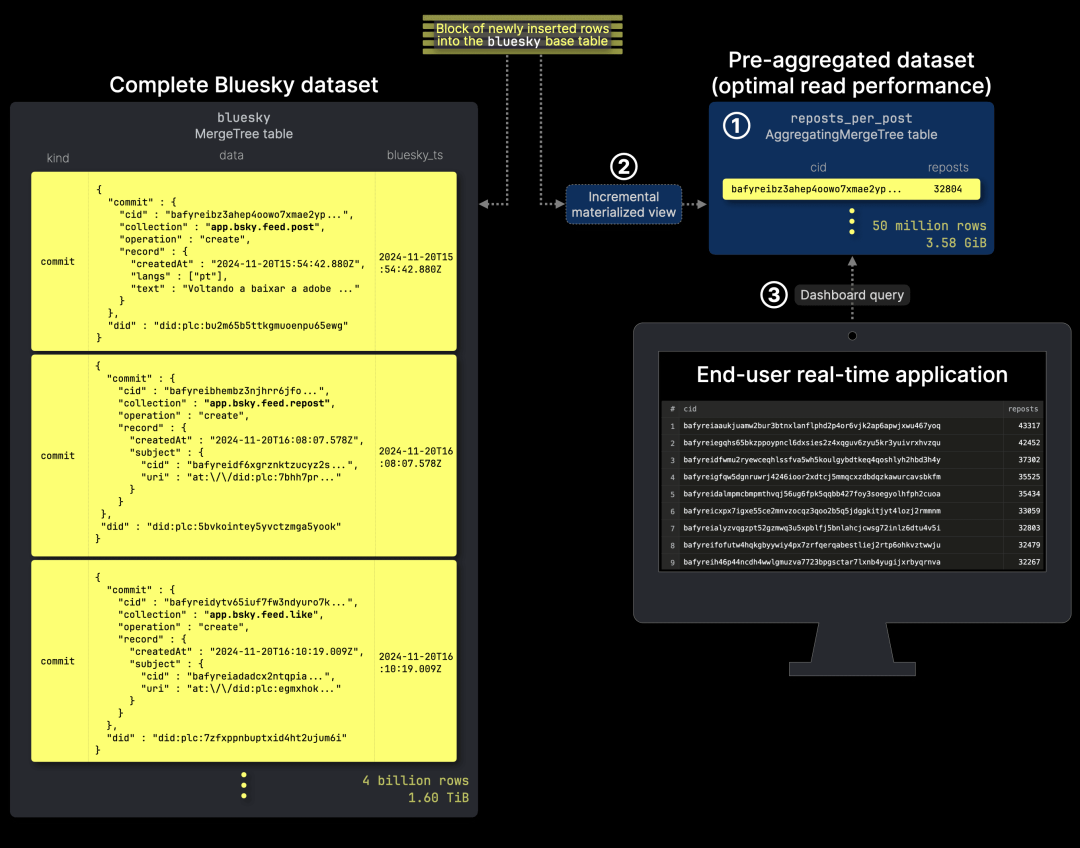
以下是 reposts_per_post 目标表及其增量物化视图 的 DDL 定义:
CREATE TABLE bluesky.reposts_per_post(cid String,reposts SimpleAggregateFunction(sum, UInt64))ENGINE = AggregatingMergeTreeORDER BY (cid);
CREATE MATERIALIZED VIEW bluesky.reposts_per_post_mv TO bluesky.reposts_per_postASSELECTdata.commit.record.subject.cid::String AS cid,count() AS repostsFROM bluesky.blueskyWHERE data.commit.collection = 'app.bsky.feed.repost'GROUP BY cid;
预聚合数据的存储占用分析
我们检查 reposts_per_post 目标表的大小,当其数据 与 40 亿+ 行的完整 Bluesky 数据集完全同步时:
SELECTformatReadableQuantity(sum(rows)) AS rows,formatReadableSize(sum(data_uncompressed_bytes)) AS data_sizeFROM system.partsWHERE active AND (database = 'bluesky') AND (table = 'reposts_per_post');
上述查询的静态结果基于 2025 年 3 月的数据。
┌─rows──────────┬─data_size─┐│ 50.62 million │ 3.58 GiB │└───────────────┴───────────┘
注意:增量物化视图的目标表 比完整的 Bluesky 数据表小,但仍然占据大量存储空间,且行数较多。
在本场景中,预聚合数据的大小仍然取决于源表规模:尽管增量物化视图可预计算转发次数,但目标表的大小仍随源数据集增长,其行数和存储占用会随着帖子和转发数量的增加而扩展。
这一增长会影响查询性能,但稍后我们将介绍 一种优化方案,来降低存储增长对查询性能的影响。
我们在 reposts_per_post 预聚合表 上执行优化后的查询:
SELECTcid,sum(reposts) AS repostsFROM bluesky.reposts_per_postGROUP BY cidORDER BY reposts DESCLIMIT 10;
查询执行统计(无约束 clickhouse-client):
Elapsed: 1.732 sec. Processed 50.62 million rows, 3.85 GB (29.23 million rows/s., 2.22 GB/s.)Peak memory usage: 9.66 GiB.
即使采用预聚合数据,查询仍未达到瞬时响应。虽然相比 37 秒和 45 GiB 内存占用 已有大幅优化,但仍 未能达到 <100ms ‘瞬时查询’ 的标准。
1s - 2s(缓慢但可接受)—— 体验略显迟滞,建议使用加载指示器。
正如前文所述,物化视图的目标表会随基础数据集一起扩展。
因此,即便查询的是预聚合数据,随着 Bluesky 数据集增长,查询速度仍将不断变慢。
更智能的优化方案。我们真的需要 统计每篇帖子的转发数吗?不,我们只关心最热门的 N 篇帖子。然而,增量物化视图并不适用于维护 top-N 结果,但我们可以利用 可刷新(refreshable)物化视图 高效管理最热门的帖子,确保仅保留最热门的转发帖子,以进一步优化查询性能。
优化性能瓶颈:更高效的方法
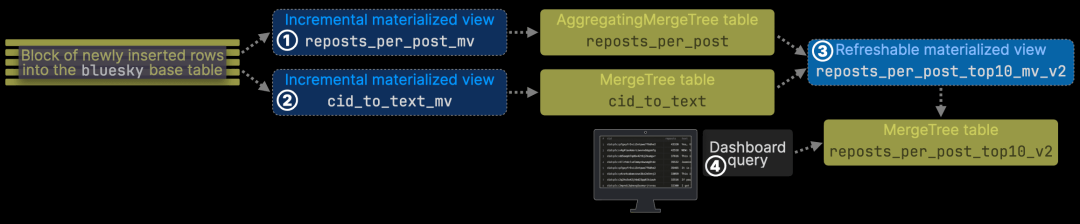
我们保留了 reposts_per_post 表及其增量物化视图,并新增 ① 一个定期刷新的物化视图,用于维护 ② 精简的 reposts_per_post_top10 表,该表 ③ 作为仪表盘查询的数据源。此表会定期原子更新,不影响正在运行的查询,仅包含当前转发次数最多的前 10 篇帖子:
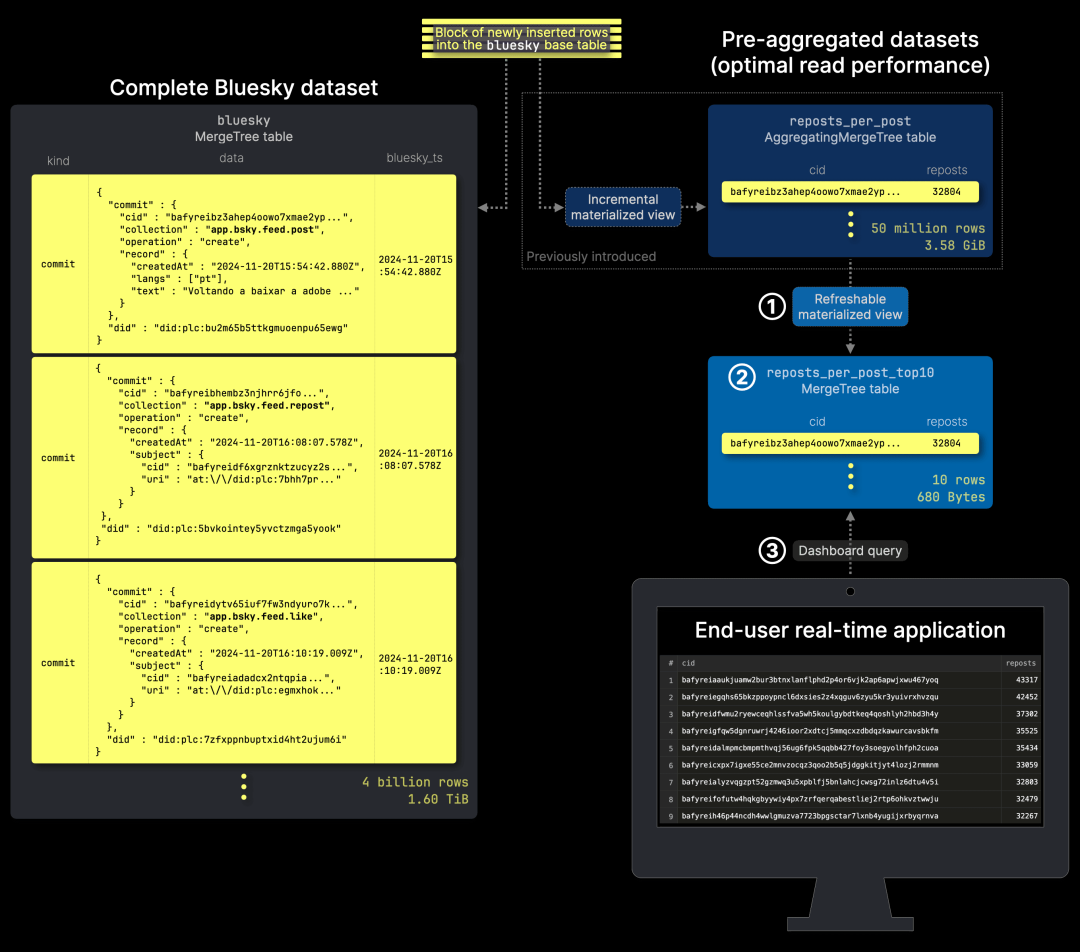
reposts_per_post_top10 的 DDL 语句与 reposts_per_post 相同:
CREATE TABLE bluesky.reposts_per_post_top10(cid String,reposts UInt64)ENGINE = MergeTreeORDER BY ();
以下是该可刷新的物化视图的定义:
CREATE MATERIALIZED VIEW bluesky.reposts_per_post_top10_mvREFRESH EVERY 10 MINUTE TO bluesky.reposts_per_post_top10ASSELECTcid,sum(reposts) AS repostsFROM bluesky.reposts_per_postGROUP BY cidORDER BY reposts DESCLIMIT 10;
我们将其配置为每 10 分钟刷新一次。
增量物化视图可实时更新目标表,使其与源数据保持同步,而可刷新的物化视图则按固定间隔更新,最短间隔由查询执行时间决定。
如果直接在完整数据集上执行此查询,需要 37 秒,并占用 45 GiB 内存,开销过大,不适合频繁执行。
然而,查询 reposts_per_post 这一预聚合表,仅需 1.7 秒即可完成相同的计算,并仅占用 10 GiB 内存,大幅降低了资源消耗。
通过结合使用可刷新的物化视图和增量物化视图,我们有效提升了资源利用效率。
精简数据,实时查询
现在,核心优化来了——正如预期的那样,reposts_per_post_top10 表即使与包含 40 亿+ 行的 Bluesky 数据集保持完全同步,其数据量始终固定在 10 行,总计仅 680 字节:
SELECTformatReadableQuantity(sum(rows)) AS rows,formatReadableSize(sum(data_uncompressed_bytes)) AS data_sizeFROM system.partsWHERE active AND (database = 'bluesky') AND (table = 'reposts_per_post_top10');
上述查询的静态结果(截至 2025 年 3 月):
┌─rows──┬─data_size─┐│ 10.00 │ 680.00 B │└───────┴───────────┘
预聚合数据的大小不会受源表增长影响:与前两个仪表盘示例类似,目标表的大小和行数始终固定为 10 行,总计 680 字节,无论原始 Bluesky 数据集如何扩展,都不会影响它的存储大小。
最终的优化成果——在 reposts_per_post_top10 这个紧凑表(始终仅 10 行)上运行查询,可确保始终毫秒级(<100ms)返回结果:
SELECT *FROM bluesky.reposts_per_post_top10ORDER BY reposts DESC;
通过 clickhouse-client 查询的执行统计信息(无查询限制):
Elapsed: 0.002 sec.
<100ms(毫秒级响应)——查询速度极快,非常适合过滤或快速更新。
内存占用对比:28 KiB vs 45 GiB
为了直观展示优化方案如何大幅降低内存占用,下面的表格对比了三个关键组件的内存消耗情况。

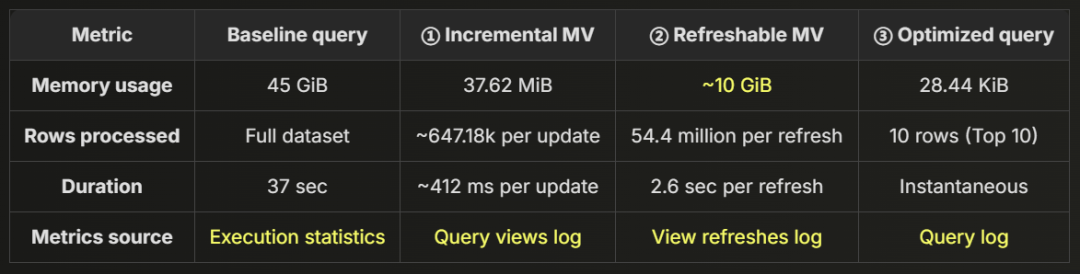
即使在峰值负载下,所有组件的总内存消耗仍然远低于原始的 45 GiB 基线,充分证明了该方法的高效性。
正如前面提到的,这一场景带来了额外挑战:仪表盘需要展示 Bluesky 中被转发最多的帖子,但转发事件仅包含帖子标识符(CID),而不包含实际的帖子内容。
为了解决这一问题,我们采用了以下优化方案:
1. 创建 ① 一个增量物化视图,用于预填充 ② cid_to_text 表,该表存储每条新帖子的内容,并针对 CID 快速查找进行了优化。
2. 扩展可刷新的物化视图,使其利用该表,从而高效地 ③ 进行 join 操作,检索并存储前 10 篇转发最多的帖子的文本内容,并写入 reposts_per_post_top10 这一精简表,④ 作为仪表盘查询的数据源。
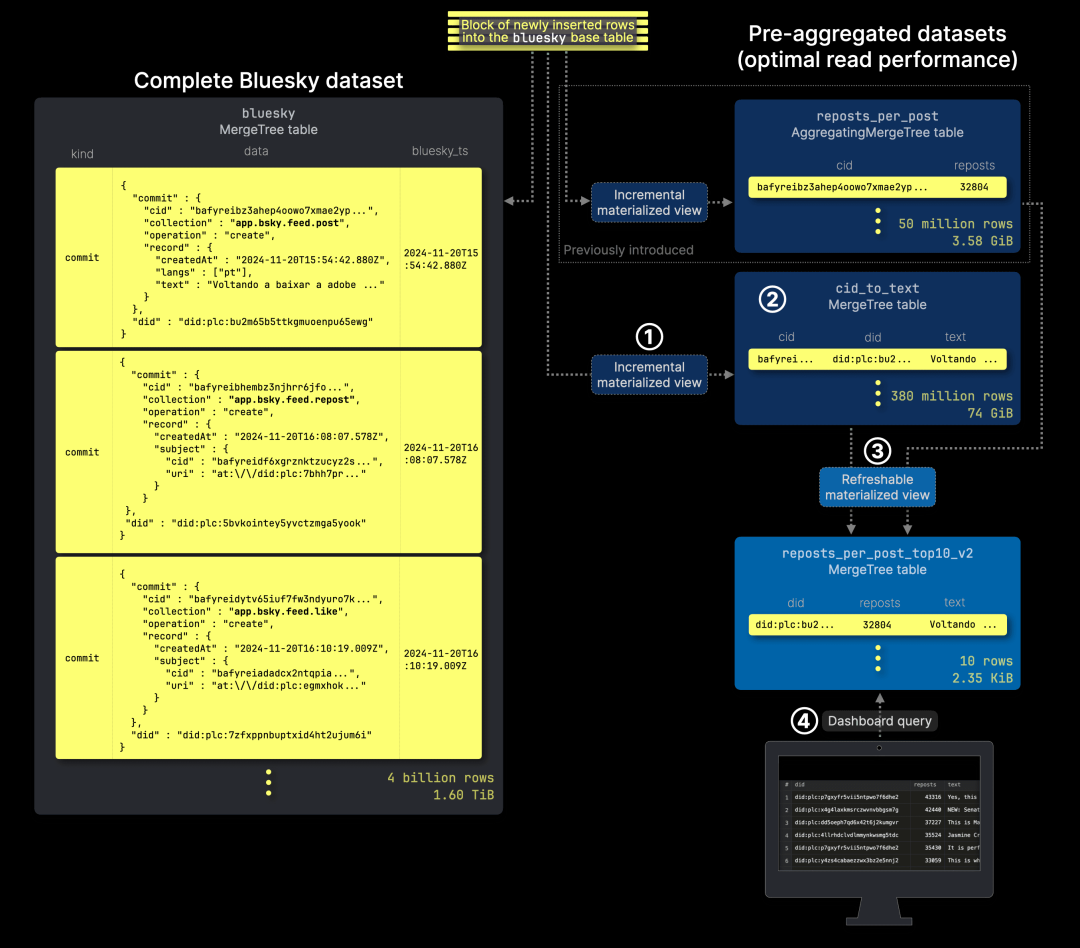
完整的 Bluesky 数据集表采用 (kind, bluesky_ts) 作为主键,这种设计并不适用于基于 CID 的快速帖子内容查找,尤其是在数据量达数十亿行的情况下。为此,我们创建了专门的 cid_to_text 表,并优化了其主键,以提升基于 CID 的文本检索效率。
CREATE TABLE bluesky.cid_to_text(cid String,did String,text String)ENGINE = MergeTreeORDER BY (cid);
以下是用于同步 cid_to_text 表的增量物化视图 DDL 语句,该视图会在有新帖子发布时自动更新表中的内容:
CREATE MATERIALIZED VIEW bluesky.cid_to_text_mvTO bluesky.cid_to_textASSELECTdata.commit.cid AS cid,data.did AS did,data.commit.record.text AS textFROM bluesky.blueskyWHERE (kind = 'commit') AND (data.commit.collection = 'app.bsky.feed.post');
需要注意的是,cid_to_text 表的大小会随着完整的 Bluesky 数据集增长。然而,由于它仅供可刷新的物化视图定期查询,且不要求低延迟响应,因此这种依赖关系是可接受的,不会影响实时仪表盘的性能。
通过优化帖子内容查找提升 `join` 效率
在介绍最终的可刷新的物化视图 DDL 之前,先来看它所用到的 join 查询。该查询通过连接两个优化后的表来识别转发次数最多的前 10 篇帖子,并补充其文本内容:reposts_per_post 预聚合表(作为 join 左侧) ,cid_to_text 专用表(作为 join 右侧,用于根据左侧的 CID 获取文本内容)
WITH top_reposted_cids AS(SELECTcid,sum(reposts) AS repostsFROM bluesky.reposts_per_postGROUP BY cidORDER BY reposts DESCLIMIT 10)SELECTt2.did AS did,t1.reposts AS reposts,t2.text AS textFROM top_reposted_cids AS t1LEFT JOIN bluesky.cid_to_text AS t2ON t1.cid = t2.cid;
查询执行统计(通过 clickhouse-client 无查询限制获取):
Elapsed: 295.427 sec. Processed 379.42 million rows, 85.14 GB (1.28 million rows/s., 288.18 MB/s.)Peak memory usage: 126.77 GiB.
显然,这样的性能表现远远不理想。
问题在于,当前的 join 查询优化器尚未能自动将左侧表的过滤条件下推至右侧表。但我们可以手动优化 join,并利用右侧表的主键提升查询性能,使查询执行更加高效。
WITH top_reposted_cids AS(SELECTcid,sum(reposts) AS repostsFROM bluesky.reposts_per_postGROUP BY cidORDER BY reposts DESCLIMIT 10)SELECTt2.did AS did,t1.reposts AS reposts,t2.text AS textFROM top_reposted_cids AS t1LEFT JOIN(SELECT *FROM bluesky.cid_to_textWHERE cid IN (SELECT cid FROM top_reposted_cids)) AS t2 ON t1.cid = t2.cid;
通过未受限制的 clickhouse-client 查询执行统计信息:
Elapsed: 3.681 sec. Processed 102.37 million rows, 7.78 GB (27.81 million rows/s., 2.11 GB/s.)Peak memory usage: 9.91 GiB.
在连接(join)查询中,先使用前 10 个被转发最多的帖子对应的 CID 预过滤大型 cid_to_text 表(作为连接的右表)。这一优化充分利用了表的主键,使查询时间从 300 秒缩短至 3.6 秒,内存消耗从 127 GiB 降至 9.91 GiB。
高效维护前 10 个被转发最多的帖子
我们基于上述连接查询,构建了一个可刷新的物化视图(refreshable materialized view)。该视图会定期更新目标表,存储前 10 个被转发最多的帖子及其文本,并包含原作者的 DID。
CREATE TABLE bluesky.reposts_per_post_top10_v2(did String,reposts UInt64,text String)ENGINE = MergeTreeORDER BY ();
以下是该可刷新的物化视图的 DDL 语句:
CREATE MATERIALIZED VIEW bluesky.reposts_per_post_top10_mv_v2REFRESH EVERY 10 MINUTE TO bluesky.reposts_per_post_top10_v2ASWITH top_reposted_cids AS(SELECTcid,sum(reposts) AS repostsFROM bluesky.reposts_per_postGROUP BY cidORDER BY reposts DESCLIMIT 10)SELECTt2.did AS did,t1.reposts AS reposts,t2.text AS textFROM top_reposted_cids AS t1LEFT JOIN(SELECT *FROM bluesky.cid_to_textWHERE cid IN (SELECT cid FROM top_reposted_cids)) AS t2 ON t1.cid = t2.cid;
最终聚合数据的规模
如预期所示,当 reposts_per_post_top10_v2 表与包含 40 亿行完整 Bluesky 数据集的表保持同步时,它始终只包含 10 行数据,总大小仅为 2.35 KiB。
SELECTformatReadableQuantity(sum(rows)) AS rows,formatReadableSize(sum(data_uncompressed_bytes)) AS data_sizeFROM system.partsWHERE active AND (database = 'bluesky') AND (table = 'reposts_per_post_top10_v2');
上述查询在 2025 年 3 月的静态查询结果:
┌─rows──┬─data_size─┐│ 10.00 │ 2.35 KiB │└───────┴───────────┘
最终优化查询:3 毫秒响应时间,即时返回结果
在紧凑型 reposts_per_post_top10_v2 表(仅 10 行数据)上运行查询,可确保始终获得瞬时响应时间:
SELECT *FROM bluesky.reposts_per_post_top10_v2ORDER BY reposts DESC;
通过未受限制的 clickhouse-client 查询执行统计信息:
Elapsed: 0.003 sec.
<100ms(近乎瞬时)— 适用于筛选或快速更新。
优化后的查询内存使用情况(45 KiB vs 45 GiB)
我们的优化方案包含四个关键组件,每个组件都在显著降低内存消耗的同时,保持实时性能。

这四个组件的总内存占用分别为 37.62 MiB、327.70 MiB、10 GiB 和 45.71 KiB,远低于基线查询的 45 GiB。
目前的第三个实时仪表盘场景涉及两个关键挑战:
高效的 top-N 检索:单独使用增量物化视图(incremental materialized views)仍然不足,因此需要可刷新的物化视图(refreshable materialized view)来维护转发最多的 N 篇帖子。
丰富转发数据:由于转发事件仅包含帖子标识符(CID),而不包括文本,因此需要通过表连接来检索完整的帖子内容。
但仍有一个缺失环节——当前仪表盘按 DID 显示转发数据,这样的展示方式不够直观。接下来,我们将在实时环境下将 DID 映射到实际的用户句柄。
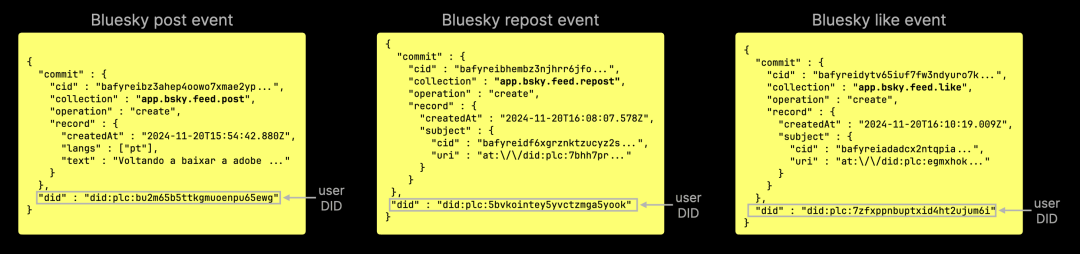
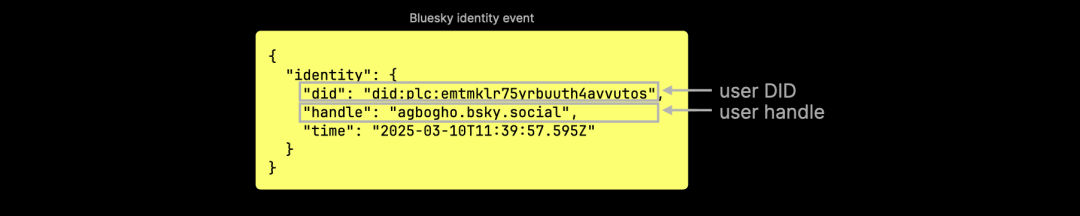
在 Bluesky 生态中,帖子、转发、点赞等事件的 JSON 数据中,仅包含用户的 DID,而不包含用户名或句柄:
与 DID 不同,用户句柄和名称可能会因身份变更事件而随时发生变化:
幸运的是,ClickHouse 提供了一个完美的解决方案:可更新的内存字典(updatable in-memory dictionaries),能够高效地进行实时查找,并支持无缝更新。
字典(Dictionaries)是 ClickHouse 的核心功能之一,它可以将不同数据源的信息存储为内存中的键值对,并针对超低延迟查询进行了优化。
下图展示了在仪表盘场景下,如何创建并加载内存字典(in-memory dictionary),以支持动态元数据(如用户句柄)的高效实时查找,使仪表盘能够在查询时动态更新数据,保持最新状态:
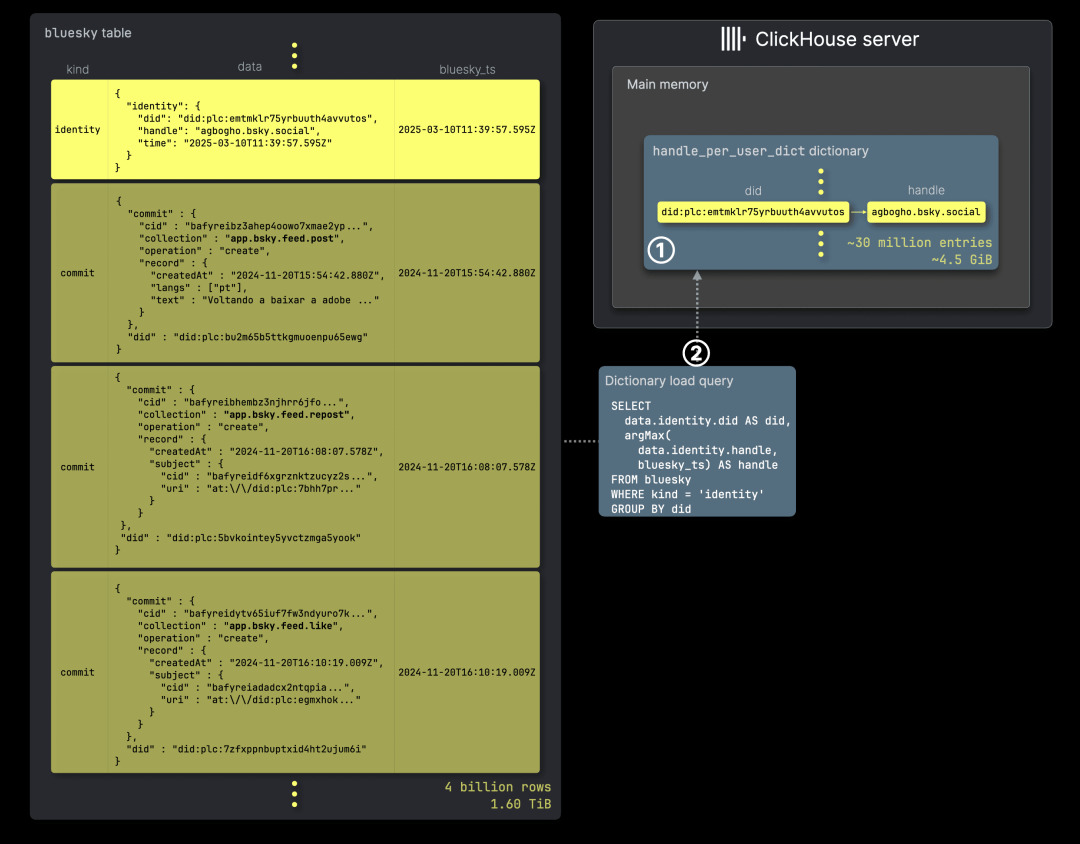
我们创建了 ① handle_per_user_dict 字典,用于将持久的 Bluesky 用户标识符(DID)映射到其最新的用户句柄。当用户更改其句柄时,Bluesky API 会流式传输一个身份 JSON 文档。通过按 DID 归类,我们在 ClickHouse 中使用 argMax 聚合函数,从最新的身份文档中提取用户句柄,并构建 ② 字典加载查询(dictionary load query)。
与可刷新的物化视图类似,字典可以通过定期执行加载查询进行原子化更新,确保查询性能不受影响。
然而,为了避免在持续扩大的 40 亿行 Bluesky 数据集上重复运行 argMax 聚合,我们引入了一项优化方案,如下图所示:
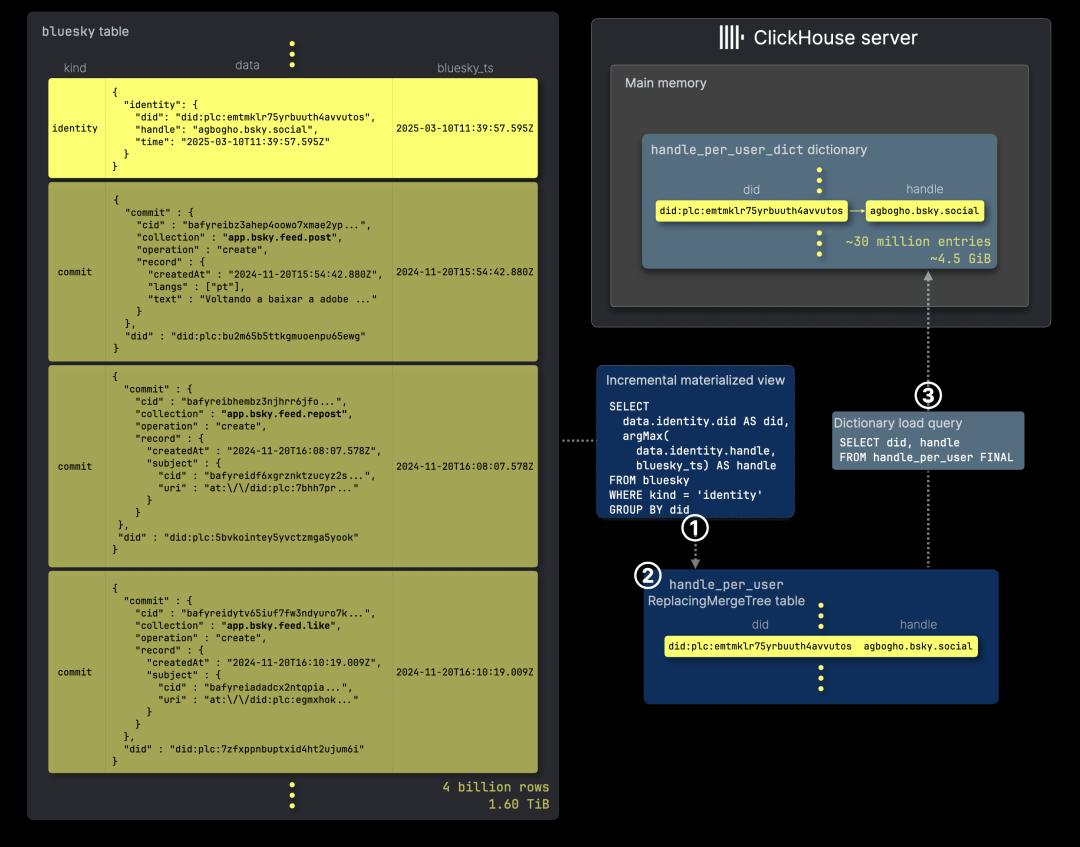
我们新增了 ① 一个增量物化视图(incremental materialized view),该视图仅对新插入的数据块执行 argMax 聚合,并将预聚合的数据存储在 ② ReplacingMergeTree 表 中。该表的后台合并机制确保每个唯一 DID 仅保留最新的句柄。字典的 ③ 加载查询(load query) 直接作用于这个较小的表,并使用 FINAL 修饰符在查询时合并未完成的数据部分,确保查询结果始终最新。
接下来,我们将提供 DDL 语句来配置该方案。
增量物化视图目标表的 DDL 语句:
CREATE TABLE bluesky.handle_per_user(did String,handle String)ENGINE = ReplacingMergeTreeORDER BY (did);
增量物化视图的 DDL 语句:
CREATE MATERIALIZED VIEW bluesky.handle_per_user_mvTO bluesky.handle_per_userASSELECTdata.identity.did::String AS did,argMax(data.identity.handle, bluesky_ts) AS handleFROM bluesky.blueskyWHERE (kind = 'identity')GROUP BY did;
最后,我们通过查询物化视图的目标表来创建 内存字典(in-memory dictionary),并设定自动更新的时间间隔(秒级)。ClickHouse 在此时间范围内随机分配更新时间,以平衡大规模集群的更新负载:
CREATE DICTIONARY bluesky.handle_per_user_dict(did String,handle String)PRIMARY KEY (did)SOURCE(CLICKHOUSE(QUERY $query$SELECT did, handleFROM bluesky.handle_per_user FINAL$query$))LIFETIME(MIN 300 MAX 360)LAYOUT(complex_key_hashed());
需要注意的是,字典的加载策略取决于 dictionaries_lazy_load 设置,它可以在服务器启动时加载,也可以在首次查询时动态加载。
此外,用户可以手动运行 SYSTEM 命令触发字典加载。当与 ON CLUSTER 语句结合使用时,可确保云服务中的所有计算节点同步加载字典到内存中:
SYSTEM RELOAD DICTIONARY bluesky.handle_per_user_dict ON cluster default;
现在,该字典已准备就绪,可在仪表盘查询中即时用于 DID 到用户句柄的映射,例如:
SELECT dictGet('bluesky.handle_per_user_dict', 'handle', 'did:plc:emtmklr75yrbuuth4avvutos') AS handle;
上述查询的静态结果(2025 年 3 月):
┌─handle──────────────┐│ agbogho.bsky.social │└─────────────────────┘1 row in set. Elapsed: 0.001 sec.
最终查询:实时用户句柄的转发排行榜(3 毫秒响应)
所有组件就位后,我们可以运行最终的仪表盘查询 3,使用字典来获取前 10 个被转发最多的帖子对应的 DID 的最新用户句柄。
SELECTdictGetOrDefault('bluesky.handle_per_user_dict','handle', did, did) as user,reposts,textFROM bluesky.reposts_per_post_top10_v2ORDER BY reposts DESC;
查询执行统计信息(通过未受限制的 clickhouse-client 获取):
Elapsed: 0.003 sec.
请注意,我们使用 dictGetOrDefault 函数,如果字典中未找到对应映射,则返回原始 DID。
理论上,该字典可以包含所有 Bluesky 用户的映射记录,目前约有 3000 万 用户。然而,由于我们从 2024 年 12 月 开始实时摄取 Bluesky 事件数据,因此字典仅包含自该日期以来记录的 句柄或名称变更 事件。
截至 2025 年 3 月,字典已包含 约 800 万条 记录,占用 1.12 GiB 内存(通过 clickhouse-client 查询)。
SELECTstatus,element_count AS entries,formatReadableSize(bytes_allocated) AS memory_allocated,formatReadableTimeDelta(loading_duration) AS loading_durationFROM system.dictionariesWHERE database = 'bluesky' AND name = 'handle_per_user_dict';
┌─status─┬─entries─┬─memory_allocated─┬─loading_duration─┐│ LOADED │ 7840778 │ 1.12 GiB │ 4 seconds │└────────┴─────────┴──────────────────┴──────────────────┘
如果用户数量增长至 3000 万,我们预计字典的大小将达到 约 4.5 GiB。
如果 Bluesky 用户数量持续增长,我们可能需要重新考虑是否继续使用内存字典。
字典使用的内存开销
为了高效维护最新字典,同时避免扫描完整的 40 亿行数据集,我们引入了 增量物化视图(incremental materialized view) 来预聚合句柄变更数据。字典本身通过 加载查询(load query) 进行定期刷新,以减少计算开销。


即使在计算内存开销时包含字典及其更新,再加上之前优化的仪表盘查询,总体内存使用量仍然远低于 45 GiB 的基线查询。
通过合理设计 增量更新机制 和 周期性字典刷新,我们成功实现了 高效、低延迟的查找,避免了 完整数据扫描 带来的内存负担。
现在,让我们回顾这些优化在 三个仪表盘场景 中的整体影响。
经过优化,我们的仪表盘查询现在始终能够在 100 毫秒以内 完成,无论数据量如何增长,即便在 中等配置的硬件 上依然高效。秘诀是什么?确保查询始终运行在小型、稳定且预聚合的数据上。
尽管我们处理着 40 亿+ 条 JSON 数据,并且每月新增 15 亿 条,我们的输入表依然保持紧凑:
如何加速大规模查询?
关键优化思路:避免扫描完整数据集,同时确保数据始终最新。
仪表盘 1 & 2:增量物化视图(incremental materialized views)实时更新 预聚合表,以保持高效查询。
仪表盘 3:可刷新的物化视图(refreshable materialized view)仅维护 top-N 结果,确保查询高效执行。
这种优化方式使得 无论数据规模如何增长,仪表盘查询始终在小型、稳定、最新的数据表上运行。
从低效到高效:优化前后对比
ClickHouse 用户的关键优化策略
✅ 增量物化视图:适用于 独立于源表增长 的预聚合数据,确保低延迟查询。
✅ 可刷新的物化视图:与增量物化视图结合使用,可维护 小型且稳定的 top-N 查询输入,在数据新鲜度与查询性能之间取得平衡。
✅ 内存字典:提供 实时元数据查找,进一步优化仪表盘查询体验。
通过 确保输入表始终小型且不受数据集规模影响,ClickHouse 能够在 任何数据规模下都保持实时 JSON 分析的高性能。

我们正为深圳活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。

/END/
 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


