




在 Kubernetes 集群中,CoreDNS 是一个关键组件,负责集群内的 DNS 解析。然而,有时会出现 CoreDNS 解析超时的问题,导致服务请求响应缓慢甚至失败。本文将详细介绍如何排查和解决 CoreDNS 解析超时的问题,确保集群的稳定运行。

生产环境,我们始终怀有敬畏
风和日丽的一天,突然企微群收到报障。业务容器出现频繁解析域名失败。

Tip:从截图来看,一个服务(多个副本)在一秒钟内发生10次域名解析失败。
1、查看coredns日志,日志打印i/o timeout日志。当出现这个字眼。则说明coredns转发给上游dns服务器(100.x.x.1)后没有收到域名解析结果

2、分析coredns超时时间
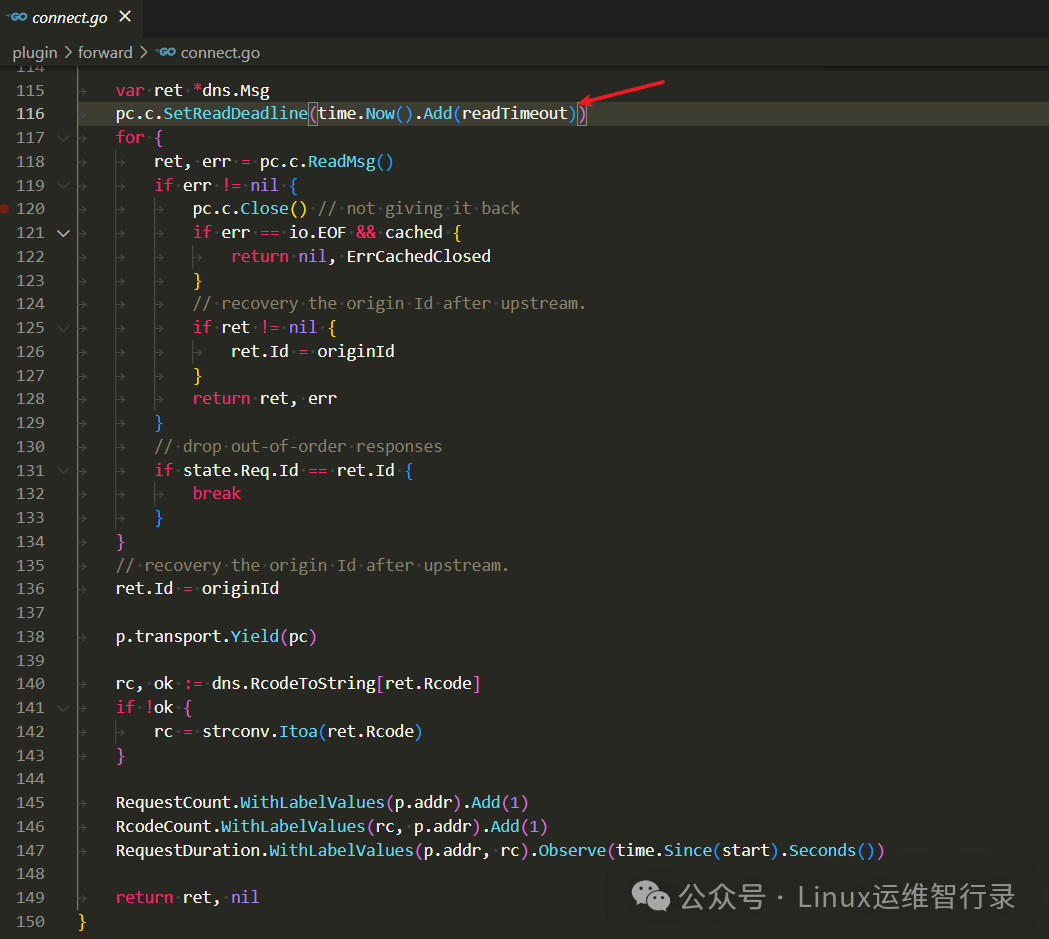
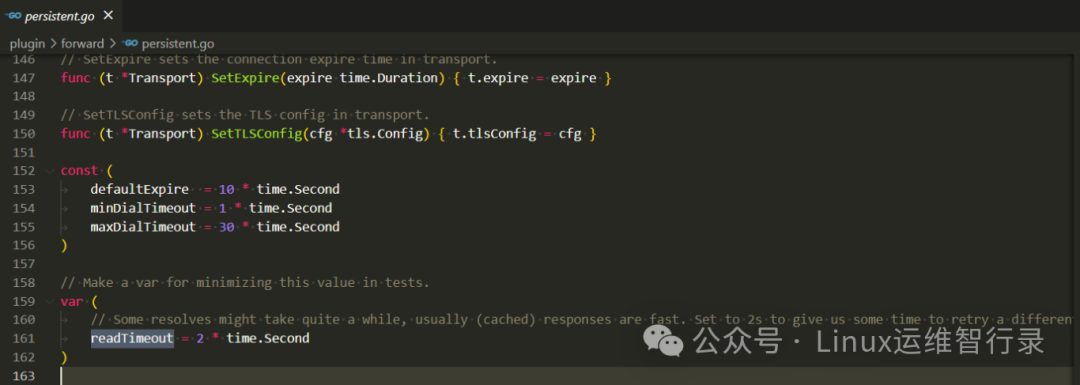
Tip:代码分析结果,coredns 1.10.1版本转发给上游dns服务器,如果2秒钟没有响应结果,则认为解析超时
4、找内网dns(100.x.x.1)定位问题
如上述代码分析,可知内网dns服务器2秒内没有返回结果。找到内网dns维护者反馈该问题,最后答复公网域名2秒内是可能出现还未解析到域名,以及内网dns服务不承诺SLA服务的
解决方案如下:
1、将超时时间改造成可配置参数重新编译镜像,使用重新编译后的镜像并将超时时间设置成5s。
2、将上游dns改成阿里云dns服务器,配置文件将forward 上游地址改成阿里云dns服务器。
3、集群内部署localdns服务
dns解析先到localdns服务,localdns没有缓存记录,则转发给coredns;如果localdns有缓存记录,则直接将记录返回给客户端。有效减少coredns服务的压力。
业务容器resolve.conf文件option attempts重试参数,底层libc库会自动重试dns解析失败的情况
上面解决措施都是优化手段。问题根源是出现2s内不能解析到域名结果,出现这种情况可能如下可能性:
1、递归解析dns域名耗时过大
2、coredns解析域名的网络链路存在丢包
别忘了,关注我们的公众号,获取更多关于容器技术和云原生领域的深度洞察和技术实战,让我们携手在技术的海洋中乘风破浪!

