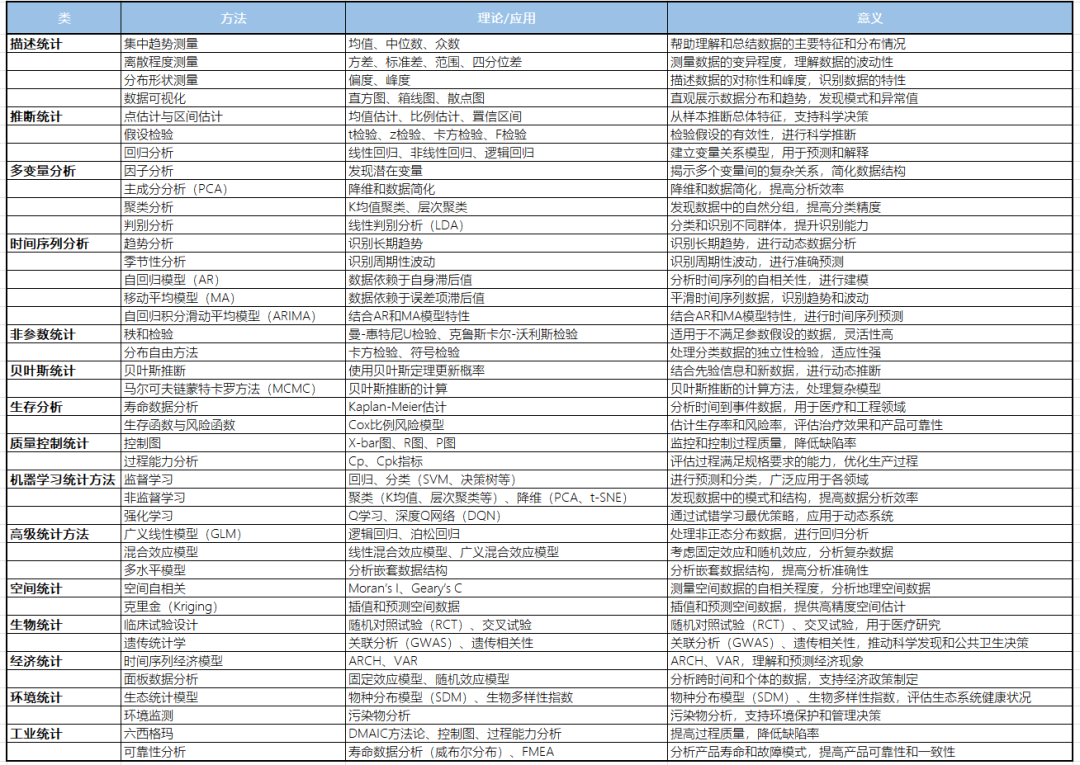
数据统计方法在科学研究、商业决策、公共政策、工程技术、医疗卫生等领域具有广泛应用,提供了系统化、科学化的手段来分析和解释数据,从而做出合理的决策、预测未来趋势、优化过程和解决实际问题。

(图片文件下载可在后台回复:数据统计方法.word )
描述统计(Descriptive Statistics)
描述统计主要用于总结和描述数据的基本特征。它们提供了简单的总结性数据度量。
均值(Mean):数据的算术平均数,反映数据的中心位置。中位数(Median):将数据排序后位于中间的值,反映数据的中位位置。方差(Variance):数据与均值的平方差的平均值。标准差(Standard Deviation):方差的平方根,表示数据的离散程度。峰度(Kurtosis):衡量数据分布的陡峭程度。
(图片文件下载可在后台回复:数据统计方法.word)
推断统计(Inferential Statistics)
推断统计用于从样本数据中推断总体特征,主要包括估计和假设检验。
点估计(Point Estimation):使用样本数据计算一个单一值来估计总体参数。区间估计(Interval Estimation):提供一个区间范围来估计总体参数,并给出一个置信水平。假设检验(Hypothesis Testing):z检验(z-Test):用于大样本或已知总体标准差时的均值比较。卡方检验(Chi-square Test):用于分类数据的独立性检验。回归分析(Regression Analysis):线性回归(Linear Regression):建立因变量和一个或多个自变量之间的线性关系。逻辑回归(Logistic Regression):用于分类变量的回归分析。
(图片文件下载可在后台回复:数据统计方法.word)
多变量分析(Multivariate Analysis)
因子分析(Factor Analysis):识别潜在的隐变量。主成分分析(Principal Component Analysis, PCA):降维技术,通过线性组合减少变量数。聚类分析(Cluster Analysis):将对象分成相似的组。判别分析(Discriminant Analysis):区分不同群体。
(图片文件下载可在后台回复:数据统计方法.word)
时间序列分析(Time Series Analysis)
趋势分析(Trend Analysis):识别长期趋势。季节性分析(Seasonal Analysis):识别周期性变化。自回归积分滑动平均模型(ARIMA):结合AR和MA模型的特性。

(图片文件下载可在后台回复:数据统计方法.word)
非参数统计(Non-parametric Statistics)
秩和检验:如曼-惠特尼U检验,用于比较两组数据的秩和。
(图片文件下载可在后台回复:数据统计方法.word)
贝叶斯统计(Bayesian Statistics)
贝叶斯推断(Bayesian Inference):使用先验分布和似然函数更新后验分布。马尔可夫链蒙特卡罗方法(MCMC):用于贝叶斯推断的数值计算。
(图片文件下载可在后台回复:数据统计方法.word)
生存分析(Survival Analysis)
Cox比例风险模型:用于生存时间与协变量的关系分析。质量控制统计(Statistical Quality Control)控制图(Control Charts):用于监控过程的稳定性。过程能力分析(Process Capability Analysis):评估过程满足规格要求的能力。机器学习统计方法(Statistical Methods in Machine Learning)
监督学习(Supervised Learning):分类:如支持向量机(SVM)、决策树、随机森林、k近邻(k-NN)、朴素贝叶斯。非监督学习(Unsupervised Learning):强化学习(Reinforcement Learning):深度Q网络(DQN):结合深度学习的强化学习方法。高级统计方法(Advanced Statistical Methods)
广义线性模型(Generalized Linear Models, GLM):混合效应模型(Mixed-Effects Models):线性混合效应模型(Linear Mixed-Effects Models):用于考虑固定效应和随机效应。广义混合效应模型(Generalized Mixed-Effects Models):处理非正态分布数据。多水平模型(Multilevel Models):空间统计(Spatial Statistics)
生物统计(Biostatistics)
随机对照试验(RCT):随机分配受试者到不同组,以比较治疗效果。经济统计(Econometrics)
自回归条件异方差模型(ARCH):用于金融时间序列数据的波动性分析。向量自回归模型(VAR):分析多个时间序列之间的相互影响。分析跨时间和个体的数据,如固定效应模型和随机效应模型。环境统计(Environmental Statistics)
生物多样性指数:如香农指数,用于衡量生态系统的多样性。工业统计(Industrial Statistics)
通过DMAIC(定义、测量、分析、改进、控制)方法论提高过程质量。故障模式与影响分析(FMEA):识别潜在故障及其影响。






