





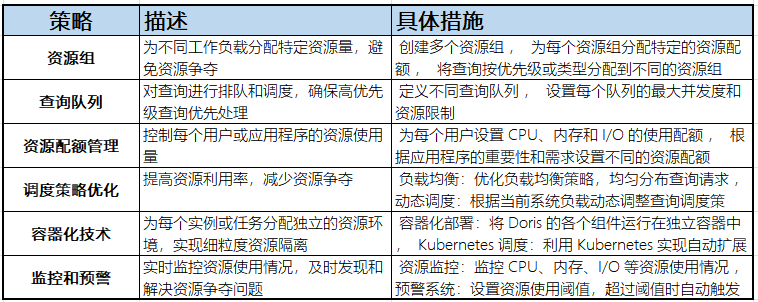
缺点分析
数据分片和分布策略不够灵活,导致导入过程中负载不均衡。 导入过程中缺乏有效的并行处理机制,无法充分利用硬件资源。
并行导入:通过引入并行处理机制,提升数据导入速度。例如,可以将大规模数据分割成多个小批次,同时进行导入,充分利用多核 CPU 和高带宽网络资源。 智能分片:改进数据分片和分布策略,确保数据在导入过程中能够均匀分布到各个节点,避免某些节点成为性能瓶颈。
查询执行过程中资源竞争激烈,容易导致系统瓶颈。 查询优化器在高并发情况下可能无法及时生成高效的查询计划。、
查询缓存:引入查询缓存机制,对于重复查询可以直接从缓存中获取结果,减少查询执行的开销。 物化视图:利用物化视图预先计算和存储复杂查询的结果,显著提升查询响应速度。 索引优化:通过创建适当的索引结构(如位图索引、倒排索引等),加速查询处理。 查询调度优化:优化查询调度策略,减少高并发情况下的资源竞争。 资源隔离:通过引入资源池和查询队列机制,实现资源隔离,确保高并发情况下系统的稳定性和性能。 负载均衡:改进负载均衡策略,确保查询请求能够均匀分布到各个节点,避免单点过载。
缺乏丰富的分析函数和自定义函数支持,限制了复杂分析任务的实现。 对复杂查询(如多表连接、大量子查询等)的优化不够充分,导致查询性能下降。
自定义函数支持:支持用户定义函数(UDF),满足复杂数据处理和分析需求。 复杂查询优化:改进查询优化器,对复杂查询(如多表连接、大量子查询等)生成更高效的执行计划。
第三方数据集成工具和 ETL 工具的兼容性不够,导致数据处理流程复杂。 社区活跃度和插件数量相对较少,限制了功能的扩展性。
第三方工具支持:加强与主流数据集成工具和 ETL 工具的兼容性,简化数据导入和处理流程。 社区和插件:鼓励社区开发插件和扩展,丰富 Doris 的功能和使用场景。可以通过举办开发者大会、悬赏开发任务等方式,激励社区贡献。
开放标准支持:增加对开放数据存储格式(如 Parquet、ORC)的支持,减少数据转换的复杂度,提升数据交换的灵活性。 压缩和编码优化:通过引入更高效的压缩和编码算法,减少存储空间占用,提升数据读写性能。例如,可以采用列式存储结合高效压缩算法(如 LZ4、ZSTD),提高存储和查询效率。
文章转载自码奋,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
