






1. 线分类法
理论原理
线分类法基于线性模型,其决策边界是一个线性函数。假设输入数据为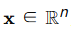 ,线分类模型的决策边界可以表示为:
,线分类模型的决策边界可以表示为:

线性判别分析(LDA):LDA假设每个类别的特征具有高斯分布,并且不同类别具有相同的协方差矩阵。其目标是通过投影找到最大化类间方差和类内方差比率的投影方向。投影方向w可通过以下优化问题求得
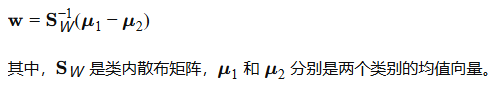
支持向量机(SVM):SVM的目标是找到一个能最大化两类样本之间间隔(margin)的超平面。优化问题可以表示为:

举例
垃圾邮件分类:使用LDA或SVM将邮件特征向量分类为垃圾邮件或正常邮件。
图像分类:对于简单图像分类任务,可以使用SVM在提取的特征基础上进行分类。
2. 面分类法
理论原理
面分类法通过非线性变换将数据映射到高维空间,使得在高维空间中数据变得线性可分。常见方法包括核方法和神经网络。
核方法(Kernel Methods):通过核函数 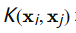 将数据从原始空间映射到高维空间。常见的核函数包括多项式核、径向基函数(RBF)核等。SVM的非线性版本通过解决以下优化问题来找到最优分类器:
将数据从原始空间映射到高维空间。常见的核函数包括多项式核、径向基函数(RBF)核等。SVM的非线性版本通过解决以下优化问题来找到最优分类器:
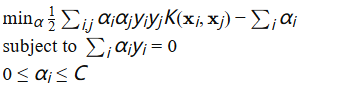
神经网络:神经网络通过多层非线性激活函数来学习复杂的模式。以多层感知器(MLP)为例,其每层的输出可以表示为:
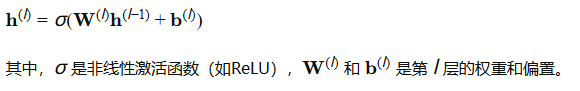
举例
图像识别:卷积神经网络(CNN)在图像分类任务中表现卓越,通过卷积层提取图像特征。
语音识别:循环神经网络(RNN)及其变体(如LSTM、GRU)能够有效处理语音信号中的时序信息。
3. 混合分类法
理论原理
混合分类法结合了多种模型的优势,常见的技术包括集成学习和混合神经网络。
集成学习(Ensemble Learning):通过组合多个基分类器的预测结果来提高分类性能。常见方法包括:
随机森林(Random Forest):通过构建多棵决策树并进行多数投票来做出分类决策。每棵树使用不同的特征子集和样本子集进行训练。
梯度提升树(Gradient Boosting Trees):通过逐步构建树模型,每一步减少前一步的残差。
混合神经网络:组合不同类型的神经网络来处理复杂数据。例如,卷积神经网络(CNN)和循环神经网络(RNN)的结合,可以处理图像和序列数据。
举例
金融风险评估:使用随机森林结合不同的金融指标预测信用风险。
医学诊断:组合CNN和RNN处理医疗影像和病历数据,提高诊断准确率。
最新的数据分类方法
1. 深度学习(Deep Learning)
卷积神经网络(CNN)
理论原理:卷积神经网络主要用于处理具有网格结构的数据(如图像)。其核心思想是通过卷积运算提取局部特征,并通过池化层进行降维,从而捕捉数据中的空间层次信息。
卷积运算:
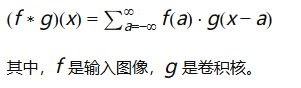
层次结构:
卷积层:通过多个卷积核提取局部特征。
池化层:通过最大池化或平均池化减少特征图的尺寸,降低计算量并增强模型的平移不变性。
全连接层:将卷积层和池化层提取的特征向量化,进行分类决策。
示例:
ResNet:通过引入残差连接解决深层网络的梯度消失问题,使得网络可以训练得更深。
循环神经网络(RNN)
理论原理:循环神经网络用于处理序列数据,通过循环结构捕捉序列中的时序依赖性。RNN的基本单元包括一个循环层,其输出依赖于当前输入和先前的隐藏状态。
递归公式:
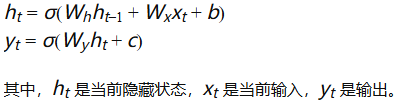
改进:
LSTM(Long Short-Term Memory):通过引入门控机制(输入门、遗忘门和输出门)解决长期依赖问题。
GRU(Gated Recurrent Unit):类似于LSTM,但结构更简单,计算效率更高。
示例:
语言模型:LSTM和GRU在自然语言处理中的语言建模、机器翻译等任务中表现优越。
注意力机制和变换模型(Transformers)
理论原理:注意力机制通过计算输入序列中每个元素对其他元素的重要性来捕捉长距离依赖。Transformers通过多头自注意力机制和完全并行的架构实现了高效的序列建模。
注意力机制:
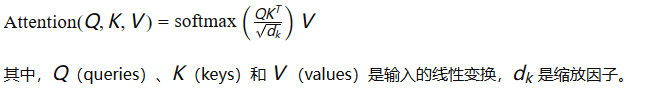
变换模型架构:
编码器-解码器结构:编码器将输入序列编码为固定长度的上下文向量,解码器根据上下文向量生成输出序列。
自注意力机制:每个位置的输出通过聚合整个序列的信息进行计算,解决了RNN中的序列依赖问题。
示例:
BERT(Bidirectional Encoder Representations from Transformers):通过双向编码器预训练在自然语言理解任务中取得显著效果。
GPT(Generative Pre-trained Transformer):通过单向解码器生成文本,在自然语言生成任务中表现出色。
2. 自监督学习(Self-supervised Learning)
理论原理:自监督学习通过设计代理任务从未标注的数据中学习有用的特征。代理任务通常通过数据自身的结构生成标签,从而无需人工标注。
常见代理任务:
掩码语言模型(Masked Language Model):如BERT,通过随机掩码部分词语并预测这些词语来学习词语的上下文表示。
对比学习(Contrastive Learning):如SimCLR,通过最大化不同数据增强视图的相似性来学习特征。
示例:
BERT:在预训练阶段,使用掩码语言模型任务预测被掩码的词语,学习词语的上下文表示。
SimCLR:通过对比学习框架,学习图像的表示向量,在下游任务(如图像分类)中表现优越。
3. 图神经网络(Graph Neural Networks, GNNs)
理论原理:图神经网络用于处理图结构数据,通过节点及其邻居的信息聚合进行学习。GNN通过递归地更新节点表示,捕捉图中复杂的关系和依赖。

