




非结构化文本在商业领域无处不在:客户评论、支持单、通话记录、文档。大型语言模型 (LLM) 正在通过执行从分类到总结等任务来改变我们从这些数据中提取价值的方式。虽然人工智能已经证明使用 LLM 可以进行自然语言的实时对话,但使用这些 LLM 从数百万条非结构化数据记录中提取见解可能会改变游戏规则。这就是批量 LLM 推理变得至关重要的地方。
在本文中,您将深入了解大规模文本数据分析的常见业务用例。您还将了解部署批量 LLM 管道为何具有挑战性,以及 Snowflake 如何优化 Snowflake Cortex AI 以通过 SQL 函数进行批量推理。
常见的批量 LLM 推理作业有哪些?
组织中的不同团队可以利用批量 LLM 推理从大量文本数据中提取见解。客户智能团队分析评论和论坛评论以确定情绪趋势,而支持团队处理工单以发现产品问题并告知产品路线图中的差距。同时,运营团队使用文档上的实体提取来自动化工作流程并实现元数据驱动的分析过滤。以下是不同团队如何使用 LLM 从大量非结构化文本数据中提取见解的更多示例:
-
文本分类和标记:根据情绪、主题或紧急程度自动对支持票、电子邮件、新闻文章或产品评论进行分类。
-
实体提取:从合同、发票或医疗记录中提取关键实体(姓名、日期、地点、财务数据),将非结构化文本转换为结构化数据。
-
情绪和趋势分析:大规模分析客户反馈、调查回复或社交媒体讨论,以检测趋势、衡量情绪并为商业决策提供信息。
-
内容审核:扫描大型数据集(社交媒体帖子、聊天记录、客户反馈)以查找违反政策、有害内容或法规遵从问题。
-
文档摘要:为大量报告、研究论文、法律文件或会议记录生成简洁的摘要。
-
文档 RAG 准备:在将文档嵌入到矢量表示之前,对其进行提取、清理和分块,从而实现检索增强生成 (RAG) 系统中的有效检索和增强的 LLM 响应。
-
文本数据质量:通过提供理想输入组合的上下文来验证多个文本字段(例如表单填写),这使 LLM 能够检测异常和不正确的记录以提高数据质量。
-
特征工程:提取、分类并将非结构化文本转换为结构化特征,通过丰富的背景和见解增强机器学习模型。
为什么高效的批量 LLM 流程很重要
“LLM 正在改变工作场所”不仅仅是一句口号。考虑一下:对 10,000 张支持单进行分类,即使是您最快的员工也需要大约 55 小时(每张单 20 秒)。使用优化的 LLM 管道,同样的任务只需几分钟即可完成。这不是渐进式改进——而是一种转型效率提升,可节省数千个工时并大大加快响应时间。
随着数据量的增长和 AI 自动化的扩展,使用 LLM 进行处理的成本效率取决于系统架构和模型灵活性。高效的批处理系统可以以经济高效的方式扩展,以处理不断增长的非结构化数据量。能够灵活地切换 LLM 有助于企业通过为每个用例调整模型大小并随着模型的改进轻松升级来优化成本。
为了提高技术和团队效率,组织需要考虑将 LLM 管道与现有的结构化数据工作流集成的机会。扩大围绕管道管理、处理和编排的现有投资可以简化架构并降低集成和基础设施维护工作带来的运营复杂性。这种统一还可以使已经管理结构化管道的数据工程师能够轻松地加入和维护非结构化数据工作流。
使用 Cortex AI 高效运行批量推理管道
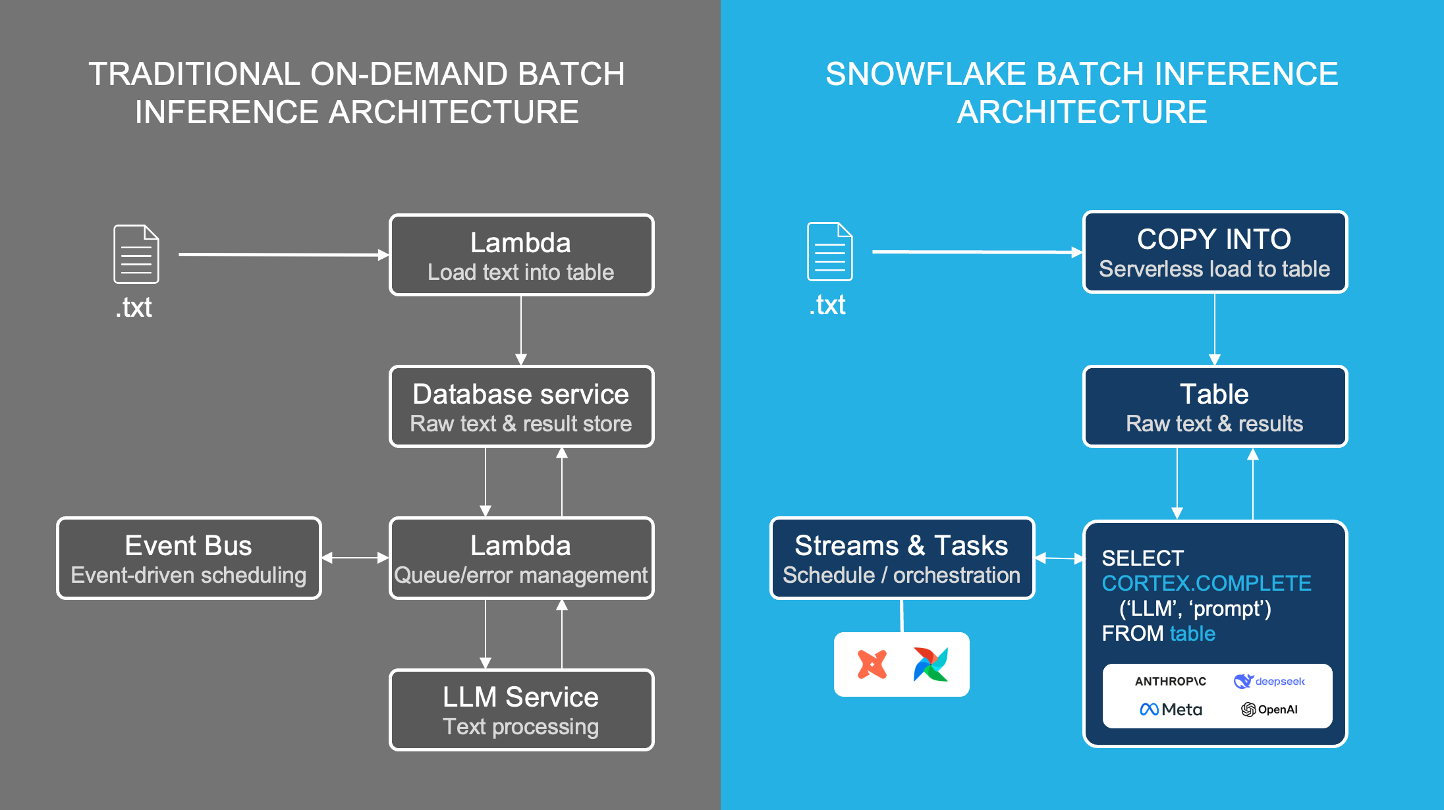
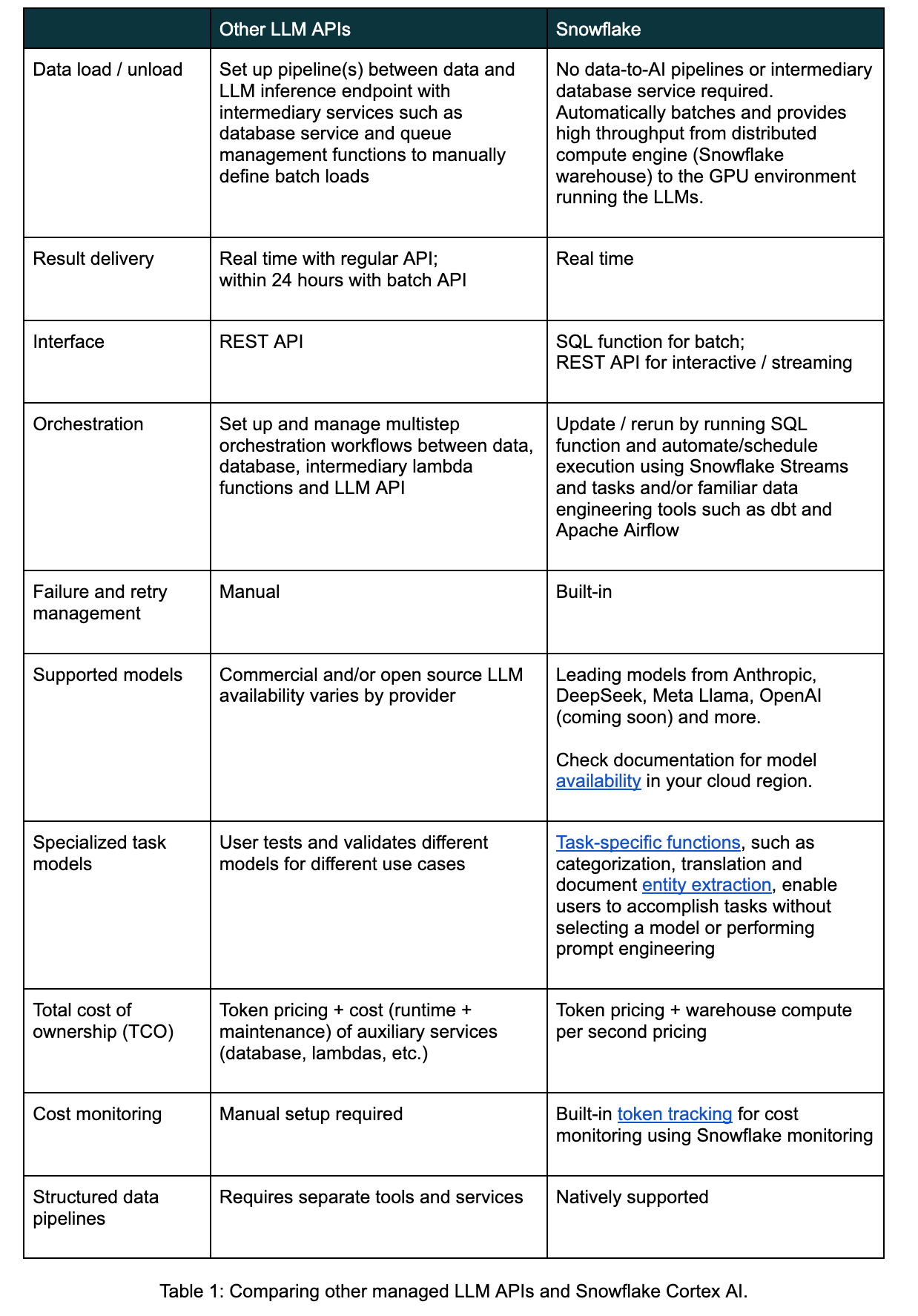
Headset 切换了其一个批量分类管道,该管道一直与领先的 LLM API 推理提供商 (Fireworks AI) 一起运行,并通过使用 Snowflake Cortex COMPLETE 推理功能,将作业执行时间从 20 分钟缩短到 20 秒。
使用Snowflake Cortex COMPLETE 函数,开发人员可以使用不需要中间数据库或 lambda 的 SQL 函数运行批量 LLM 推理,以实现可靠、高吞吐量的处理和灵活的模型选择。
其他客户成功案例
通过使用 Snowflake,日产将其客户智能应用程序的项目进度缩短了两个月,该应用程序可分析来自评论和论坛的客户情绪,以帮助经销商改进其产品和服务。观看点播网络研讨会。
Skai 仅用两天时间就部署了一个分类工具,通过构建跨多个电子商务平台的类别,帮助客户更好地了解购买模式。阅读案例研究。
在我们的客户成功电子书中查找更多故事。
原文地址:https://www.snowflake.com/en/blog/batch-llm-inference-text-analytics-cortex/
原文作者:
Julian Forero
Chase Ginther
