




Chat2DB 为了提升AI生成 SQL的准确率,也为了解决在大量的底层数据中抽出用户需要的数据,我们引入了RAG通过RAG提升AI的生成效果。
RAG 技术概述
RAG 是一种结合了检索和生成的 NLP 方法,它不仅生成响应,还从大规模知识库中检索相关信息以辅助生成过程。在 Chat2DB 应用中,RCT(检索-编码-转换)模型通过检索相关的数据库信息和先前的查询历史,增强了生成的准确性和相关性。这种方法允许模型不仅依赖于其已有的知识,还能实时地从特定数据库环境中获取上下文,使得生成的 SQL 语句更加准确和高效。
AI数据集
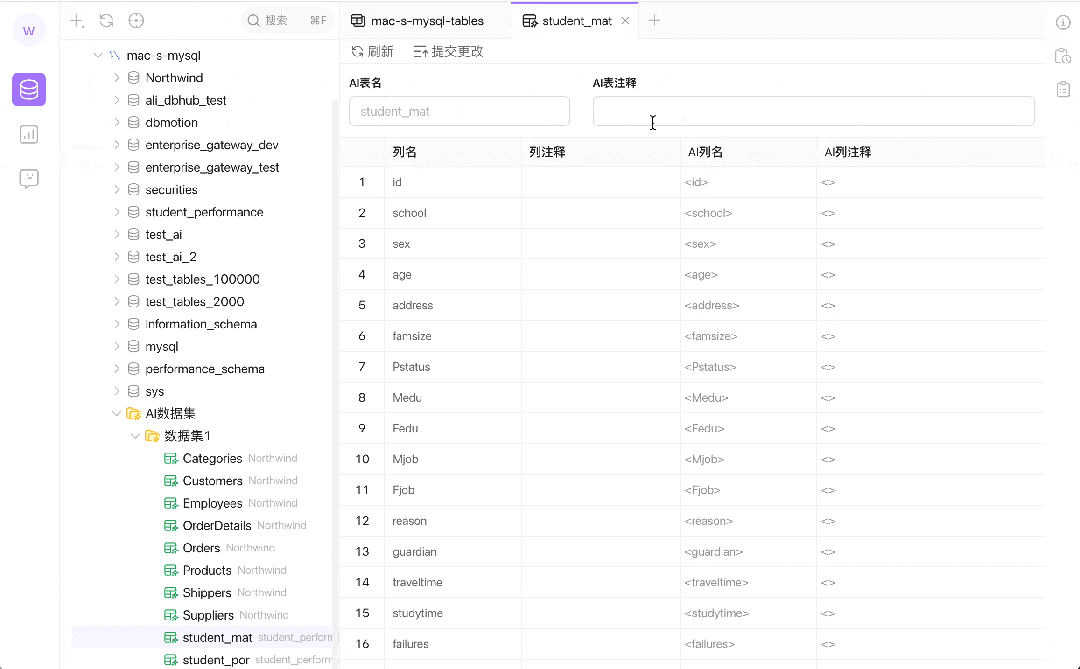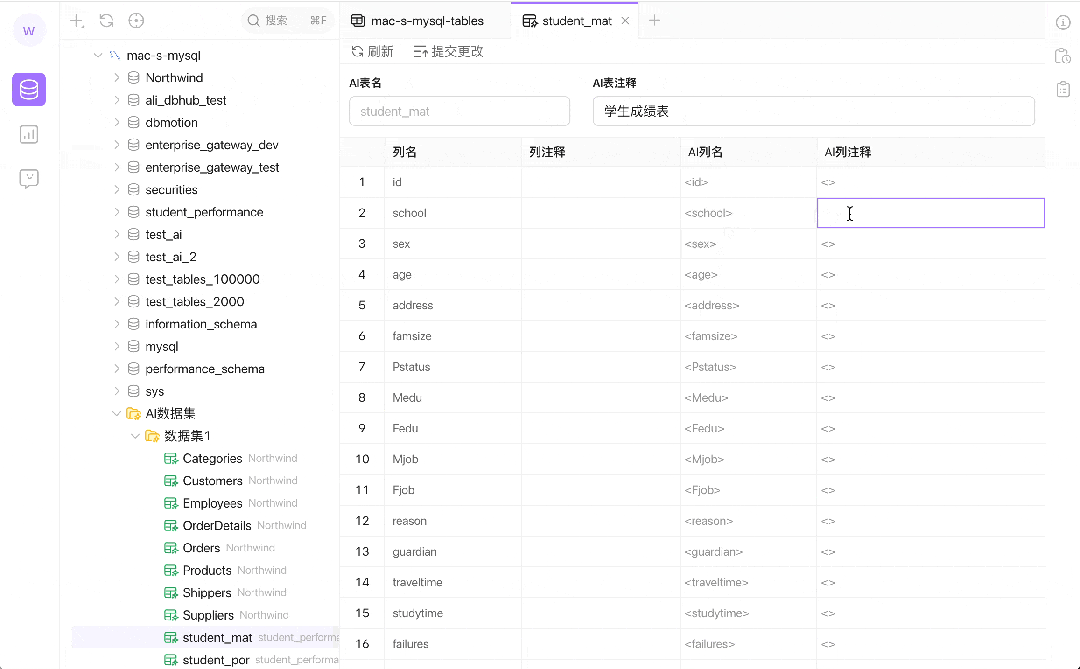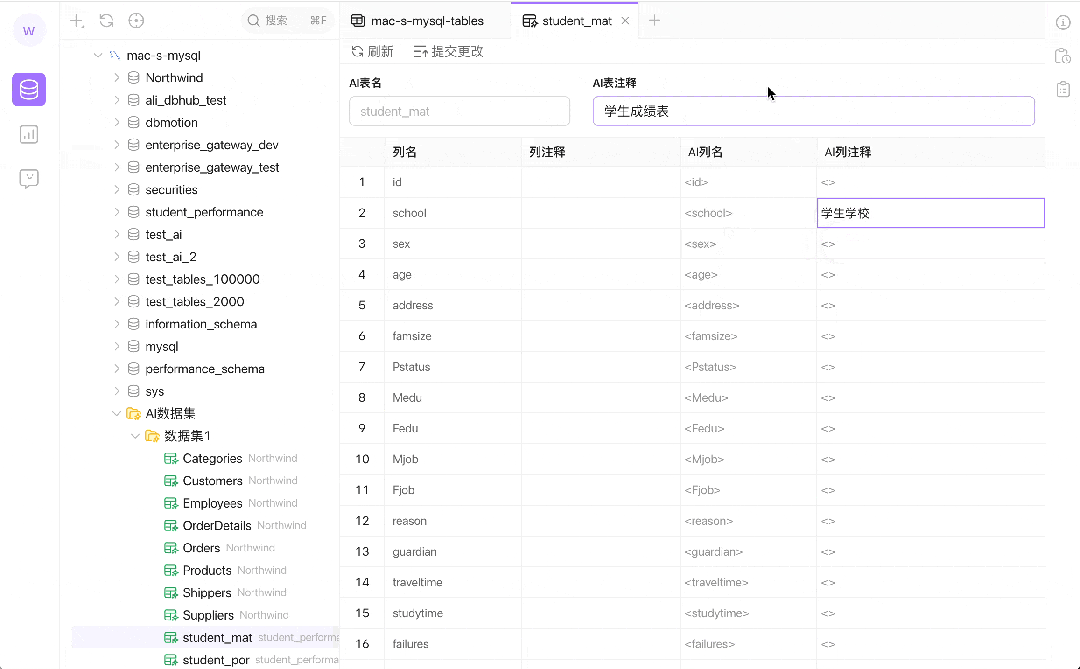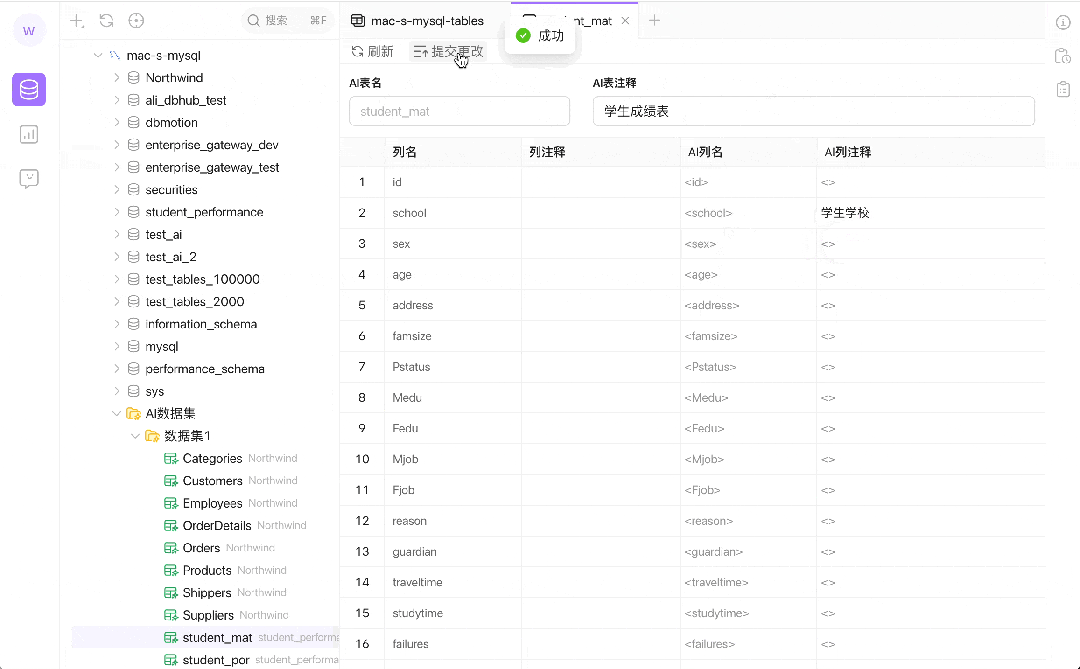
在 Chat2DB 中新引入了“AI 数据集”概念。这一功能允许用户自定义数据集并对数据进行重新标注,从而提高 AI 模型在生成 SQL 语句时的准确性和适应性。这种自定义和标注的过程是独立于底层数据库结构的,专门为 AI 生成过程设计,不会影响原始数据表的结构和存储。
AI 数据集的功能与优势
AI 数据集的引入为 Chat2DB 用户提供了以下几个关键优势:
自定义数据视图:用户可以根据自己的需求选择特定的数据字段和数据类型来创建数据集。这使得用户能够构建针对特定分析和查询任务优化的数据视图,而无需修改底层数据库。
灵活的数据标注:AI 数据集支持用户在不更改原始数据的前提下进行数据标注。这种标注对于训练 AI 模型来说至关重要,因为它允许模型学习和理解不同的数据表示方式,从而提高查询的准确性和相关性。
隔离与安全性:由于标注数据仅用于 AI 生成过程,并不影响底层数据,这种方法还为数据安全和完整性提供了额外的保护层。用户可以自由地进行实验和调整,而不用担心影响到生产环境中的数据。
增强的数据管理:AI 数据集允许用户更有效地管理用于 AI 训练的数据。用户可以创建多个数据集,针对不同的业务需求或查询场景,优化数据集的结构和内容。这种灵活的管理方式提高了整体的数据处理效率和模型的性能。
动态适应:用户对 AI 数据集的标注和调整可以动态地反馈给系统。Chat2DB 利用这些信息来持续优化其 AI 模型,以适应用户的特定需求和偏好。这种适应性是通过机器学习算法实现的,能够确保随着时间的推移和数据的积累,模型的性能会持续提升。
核心流程
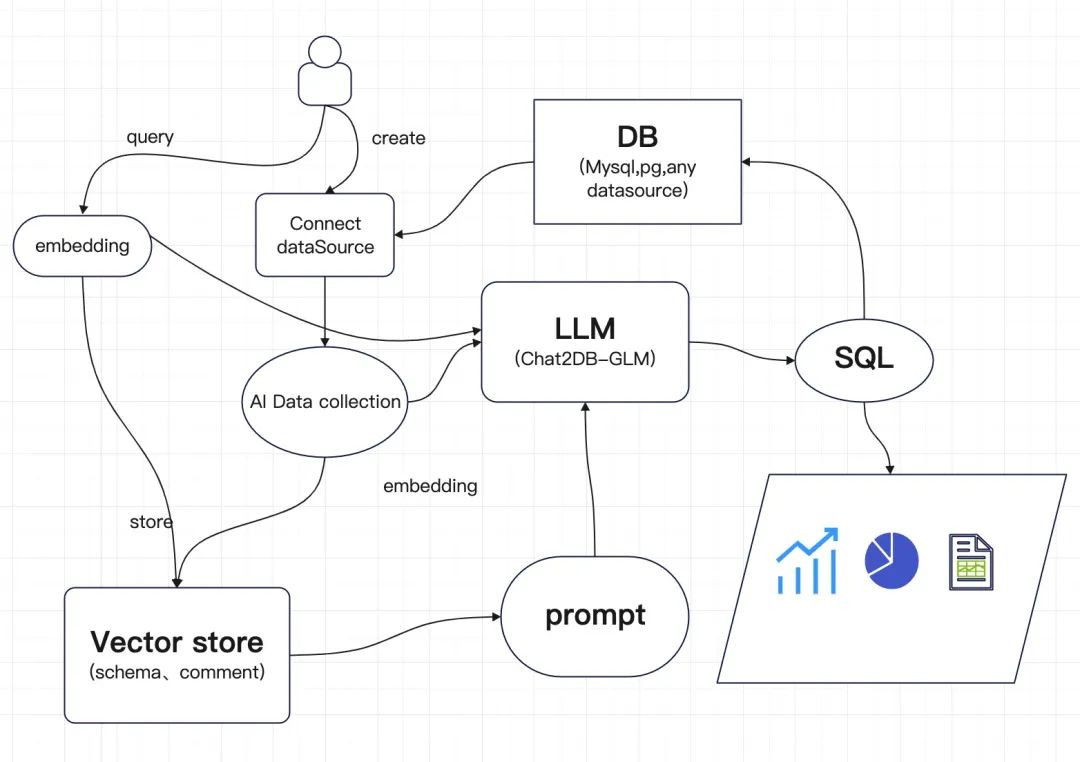
AI 数据集的实现涉及多个核心技术流程,每个流程都对提高 Chat2DB 生成 SQL 语句的准确性和效率起到关键作用。以下是这些流程的详细分析:
Embedding
Embedding 是将自然语言转换为机器可以理解的数值表示的过程。在 Chat2DB 中,嵌入技术用于将用户查询和数据标签转化为密集的向量形式。这一步骤是至关重要的,因为它确保了机器学习模型能够处理和理解复杂的自然语言输入。使用高效的嵌入模型可以捕捉文本数据的语义和语法特征,从而提高后续处理的准确性和效率。
2. Vector Store(向量存储)
向量存储是管理嵌入向量的系统,它允许快速的相似性搜索和检索操作。在 Chat2DB 中,嵌入的查询和数据标签向量存储在一个优化的向量数据库中,这使得在执行 SQL 查询生成时能够快速找到与用户查询最相关的信息。这一技术支持大规模数据的高效管理,是实现快速响应时间的关键。
3. Prompt
Prompt 构造是指定制化引导大模型以生成特定输出的过程。在 Chat2DB 的上下文中,根据用户的自然语言查询和从向量存储中检索到的相关数据,系统构建特定的提示语(Prompt),以引导语言模型(LLM)生成准确的 SQL 语句。这一步骤是连接用户输入和模型输出的桥梁,确保生成的 SQL 语句既符合语法也具有高度的相关性。
4. LLM(大型语言模型)
大型语言模型在 Chat2GB 中用于解析提示并生成对应的 SQL 查询。通过训练在大量数据库语言交互数据上,LLM 能够理解复杂的查询意图,并生成结构化的 SQL 代码。这些模型通过不断学习和调整,能够适应各种查询类型和数据结构,从而不断提高查询的准确率和效率。
5. SQL(结构化查询语言)
生成的 SQL 是执行用户查询意图的直接产物。在 Chat2DB 中,通过上述步骤生成的 SQL 语句会被直接运用于数据库,从而获取用户所需的数据。这一步骤的准确性直接影响到查询结果的质量和用户满意度,因此优化 SQL 生成算法是提升整体系统性能的关键。
6. 图表
最终,查询结果不仅需要以文本形式呈现,还应通过图表等可视化方式展示,以增强数据的可读性和易理解性。Chat2DB 提供了强大的数据可视化功能,能够根据查询结果自动生成图表,如柱状图、折线图、饼图等。这使得用户可以直观地看到数据趋势和模式,从而做出更加明智的决策。
通过这些高度集成的技术流程,Chat2DB 在处理和生成 SQL 查询方面不仅展现出高效性,也保证了用户交互的流畅性和准确性。
快速上手
关注我们了解最新技术
