





1.1 指标检索

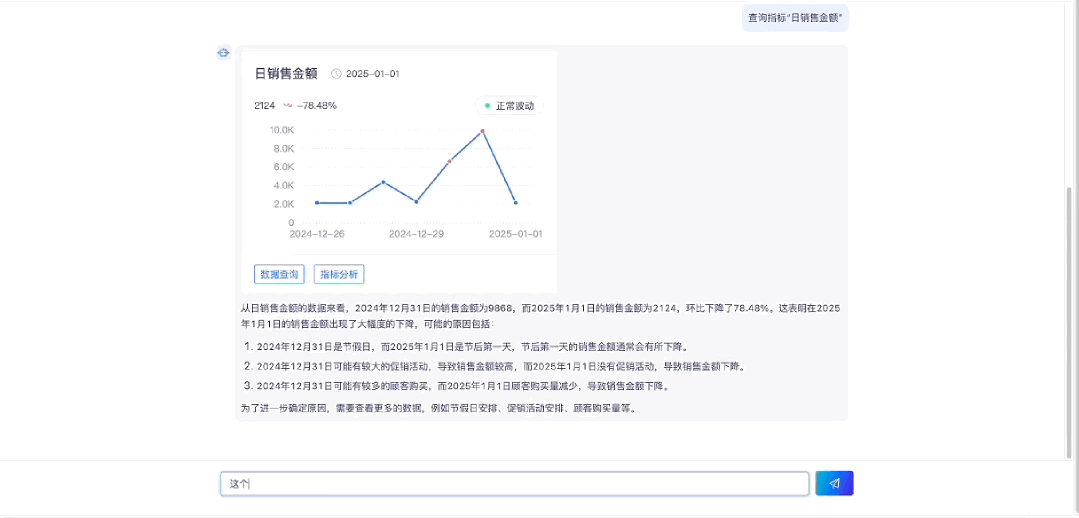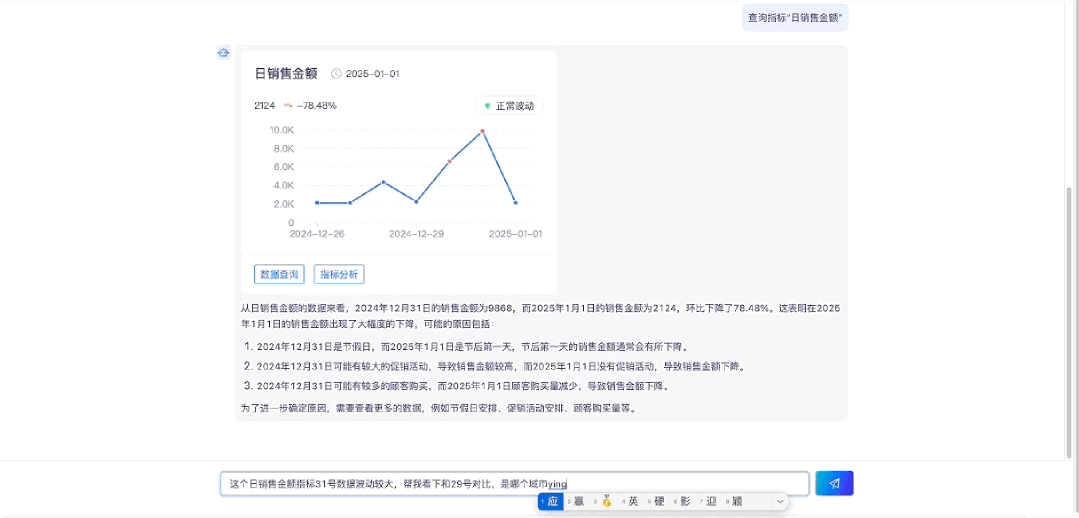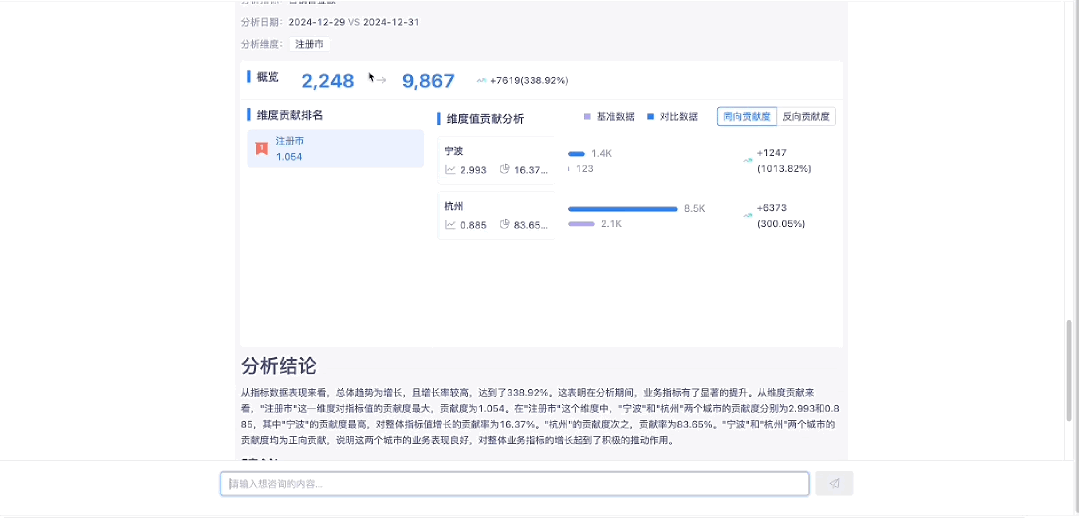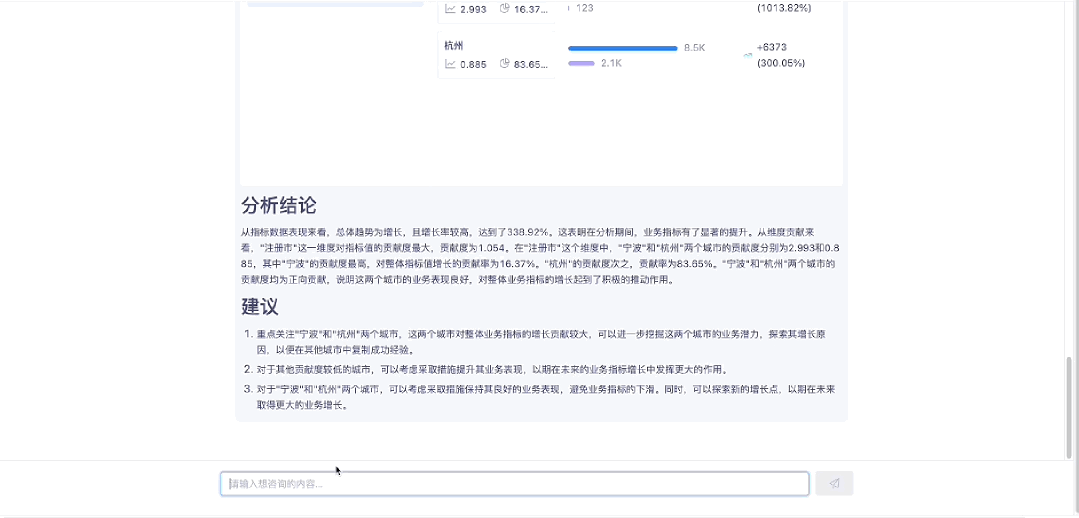
1.2 指标图表展示
1.3 指标数据查询
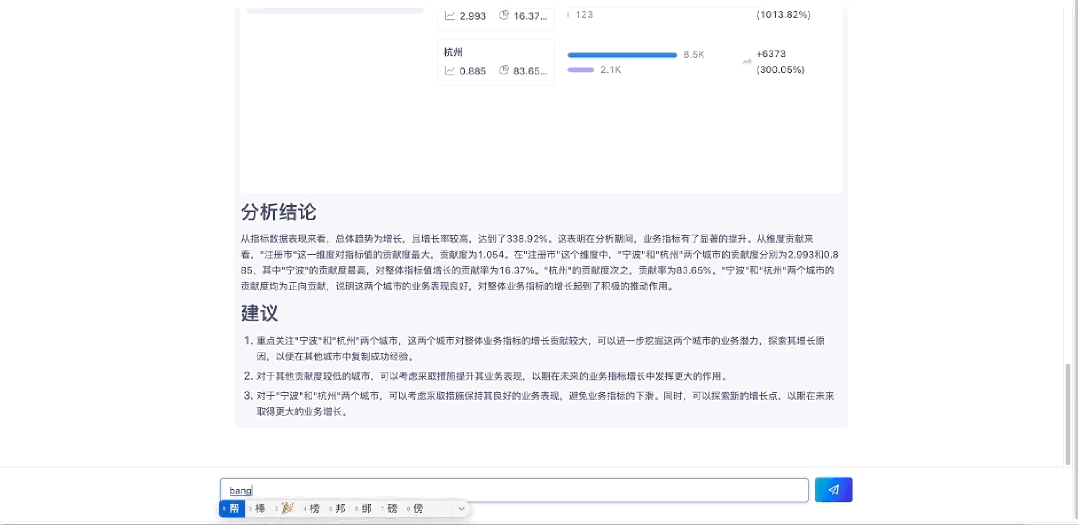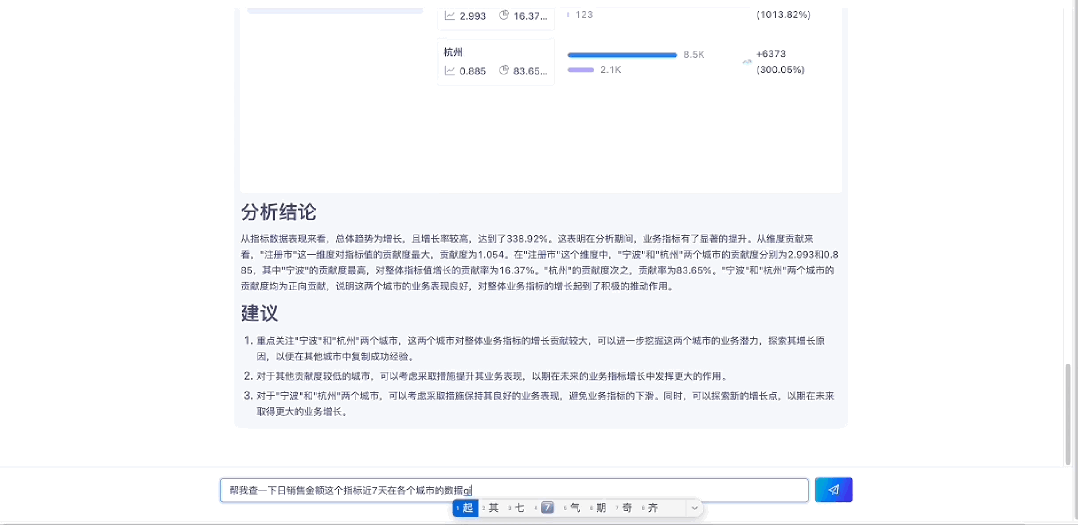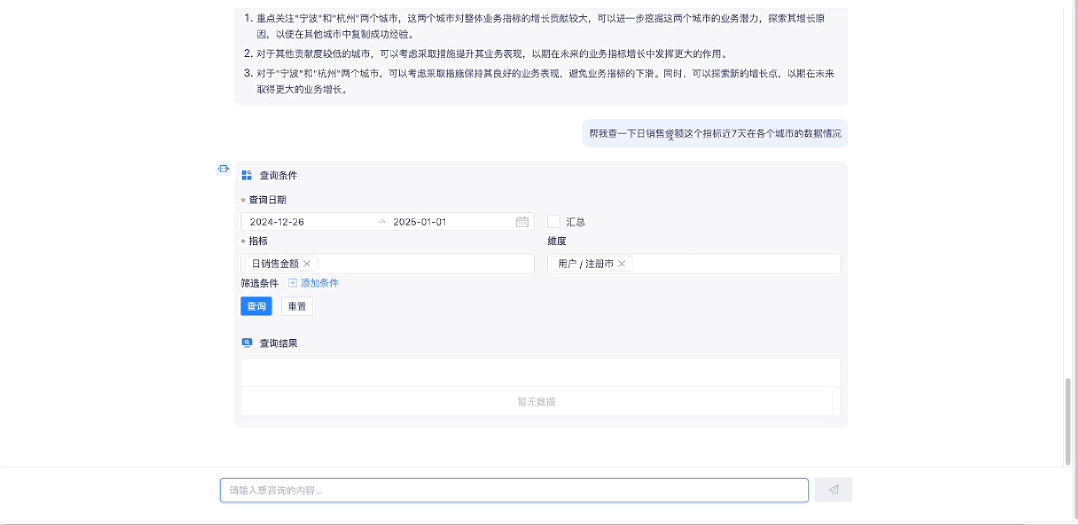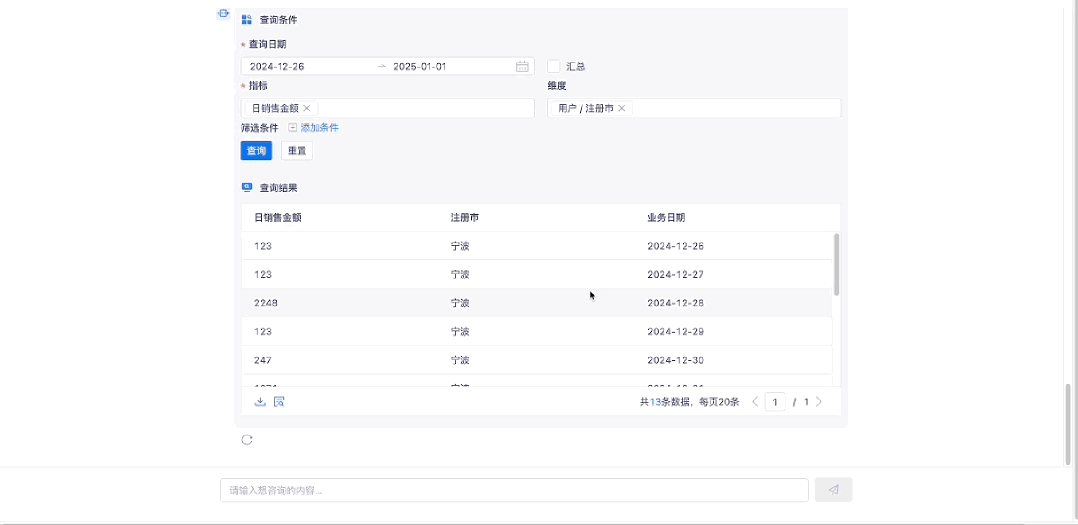
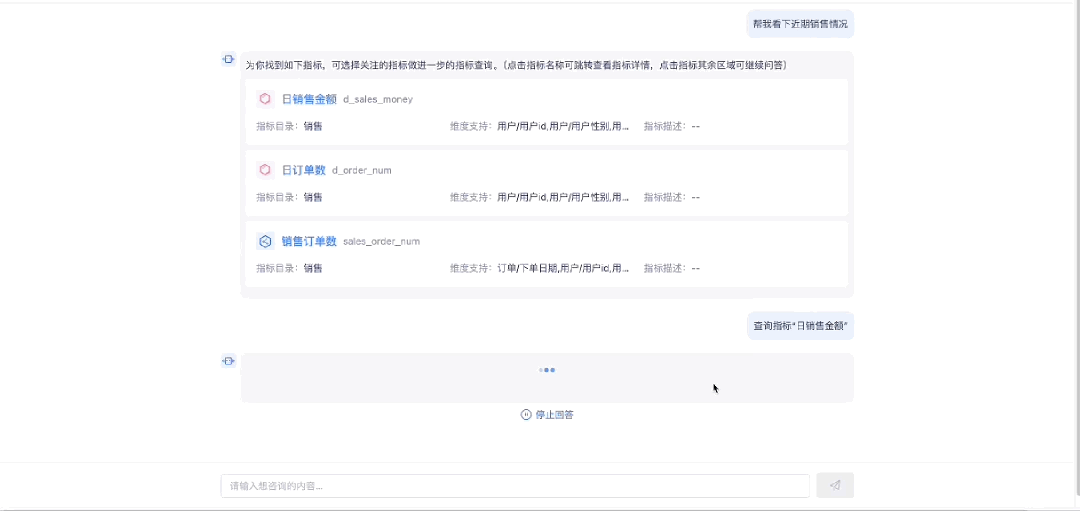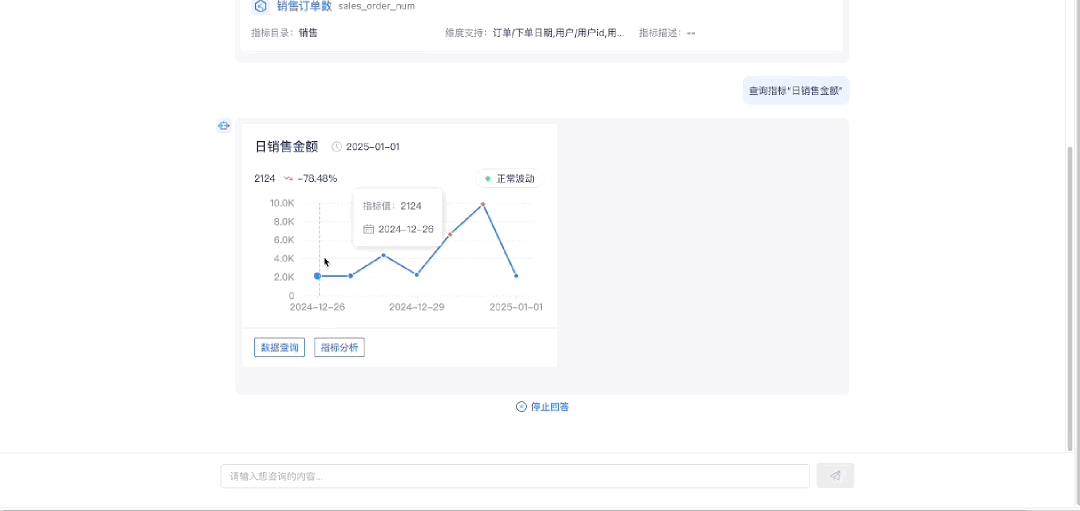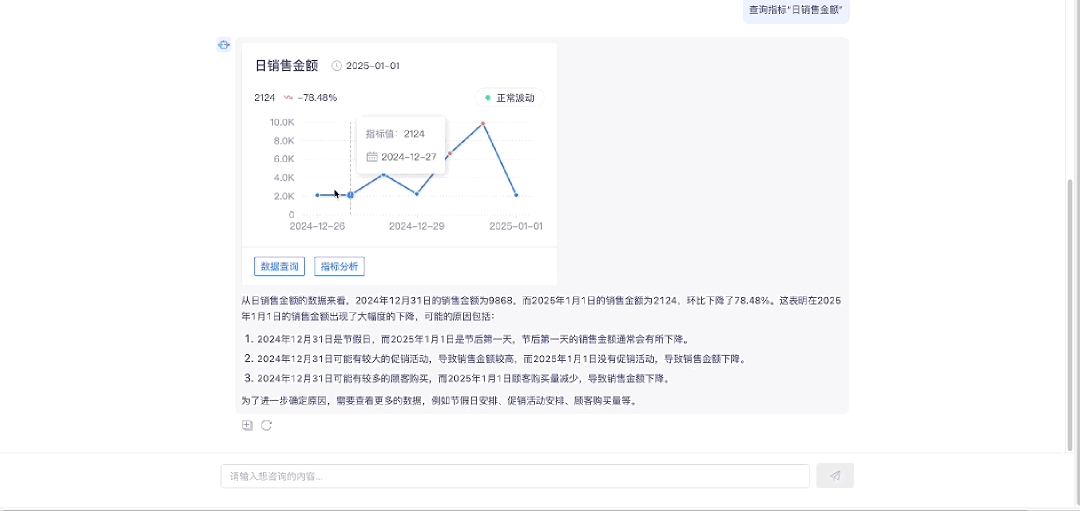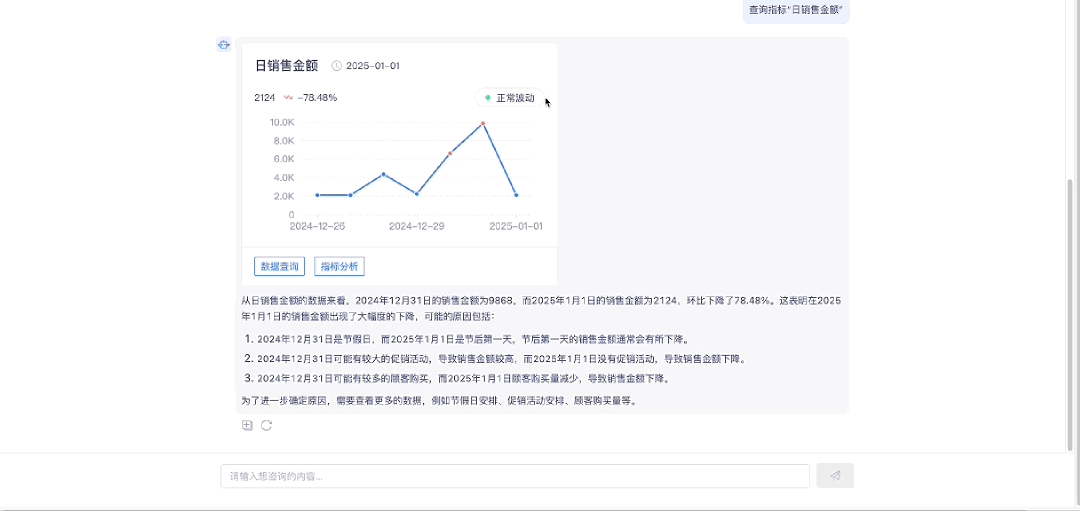
1.4 指标归因分析

技术解析
2.1 指标平台元数据向量化
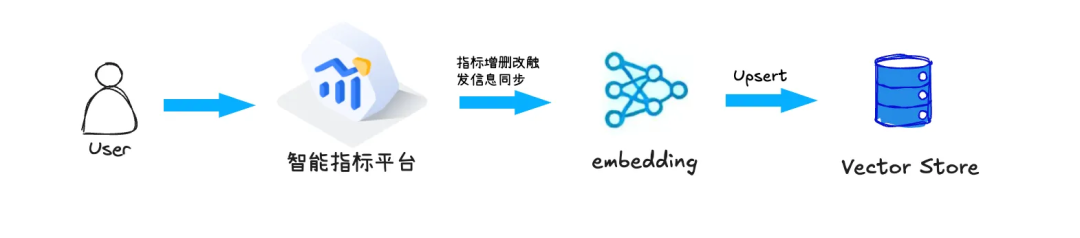
关键字段提取:从指标元数据中筛选出核心字段(指标名称、指标英文名、指标描述),确保只对最关键的信息进行向量化处理,以降低噪音,提高检索精度。 文本拼接:将选定的多个字段(指标名称、指标英文名、指标描述)通过逗号分隔符拼接成一个完整的文本。 向量化处理:利用向量模型对拼接后的文本进行向量化,将文本转换成高维向量表示,保留语义信息。 向量存储:将生成的向量数据与原始指标信息一并存入向量数据库(Vector Store),便于后续的高效检索和匹配。
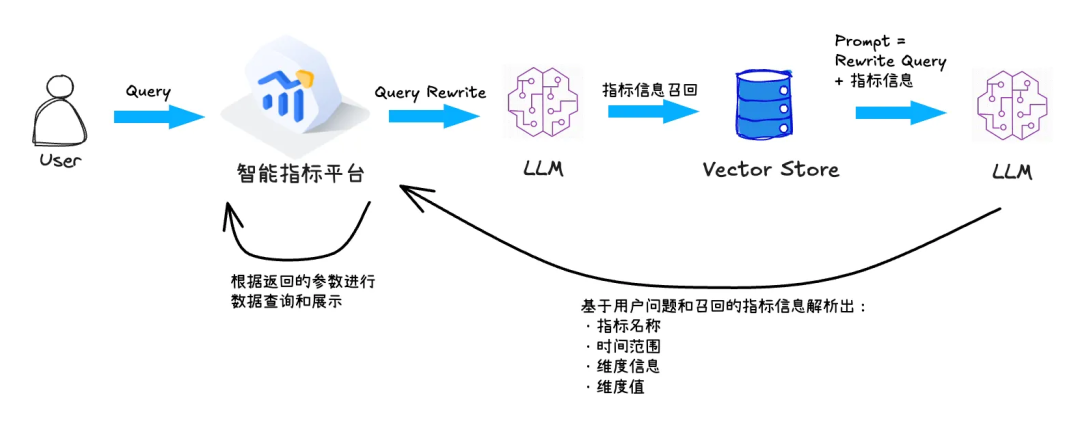
2.2 指标信息召回

任务描述:你的任务是接收用户关于数据指标查询的问题输入,并将其按照中文语法规则准确地分割成独立的词汇单元。每个词汇或短语应当能够作为搜索数据中台内对应指标名称的关键字。输入示例:过去一个月的销售额是多少?分词要求:1. 将句子分解成可以用于搜索相关数据指标的关键词。2. 请确保保留时间相关的词汇(如“过去一个月”),因为它们对于查找正确的数据指标至关重要。3. 输出格式应为‘**, ’两个星号和逗号分隔的字符串,便于进一步处理。输出格式示例:过去一个月**,销售额**
2.3 指标数据查询
对大模型能力要求高:准确率高的NL2SQL方案通常都需要参数量比较大的大模型,如ChatGPT,参数大的模型意味着模型推理的成本大大提高。 大模型多样性:袋鼠云是一家To B的公司,未来面对的不同客户环境下的大模型具有多样性、存在性能差异。
我们的指标平台是基于维度建模的思想建设的,在平台上需要先建立好数据模型,定义各类业务需要的维度和度量,指标由时间维度 + 维度 + 指标组成。所以我们天然有了一层维度建模的语义,为NL2API奠定了基础。 为了降低大模型对SQL解析的依赖,我们基于维度建模的语义设计开发了自助取数的API接口,通过给自助取数的API接口传递指标ID、维度列表、时间范围、where过滤条件相关参数即可完成数据查询。 用户输入自然语言查询数据时,先根据用户问题匹配目标指标元信息,然后生成与大模型交互的Prompt,Prompt由用户问题+指标元信息+历史对话组成,让大模型解析出自助取数API需要指标ID、维度列表、时间范围、where过滤条件参数。 指标平台根据大模型解析出来的参数进行指标数据查询展示


文章转载自数栈研习社,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
