




Hadoop生态演进
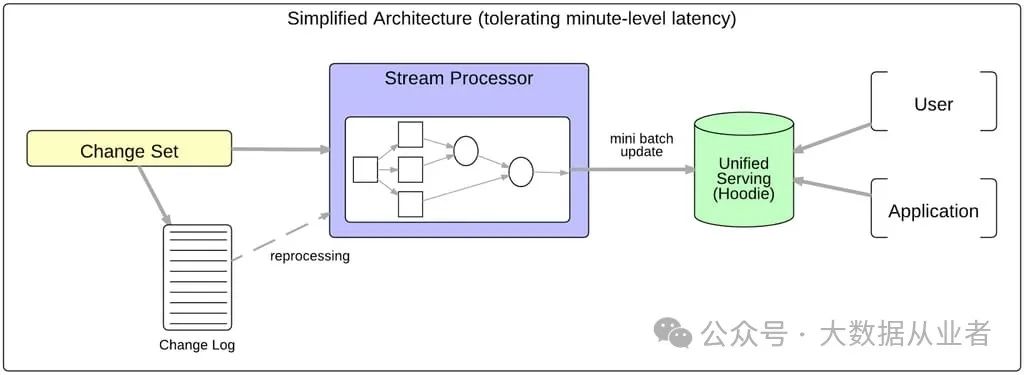
随着Apache Parquet和Apache ORC等存储格式以及Presto和Apache Impala等查询引擎的发展,Hadoop生态系统有潜力成为容忍几分钟延迟的通用统一服务层。然而,这需要Hadoop分布式文件系统(HDFS)实现高效低延迟的数据摄入和准备。
为此,Uber开发了Hudi(发音为“hoodie”),这是一个增量处理框架,旨在以低延迟和高效率支持所有关键业务数据管道。在深入探讨Hudi之前,让我们先讨论为何将Hadoop视为统一服务层是合理的。
动机
Lambda架构是一种常见的数据处理架构,它提出了流处理层和批处理层的双重计算。每隔几小时,批处理任务会计算准确的业务状态,并将批量更新加载到服务层。与此同时,流处理层计算并提供相同的状态,以规避多小时的延迟。然而,这种状态仅是近似值,直到被更准确的批处理计算结果覆盖。由于两种状态存在差异,需要为批处理和流处理维护不同的服务层,或在顶层抽象中合并,或使用复杂的服务系统(如Druid)来同时支持记录级更新和批量加载。
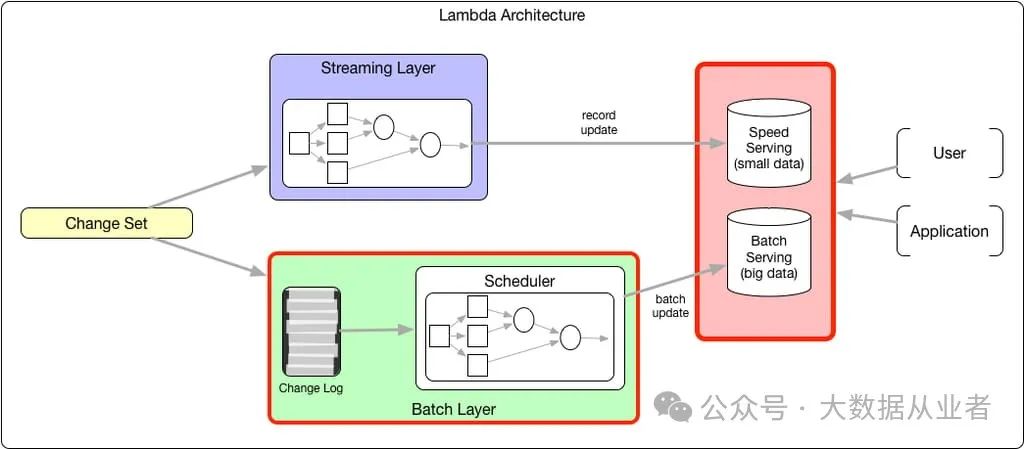
Kappa架构质疑是否需要独立的批处理层,认为流处理引擎可以成为计算的通用解决方案。从广义上看,所有计算都可以描述为生成元组流的操作符和迭代多个输入元组流的消费者(即Volcano迭代器模型)。这种功能使流处理层能够通过增加并行性和资源来重新处理业务状态。借助能够高效检查点和存储大量流状态的系统,流处理层的业务状态不再是近似值。尽管该模型消除了批处理层,但两种不同服务层的问题依然存在。
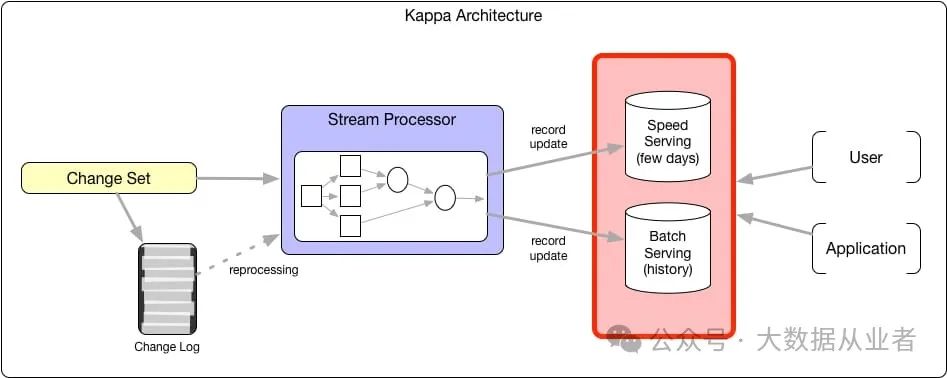
许多真正的流处理系统在记录级别运行,因此加速服务系统应优化记录级更新。通常,这些系统无法同时优化分析扫描,除非系统将大部分数据存储在内存中(如Memsql)或使用索引(如ElasticSearch)。这些加速服务系统以牺牲扩展性和成本为代价,优化摄入和扫描性能。因此,这些系统的数据保留周期通常较短(30至90天或最多存储几TB数据)。对历史数据的分析则重定向到HDFS上的查询引擎,因为数据延迟在此场景下无关紧要。
HDFS作为统一服务层的必要条件
若要将HDFS作为统一服务层,它需要满足以下要求:
- 快速变更能力
:支持对大型HDFS数据集快速应用变更 - 分析优化存储
:使用列式文件格式(如Parquet)优化扫描性能 - 级联更新支持
:高效链式传播更新到建模数据集
即使业务分区字段是事件发生时间,压缩后的业务状态仍可能因延迟到达的数据或事件时间与处理时间的差异而需要更新旧分区。即使分区键是处理时间,出于审计合规或安全原因,仍可能需要更新数据。
Hudi简介
Hudi(Hadoop Upsert Delete and Incremental)是一个支持上述需求的增量框架。它提供了一种面向分析的、扫描优化的数据存储抽象,能够在几分钟内对HDFS数据进行变更,并支持增量处理链。
Hudi数据集通过自定义的InputFormat与现有Hadoop生态系统(包括Apache Hive、Apache Parquet、Presto和Apache Spark)集成,对终端用户无缝透明。
数据流模型与用例分布
数据流模型根据延迟和完整性保证对数据管道进行分类。下图展示了Uber工程团队中不同用例的分布及其处理方式:
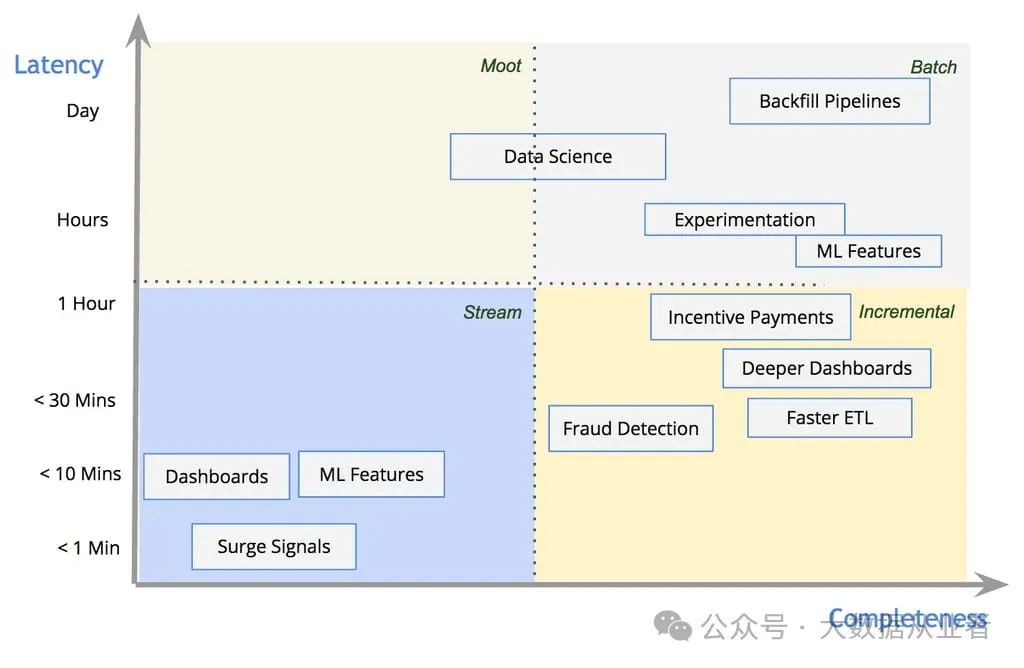
- 近实时(~1分钟延迟)
:依赖记录级流处理(如简单业务指标看板) - 传统批处理
:用于机器学习等重型计算场景 - 准实时复杂处理
:通过Hudi的增量处理原语实现复杂连接和大规模数据计算
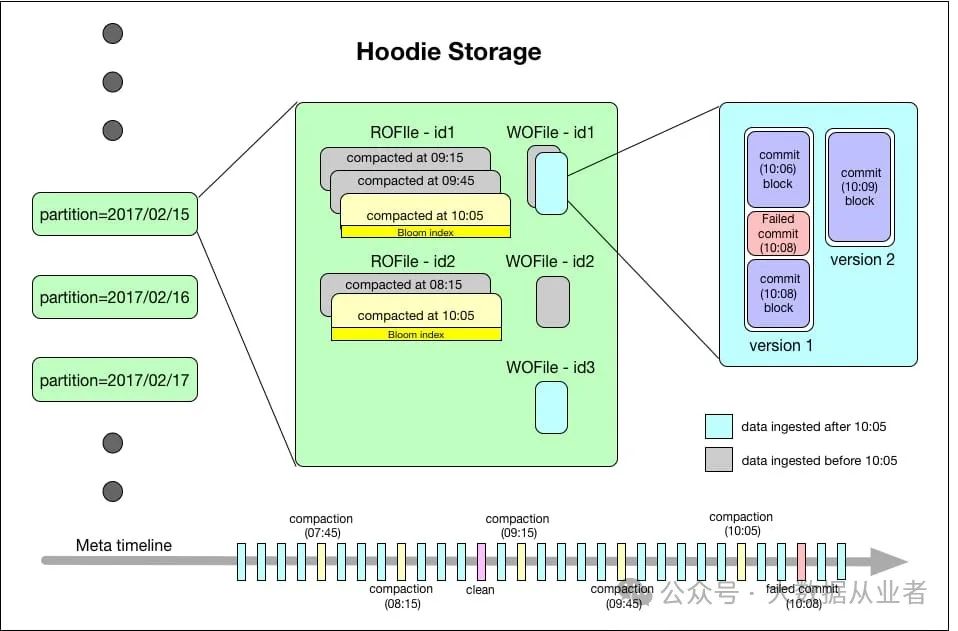
存储架构
Hudi数据集在基础路径下按分区目录结构组织(类似于Hive表):
- 分区路径
:目录包含该分区的数据文件 - 文件标识(fileId)
:唯一标识数据文件,多版本文件可共享相同fileId - 记录键(record key)
:唯一标识记录,与fileId永久绑定
Hudi存储由三部分组成:
元数据时间线
- 提交(Commits)
:原子写入操作的元数据,按单调递增时间戳标识 - 清理(Cleans)
:后台删除不再使用的旧文件版本 - 压缩(Compactions)
:将行式日志文件转换为列式格式 索引系统
- 布隆过滤器
:内置于Parquet文件页脚,无外部依赖 - HBase索引
:支持小批量键的高效查找 数据存储
- 读优化格式(ROFormat)
:默认Apache Parquet - 写优化格式(WOFormat)
:默认Apache Avro
写入路径与优化
写入流程
- 更新/插入标记
:通过布隆过滤器索引识别记录类型 - 插入处理
:按分区分配新fileId,写入日志文件直至达到HDFS块大小 - 异步压缩
:优先级队列调度,优先合并大日志文件 文件优化
- 块大小对齐
:文件大小匹配HDFS块大小(默认128MB) - 自动纠错
:后续插入将小文件视为更新目标,逐步合并至块大小 故障恢复
- 写入失败
:通过提交元数据跳过部分写入的Avro块 - 压缩失败
:查询层过滤未完成版本,下次压缩自动重试
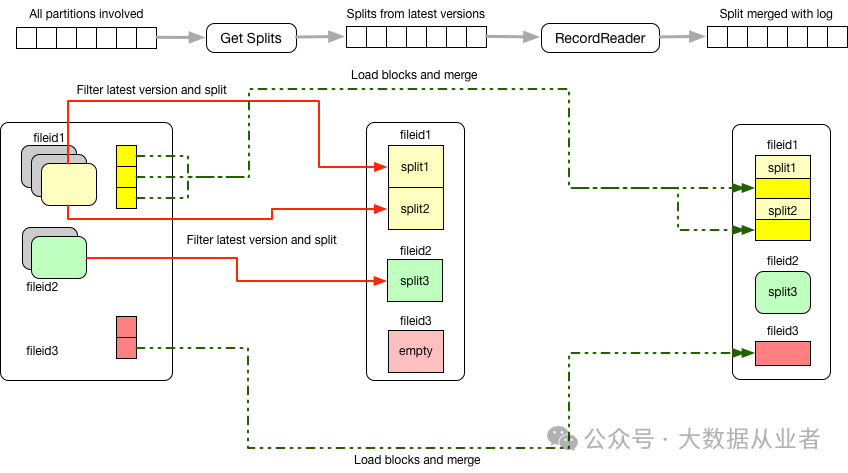
查询路径
Hudi提供两种视图:
- 读优化视图
:仅使用最新压缩的Parquet文件(小时级延迟) - 实时视图
:合并Parquet文件与增量日志(分钟级延迟)
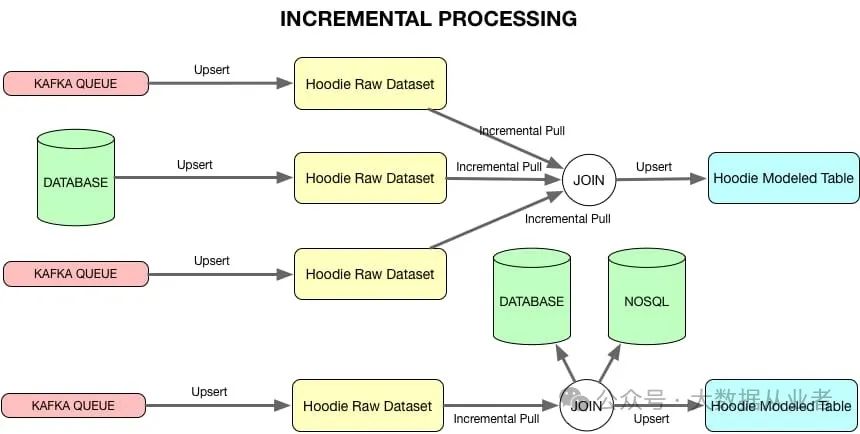
增量处理
Hudi通过元数据时间线支持增量变更集提取:
- 时间窗口过滤
:选择特定提交范围内的文件版本 - 流式连接
:支持带水位的流-流连接和流-数据集连接
总结
Hudi通过以下创新将HDFS升级为统一服务层:
- 混合存储模型
:结合列式(Parquet)和行式(Avro)格式平衡读写性能 - 增量处理范式
:支持分钟级延迟的更新传播和ETL链 - 无缝生态集成
:兼容Spark、Hive、Presto等主流工具
