




PolarDB PostgreSQL版索引预读原理介绍
关于 PolarDB PostgreSQL 版
PolarDB PostgreSQL 版是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 、Ganos全空间数据处理能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB PostgreSQL 版具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载。
索引相关背景介绍
在典型的TP业务中,通常会对频繁查找的列创建索引以避免对表的全表扫描。通过索引树可以精确的定位到所需的数据位于哪些数据页面上,仅需几个IO和内存跳转就能定位到所需的数据。
然而,当需要扫描的数据量较多时,比如扫描数据量在1000多行时,可能需要1000次读IO,这个过程中IO占整个SQL的执行时间超过99%。
通常新的业务数据会插入到比较新的Heap页面中,也就是Heap页面中的数据是没有顺序的,也就意味着传统的依靠文件系统的预读无法发挥作用。
本功能在索引扫描的算法中,通过叶子页面中存储的行指针,定位当前SQL接下来需要读取的Heap表页面号,并提前预读以优化索引扫描的IO性能。
索引扫描IndexScan的IO模型
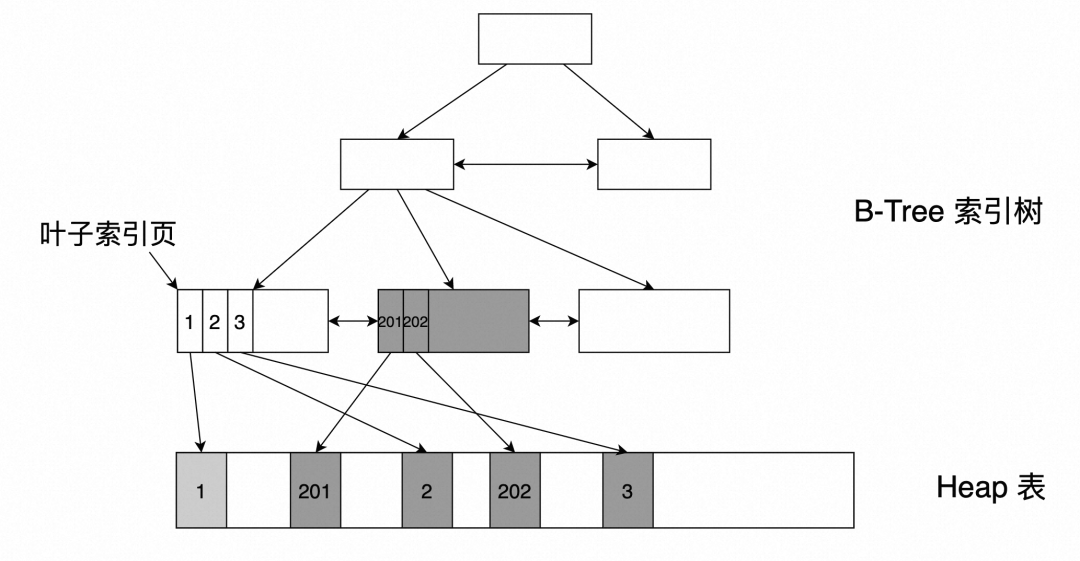
如上图所示,PG索引树的叶子节点存储了指向Heap表的行指针itup。在进行索引扫描IndexScan时:
首先先从索引树ROOT页面往下查找到具体的叶子节点页面;
从叶子节点页面读取到多个itup指针;
逐个通过itup指针定位Heap表的页面号,并从存储上读取Heap表页面到Buffer中进行后续处理;
上述过程也称为回表,如下图所示,这个过程是串行化的:
先读取索引树的数据页面;
再读取n个Heap表页面;
Heap表页面在存储上的排列是无规律近似随机的,传统的依靠文件系统的预读机制无法发挥预取的作用。

索引扫描IndexOnlyScan的IO模型
当索引树上的索引列是SQL中涉及到的列的超集时,也就是仅通过扫描索引树就能查询到SQL中的全部信息时,会使用IndexOnlyScan仅对索引树进行扫描,避免回表产生的额外IO。
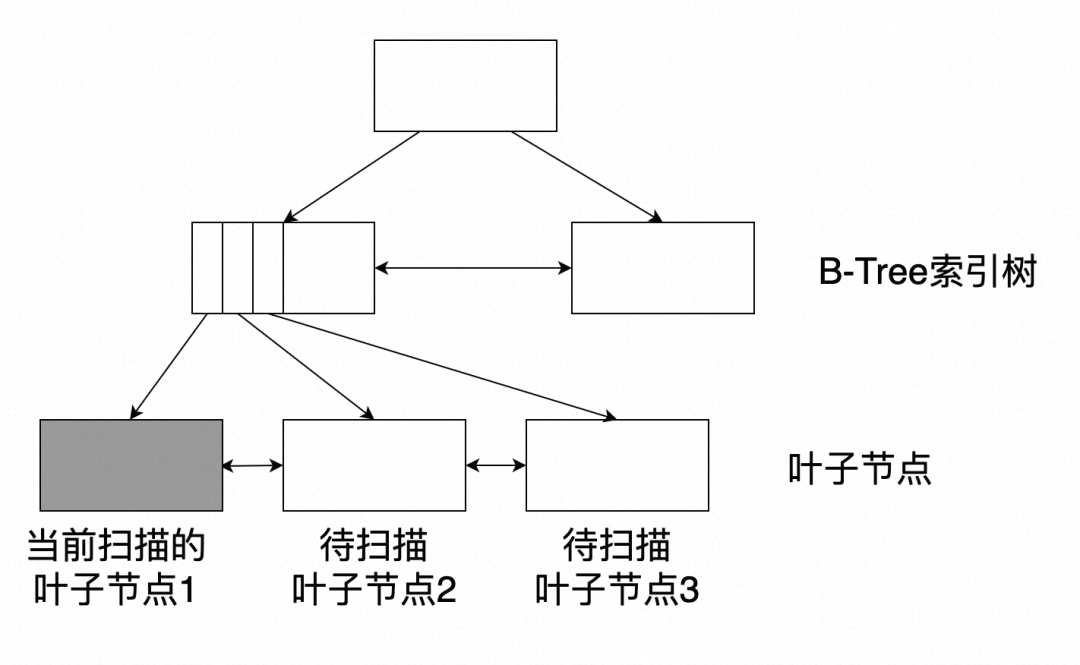
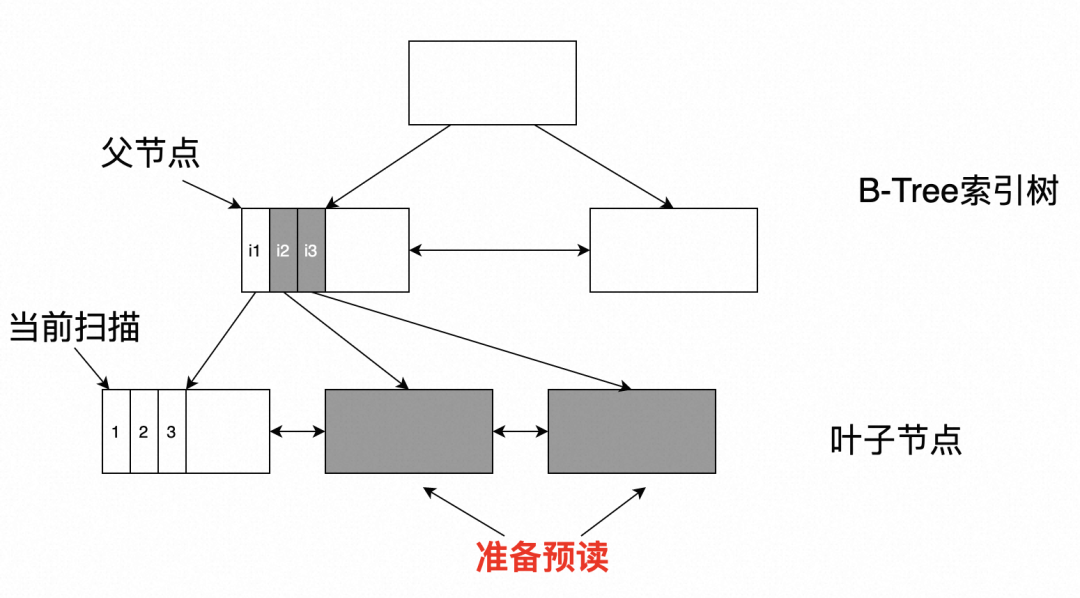
如下图,PG中的索引树是BLink树,每层的节点之间通过指针互相连接。当进行索引扫描时,首先定位到某个叶子节点,当扫描完该节点时,再通过该节点页面存储的next指针得到下一个节点的页面号,并读取到Buffer中进行处理。
索引树的页面在存储上的排列也是无规律近似随机的,该过程只能通过当前节点的next指针找到下一个页面号。因此,传统的依靠文件系统的预读机制也无法发挥预取的作用。
PolarDB-PG的索引预读原理介绍
索引扫描IndexScan的预读原理
如下图所示,在索引扫描的算法中,在读取到索引树的叶子页面,通过叶子页面能够得到多个指向Heap表的行指针,从行指针中提取出接下来要读取的Heap表页面号,并逐个通过异步IO提前预读。
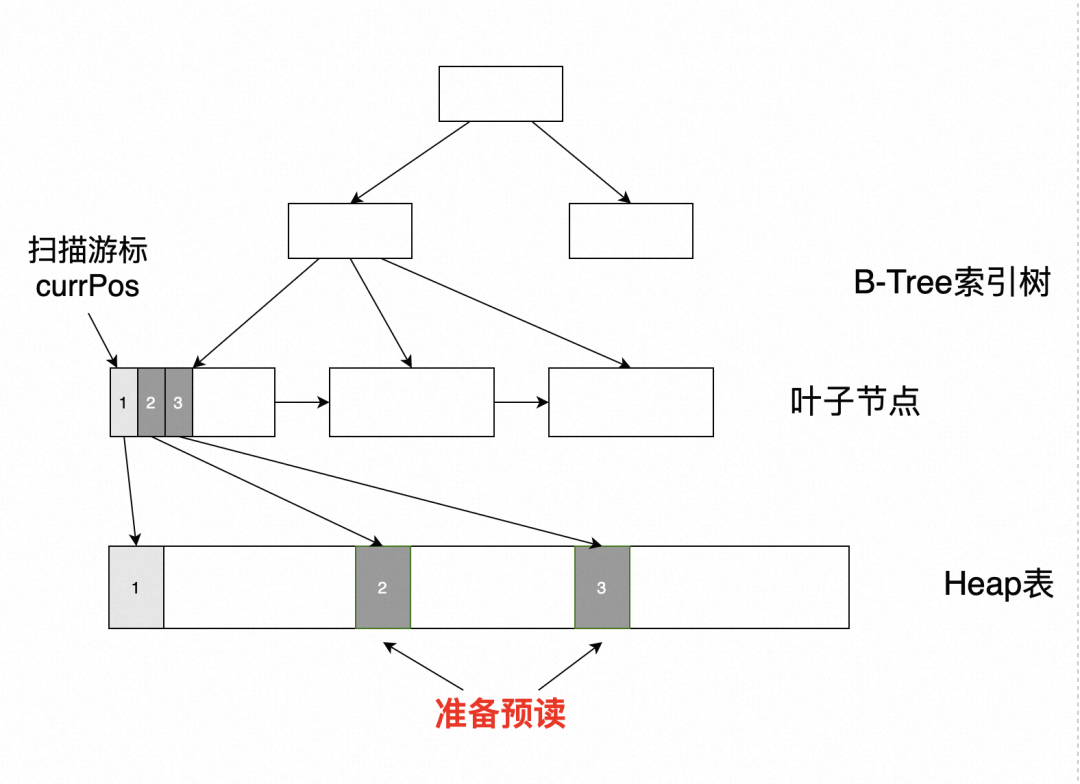
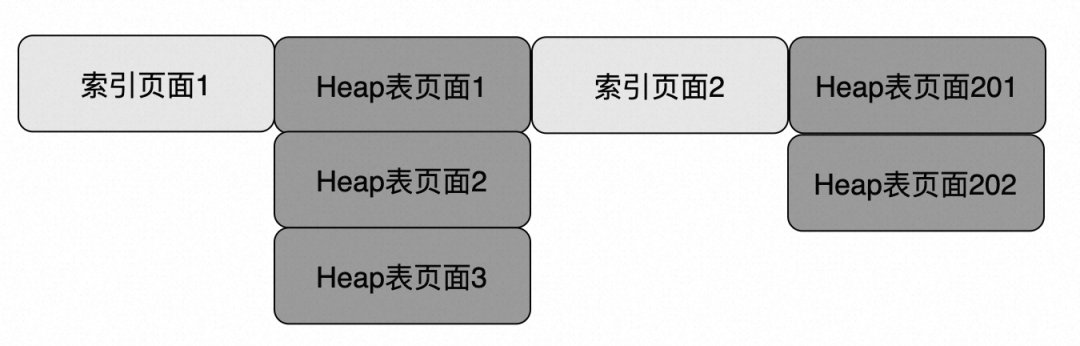
将原来的串行读取优化为异步读取,大大提升了IO的效果。如下图所示:
索引扫描IndexOnlyScan的预读原理
如下图所示,当进行索引扫描时,首先定位到某个叶子节点,过程中记录父节点,通过父节点存储的指针提取出该叶子节点的一系列兄弟节点,对这些叶子页面逐个通过异步IO进行预读。
使用指南
索引预读的场景
目前仅支持对用户的业务表索引,且索引类型是BTree索引支持预读。
IndexScan预读
IndexScan预读功能默认关闭,参数名为polar_enable_aio_prefetch和polar_enable_aio_index_prefetch
开启IndexScan索引预读的功能:
set polar_enable_aio_prefetch = 1;
set polar_enable_aio_index_prefetch = 1;
关闭IndexScan索引预读的功能:
set polar_create_index_prefetcher = 0;
set polar_enable_aio_index_prefetch = 0;
IndexOnlyScan预读
IndexScan预读功能默认关闭,参数名为polar_enable_aio_prefetch和polar_enable_aio_index_only_prefetch
开启IndexScanOnly索引预读的功能:
set polar_enable_aio_prefetch = 1;
set polar_enable_aio_index_only_prefetch = 1;
关闭IndexScanOnly索引预读的功能:
set polar_enable_aio_prefetch = 0;
set polar_enable_aio_index_only_prefetch = 0;
性能对比
数据准备
create table t001(id int, age int, msg text);
insert into t001 select random() * 1000000, random() * 10000, md5(random()::text) from generate_series(1, 1000000) as i;
create index t001_id on t001(id);
注意:在进行下面的索引扫描测试前,可以通过读取其他表以便将表t001和t001_id的数据页面换出,仅测试发生了IO时的性能。
默认索引扫描
可以看出使用了索引扫描,命中了1125次IO,读取了3914次IO,总执行时间449ms。
postgres=# explain (analyze, timing, buffers) select avg(age) from t001 where id < 5000;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=16519.65..16519.66 rows=1 width=32) (actual time=449.597..449.599 rows=1 loops=1)
Buffers: shared hit=1125 (main=1125 vm=0 fsm=0) read=3914 (main=3914 vm=0 fsm=0)
-> Index Scan using t001_id on t001 (cost=0.42..16506.70 rows=5180 width=4) (actual time=0.222..447.084 rows=5025 loops=1)
Index Cond: (id < 5000)
Buffers: shared hit=1125 (main=1125 vm=0 fsm=0) read=3914 (main=3914 vm=0 fsm=0)
Planning:
Buffers: shared hit=1 (main=0 vm=1 fsm=0) read=3 (main=3 vm=0 fsm=0)
Planning Time: 0.779 ms
Execution Time: 449.698 ms
开启索引扫描预读
使用上述方法开启IndexScan的预读后,可以看出同样是使用了索引扫描,实际都发生了3914次IO,3914的读取中有3767次是通过异步IO提前预读上来的。总体共有4892次命中,比未开启预读的命中次数1125正好多出了3767次IO,而IndexScan的关键路径上仅读取了147次IO。
总执行时间88ms。
postgres=# explain (analyze, timing, buffers) select avg(age) from t001 where id < 5000;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=16519.65..16519.66 rows=1 width=32) (actual time=88.738..88.740 rows=1 loops=1)
Buffers: shared hit=4892 (main=4892 vm=0 fsm=0) read=147 (main=147 vm=0 fsm=0) waitio=928 aiohit=1104 aioinitiate=3767 aiowakeup=658 waittime=49.634
Prefetches: hit=1104 initiate=3767 rounds=13
-> Index Scan using t001_id on t001 (cost=0.42..16506.70 rows=5180 width=4) (actual time=0.233..86.946 rows=5025 loops=1)
Index Cond: (id < 5000)
Buffers: shared hit=4892 (main=4892 vm=0 fsm=0) read=147 (main=147 vm=0 fsm=0) waitio=928 aiohit=1104 aioinitiate=3767 aiowakeup=658 waittime=49.634
Prefetches: hit=1104 initiate=3767 rounds=13
Planning:
Buffers: shared hit=1 (main=0 vm=1 fsm=0) read=3 (main=3 vm=0 fsm=0)
Planning Time: 1.342 ms
Execution Time: 88.831 ms
(11 rows)
