




PolarStore EMP
数据库的Buffer Pool 是缓存磁盘数据的内存区域。若数据在Buffer Pool中未命中,则需要从底层存储中获取数据,相比内存访问,I/O操作会增加网络和读盘的延迟,这将直接影响数据库的性能。由于单机主机的内存限制,Buffer Pool的空间会非常有限,因此在I/O密集型负载下,使用EMP能提升数据加载到Buffer Pool的速度,降低IO延迟,从而提升PolarDB的整体性能。
EMP是计算节点通过RDMA高速网络访问存储节点上的高速介质,RDMA的延迟为10us+,内存访问速度为几us,总延迟为20~30us,性能较好的本地的NVMe访问延迟通常为100us+,因此EMP最多降低至原有延迟的1/5。
PolarDB使用的存储层是PolarStore提供的Volume,每个Volume被分成多个Chunk,Chunk分布在不同的节点上,每个Chunk维护三个副本,三个副本分别在不同的存储节点上。计算节点上部署PolarSwitch 服务,可以转发数据库的I/O请求,计算节点和存储节点之间通过高速网络RDMA互联,计算节点可以和若干的存储节点互联,因此PolarStore提供的分布式存储可以弹性的扩展和缩小。每个存储节点上包含的高速介质空间有限,但EMP是在存储集群上实现的,是集群级别的内存池,同时拥有分部署存储的弹性能力,可以给单个PolarDB集群提供非常大的缓存空间。
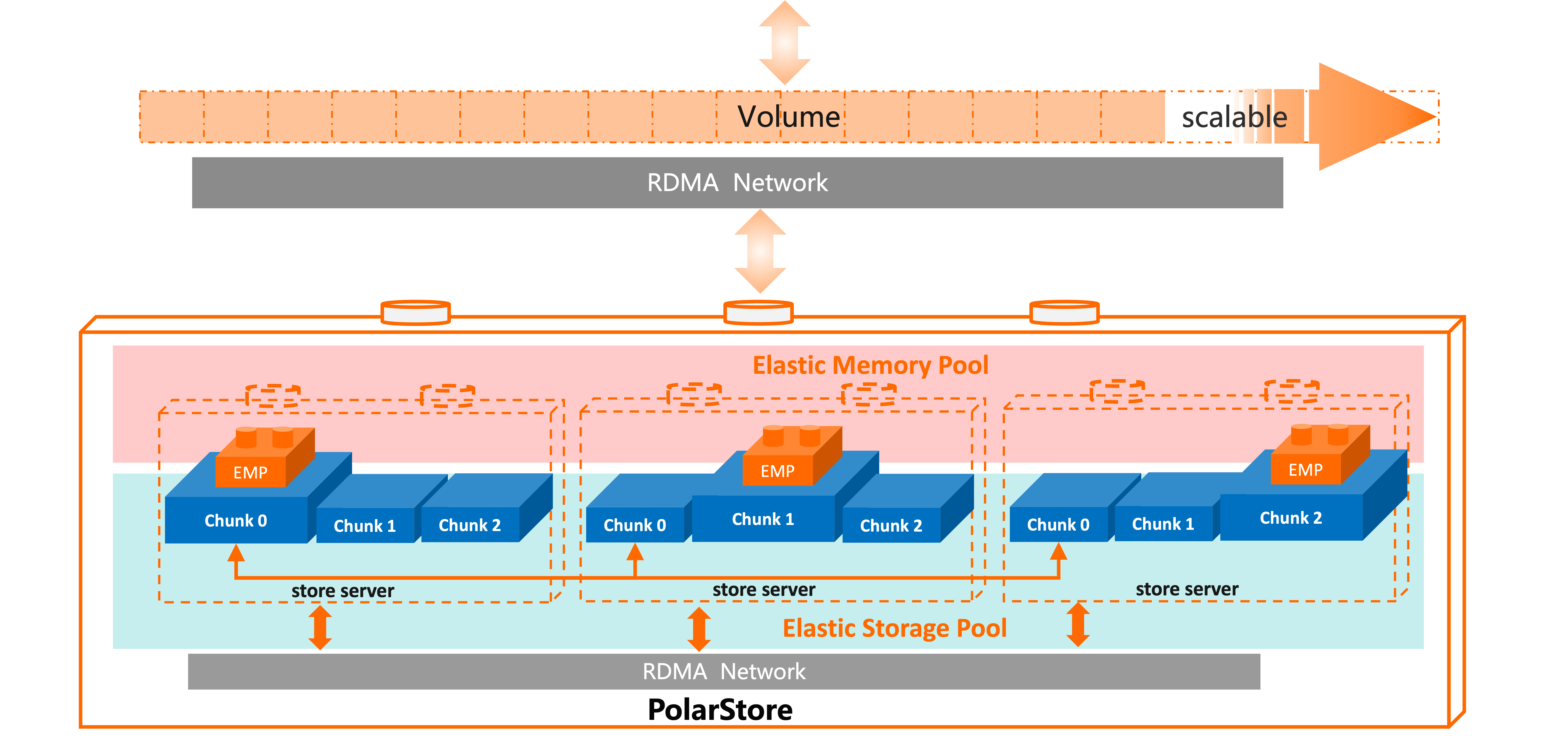
看到这里可能存在疑问,高速介质包括内存、持久化内存等在一个节点上的资源毕竟是有限的,相对于节点上大容量的NVMe SSD无法全部做Cache,那么Cache的命中率如何保证呢?
Cache的数据内容不是单纯的NVMe SSD的数据部分,而是针对PolarDB的特点做出针对性的选择,提高Cache的命中率,主要有以下几个方面:
三副本一份Cache:对于PolarStore来说,每个Chunk都是三副本的,是高可用的保证,但数据访问仅仅读三副本中的Leader,因此两个副本是不需要占用Cache空间的。
快照无需Cache:PolarDB给用户提供秒级快照的功能,一级快照的数据和原始数据都位于PolarStore上,而快照的访问不是关键路径,因此快照数据无需Cache。
备实例无需Cache:PolarDB有跨区容灾的能力,有primary和standby两个集群,用户只会访问primary集群,standby集群无需Cache。
DB文件部分Cache:PolarDB建立I/O请求全链路打标的能力,对DB的不同文件类型或重要的表进行打标,标记有PFS元数据请求、Redo Log文件、Bin Log文件、IBD数据文件、Undo Log 文件等等,不同的文件访问模式不同,Bin Log文件或Redo文件是类流式顺序读写,写性能影响更大,IBD文件是用户的表文件,用户SQL查询表文件是随机读写访问,因此读Cache应该缓存用户关键路径的表文件。
Cache淘汰算法:EMP采用和Buffer Pool类似的算法,可以防止大批量的扫表将EMP中数据全部冲掉,来提高Cache的命中率。EMP的Cache策略还在不断更新调整,将更多的数据库请求的特点通过请求携带给Store做到更精准的预测。
EMP和Buffer Pool的关系:
数据不互斥。EMP位于存储节点,而Buffer Pool位于计算节点,若数据互斥需要在两个组件之间交互,会增加很多无用的操作,增加复杂性和资源开销,因此EMP通过I/O请求携带信息的方式决策是否Cache,而不是强烈追求数据互斥。此外PolarDB支持一写多读,会有多个节点访问同一份存储,相比简单的一对一的方式,由I/O携带信息由存储节点EMP判断是否Cache失效更为有效。
EMP空间较Buffer Pool大。上面的分析中可以看出EMP的空间是可弹性扩展的,而Buffer Pool的空间是确定的。在I/O密集型场景下,Buffer Pool确定命中率的情况下,EMP的命中率越高性能提升越明显。Buffer Pool位于计算节点,是最接近用户请求的位置,Buffer Pool命中率提升是直接决定请求性能的,但Buffer Pool的算法和空间比较固定,EMP能够在Buffer Pool命中率不易提升时从I/O的角度提升请求性能。
The MySQL Query Cache
Query Cache是将SELECT语句和执行的结果都做缓存,若之后收到相同的语句,服务器可以从Query Cache中检索结果,而不需要再次解析执行该语句。Query Cache是在会话之间共享,即前面有客户端查询过生成结果之后可以作为另一个客户端做相同的查询时返回,能够加速SELECT语句的执行。
若使用场景是数据表不经常修改,客户端会做相同的查询时,Query Cache能够十分高效的返回结果。
Query Cache是将SQL语句、数据库等作为Key,将查询结果作为Value,存在一个Hash表中,收到一个SQL查询时,会检索Cache,当Key全部匹配时,才会判定为命中。Query Cache在分库分表的环境下不起作用。
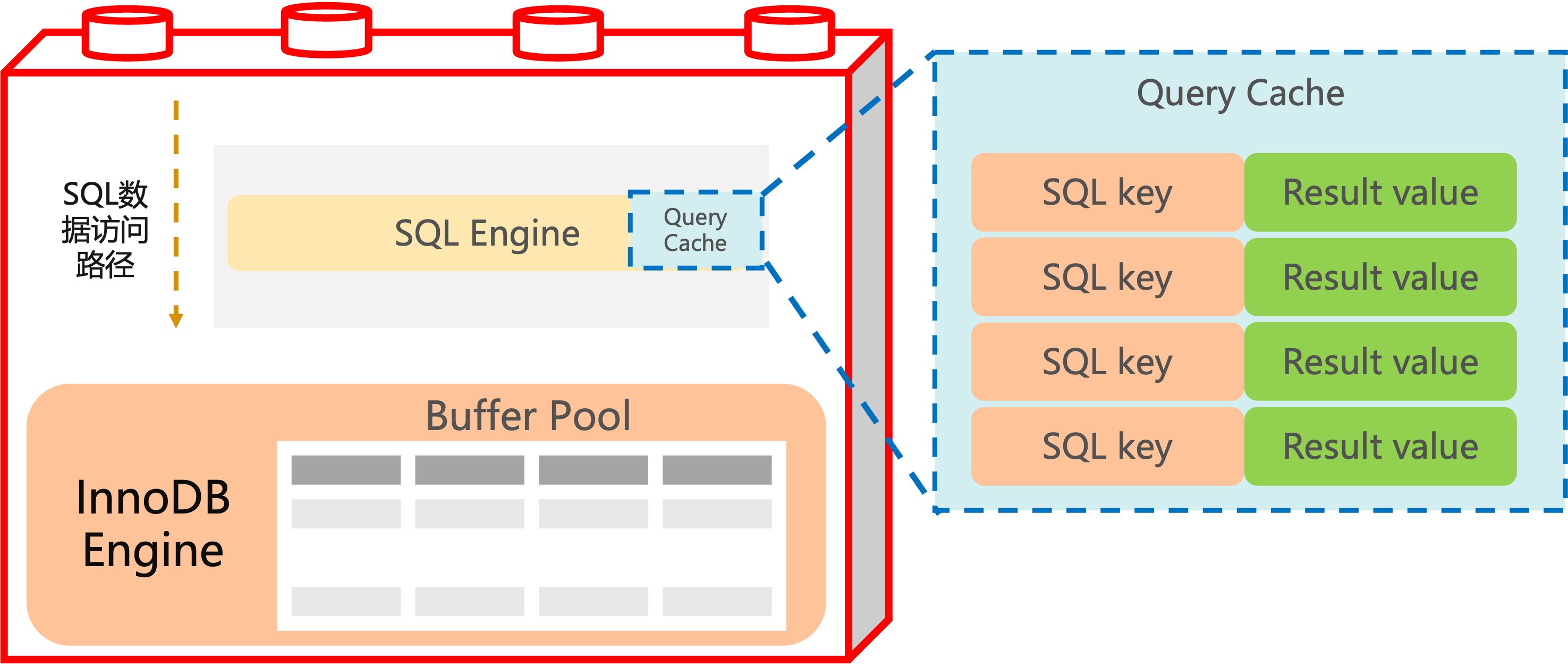
MySQL中参数query_cache_size可以配置Query Cache的大小,当设置为0时,则禁用Query Cache。
通常建议大小设置为几十MB,Query Cache不是越大越好,设置的过大会增加维护Cache所需的开销。
若查询的数据表经常做修改,不建议开启Query Cache,因为表内容修改会使Query Cache失效。
PolarDB中针对原有实现的不足和云原生数据库高并发的特点进一步优化实现,优化了并发控制、内存管理和缓存机制,详见Fast Query Cache
Query Cache和Buffer Pool相比:
Query Cache使用场景比较固定,若命中能大大降低服务器内存访问和计算等开销,但使用场景较为单一,需使用者根据场景选择使用,若使用不当反而性能会降低,Buffer Pool是数据库最通用的Cache,命中与否不会降低计算开销,只影响访问Page开销。
Query Cache不是在所有场景下都是优化,SQL命中条件比较严格,若使用不当或配置不当时,可能带来额外的开销。
Redo Cache
PolarDB是一写多读的架构,一个集群包含一个主节点和最多15个只读节点。RW节点处理读写请求,RO只处理读请求,RW和RO之间需要同步Redo Log,初始版本时RW仅仅需要和RO同步Redo Log的元数据信息,即通知RO Redo Log有更新,RO自发的从分布式存储中读数据。RW和RO共享一份存储数据,RW写的位置也是RO读的位置,RO数量越多,越容易在同一个存储节点上行成I/O热点,导致I/O的延迟变高,反应在DB业务中为QPS明显下降。
因此在RW侧增加Redo Cache,即在RW上缓存一部分Redo文件,同步给RO,大大降低了RO上读Redo Log的I/O开销,能够避免多个RO同时读Redo造成存储热点,影响DB性能。
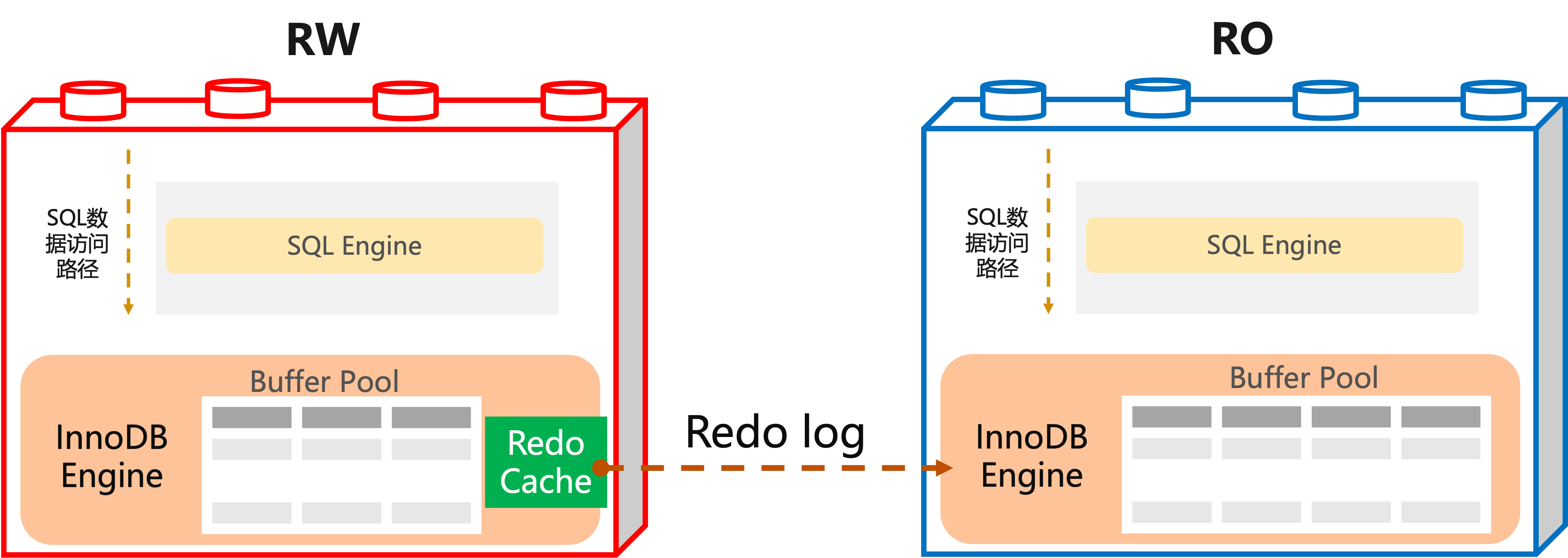
Redo Cache是针对PolarDB一写多读场景的优化,用户无需自行配置,Redo Cache的优化为很多Redo 高写入的场景下性能稳定起到了非常重要的作用,“润物无声”的规避了高压力下的潜在问题。
总结
PolarDB-MYSQL 计存分离的架构设计,能够满足云计算环境下的很多需求,多种Cache类型有针对场景的优化,Redo Cache是针对PolarDB 一写多读架构的优化,用户无需配置。Query Cache、Buffer Pool、PolarStore EMP在PolarDB架构中从上到下分布、空间由小到大、命中率递增、访问速度递减,各自有自身的优缺点:
Query Cache 针对不常修改的表,并且有大量相同SQL查询时性能提升明显。但表频繁更新,不同SQL查询没有优化。
Buffer Pool 是InnoDB最重要的组件之一,所有SQL都需要通过Buffer Pool访问数据,提升命中率能够大大提升DB的性能。但空间有限,单机不易扩展,随着数据库的容量不断变大,Buffer Pool的命中率逐渐降低。
PolarStore EMP为DB提供大容量内存池化的能力,在I/O密集型场景下能够大大降低I/O延迟,提升DB性能。但由于数据位于存储节点,需要经过高速网络访问。
