




二、全局Top-K阈值维护
这一步和并行Top-K实现中的概念相同。我们来复习一下,Top-K阈值的含义是,某个时刻,有超过K个元素大于该阈值。该阈值大于等于最终结果中的第K大值Kth。它是动态变化,并且不断逼近Kth的。当元素比阈值小,就不可能出现在最终的Top-K结果集中。Top-K阈值因此可以用于指导Top-K算子在数据筛选过程中,尽可能排除不符合条件的数据。
所有并行度之间共同维护一个变量 Vk,它表示当前全局已知的第K大值,可能是一个单列的列值 val_col,也可能是多列的数值共同组成的向量 {val_col1, val_col2, ..., val_colx} 。随着不同并行度间的算子协作,Vk逐渐收敛到真实的总体第K大值Kth。
- 起始状态:Top-K算子刚初始化时,全局元素数量为0,此时无法计算得到当前第K大值
- 元素总数更新:在某一并行度上,当有一行数据写入Top-K算子中,就会更新各个并行度写入Top-K算子的元素总和,这个更新过程是原子性的、并发安全的。
- Vk值初始化:当全局元素总数等于K 时,对于所有Top-K算子内部维护的堆,获得堆顶元素
- 第3步的原理是,总线程数为m,每个线程维护一个堆
,那么,当m个线程上的堆元素大小之和等于K时,这些堆他们共同组成了一个大小为K的元素集合,设
4. Vk值的并发更新:当Vk数值初始化之后,各个并行度开始并发安全地更新Vk值。在所有并行度上,每当写入一个元素到Top-K算子时,都尝试比较和更新 Vk 值,以期尽可能提高Vk值并更快速地收敛。具体过程如下:
- 一个线程i上的一个Top-K算子写入一个数据a时,将其与全局的Vk值进行比较;
- 如果 a < Vk,则丢弃 a(因为 a 不可能进入最终的 top-k )。
- 否则,将a写入该线程上Top-K算子的堆中(此步骤也需要遵循Top-K算子的一般流程,即如果堆不满K个元素,直接写入堆;否则和堆顶比较,只有大于堆顶元素才写入堆)。堆结构自动更新并选出堆顶h。
- 选取堆顶h,进行并发安全的比较和更新:
在单线程执行Top-K过程中,天然的,当堆的元素数量达到K时,堆顶即是当前的阈值,堆顶的变化即是阈值的更新。对比上述多线程共同进行全局Top-K阈值维护的方法,单线程维护阈值逼近最终Top-K结果集中的Kth值的速度更慢,产生阈值的时间更晚。
具体实验室数据,对于TPC-H 100GB标准测试集,执行 select * from lineitem order by l_partkey desc limit 10000,10 进行阈值变化情况统计。 对单线程更新本地阈值,和2,4,8线程维护全局阈值进行对比,结果如下:
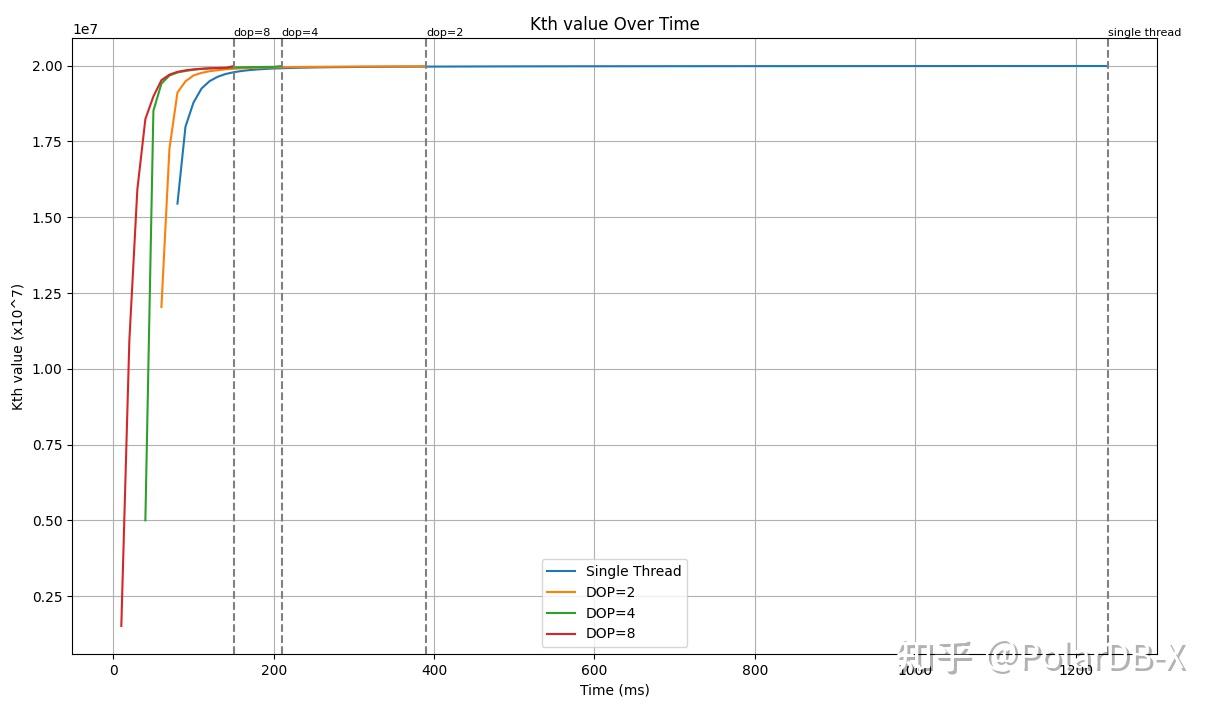
(如果SQL是 order by l_partkey asc limit 10000,10,那么曲线会变成从最值逐渐递减和收敛到一个较小的Kth值。)
三、基于阈值的提前终止文件读取
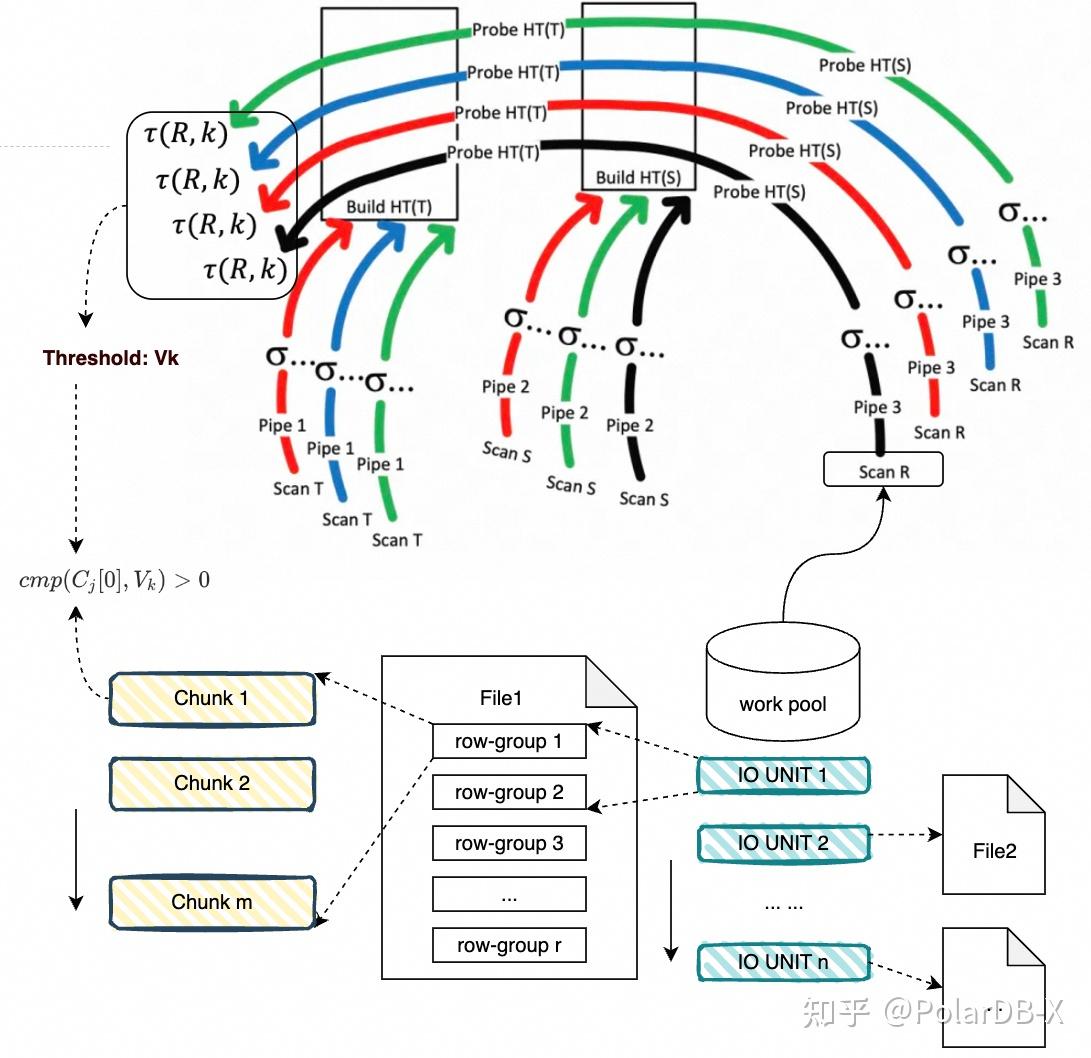
(一) 文件读取任务管理
为了充分利用阈值对每个文件进行读取过程的提前终止,每个线程内都存在一个工作池(Work Pool)来管的扫描任务。设文件集合为:
每个线程从各自的工作池中获取扫描任务。在线程内部,采用交错文件读取策略,以避免集中处理单个文件,使得计算过程中,较多数据没有在Join / Filter的结果中保留下来,也就无法形成Top-K输入并计算出Top-K阈值。
具体策略是:
- 循环遍历文件集合F,当一轮遍历完成后,重新遍历;
- 对于遍历到的每个文件,按照顺序提取文件中的下一个IO单位来执行,它和文件中上一个IO任务字节位置相邻。其中,
- 如果Top-K排序列和文件排序键的关系是正序或前缀正序,那么采取顺序方式,从文件首部开始提取;
- 如果是逆序或前缀逆序,采取逆序方式,从文件尾部开始提取。
3. 每个文件仅选取一个IO单位/任务,就继续遍历下一个文件;
4. 当文件没有更多的IO任务,将文件从集合F中移除;
5. 直到集合中不存在文件时,终止遍历。
这种交错读取确保了单个线程在处理多个文件时,能根据阈值对每个文件都尽快终止读取流程。
IO单位的设计:
- row-group是IO的最小单位。每个 row-group 包含固定的r行数据,由存储层决定。
- 每个 IO 单位包含m个 row-group;
- 为了保证采集到足够的 Top-K 数据,每个 IO 单位的行数设计为略大于目标K。那么,m的选取方法是,对r求整数倍,刚好等于或略大于K值。
通过合理设置 m 和 r ,确保每个 IO 单位的行数满足上述近似关系,从而提升数据采集的效率。
每个row-group中包含若干个chunk,每个chunk包含多个列和1024行数据。为了提取chunk中排序列的数据,需要对row-group所属的IO单位执行IO操作,将数据读进内存再进行列解析。
(二) 基于阈值的提前终止文件读取
利用全局阈值
1. 正序扫描提前终止条件
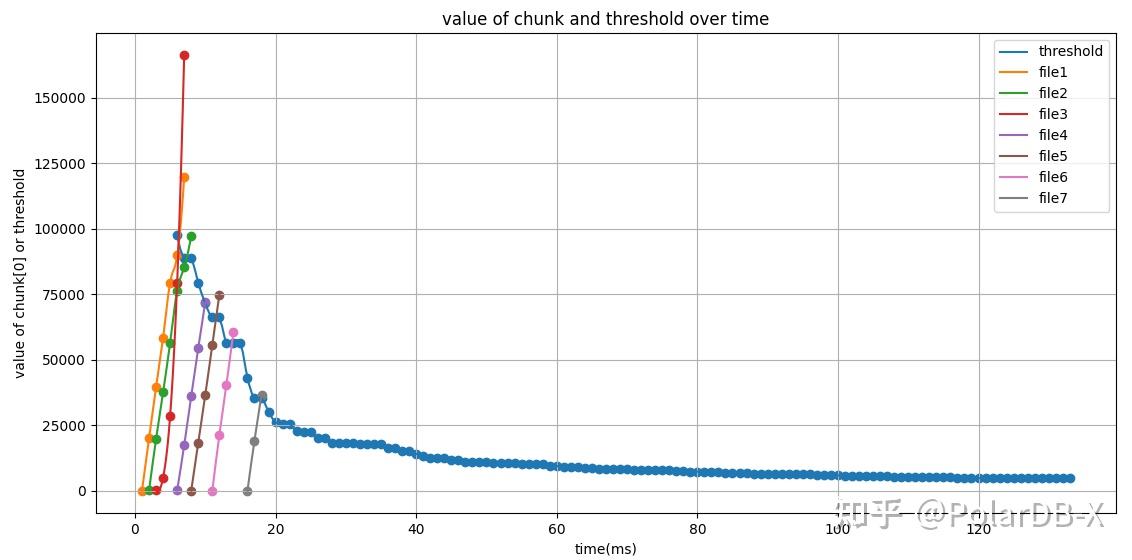
如果Top-K的排序列order_by_cols 与 文件的sort_key_cols的关系为正序或者前缀正序,那么在每个row-group内部,从首个chunk开始提取,提取顺序为
其中,
Cj[0]代表Chunk中的第一行。
cmp算法为:
- 完全正序关系,依次比较每一列,直到首次结果不为0时返回比较结果;
- 前缀正序关系,依次比较前缀中的每一列,直到首次结果不为0时返回比较结果。
一旦判定终止,则后续row-group内部所有的Chunk,以及所属文件中的后续所有row-group都不再进行IO、提取和计算操作,结束文件的读取任务,从workpool中移除。
下图展示在正序和正序前缀场景下,对于TPC-H 100G测试集,执行分页:select * from partsupp order by ps_partkey limit 10000,5 时,Top-K阈值随时间变化情况,以及线程内各个文件所产生的chunk,其第一行chunk[0]随时间变化情况。当chunk[0]数值超过此刻的Top-K阈值Vk时,则终止该文件的读取过程。
2. 倒序扫描提前终止条件
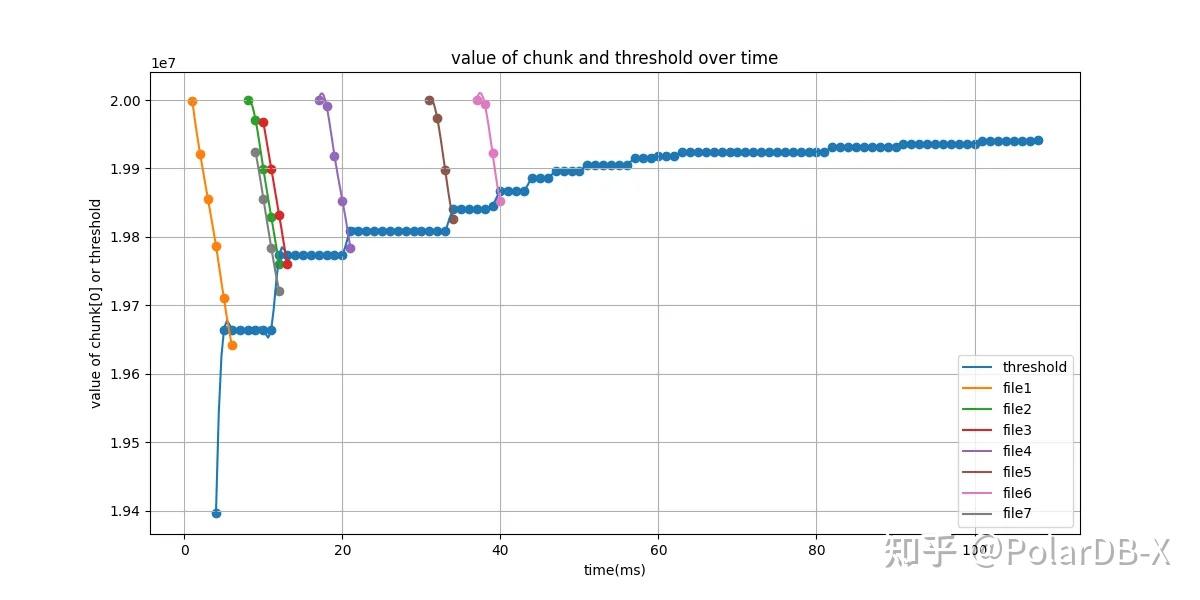
如果Top-K的排序列order_by_cols 与 文件的sort_key_cols的关系为逆序或者前缀逆序,那么在每个row-group内部,从最后一个chunk开始提取,提取顺序为:
Cj[end]代表Chunk中的最后一行。
cmp算法为:
- 对于逆序关系,依次比较每一列,直到首次结果不为0时返回比较结果;
- 对于前缀逆序关系,依次比较前缀中的每一列,直到首次结果不为0时返回比较结果。
一旦判定终止,则后续row-group内部所有的Chunk,以及所属文件中的后续所有row-group都不再进行IO、提取和计算操作,结束文件的读取任务,从workpool中移除。
下图展示在逆序和逆序前缀场景下,对于TPC-H 100G测试集,执行分页:select * from partsupp order by ps_partkey desc limit 10000,5 时,Top-K阈值随时间变化情况,以及线程内各个文件所产生的chunk,其最后一行chunk[end]随时间变化情况。当chunk[end]数值小于此刻的Top-K阈值Vk时,则终止该文件的读取过程。
四、整体流程
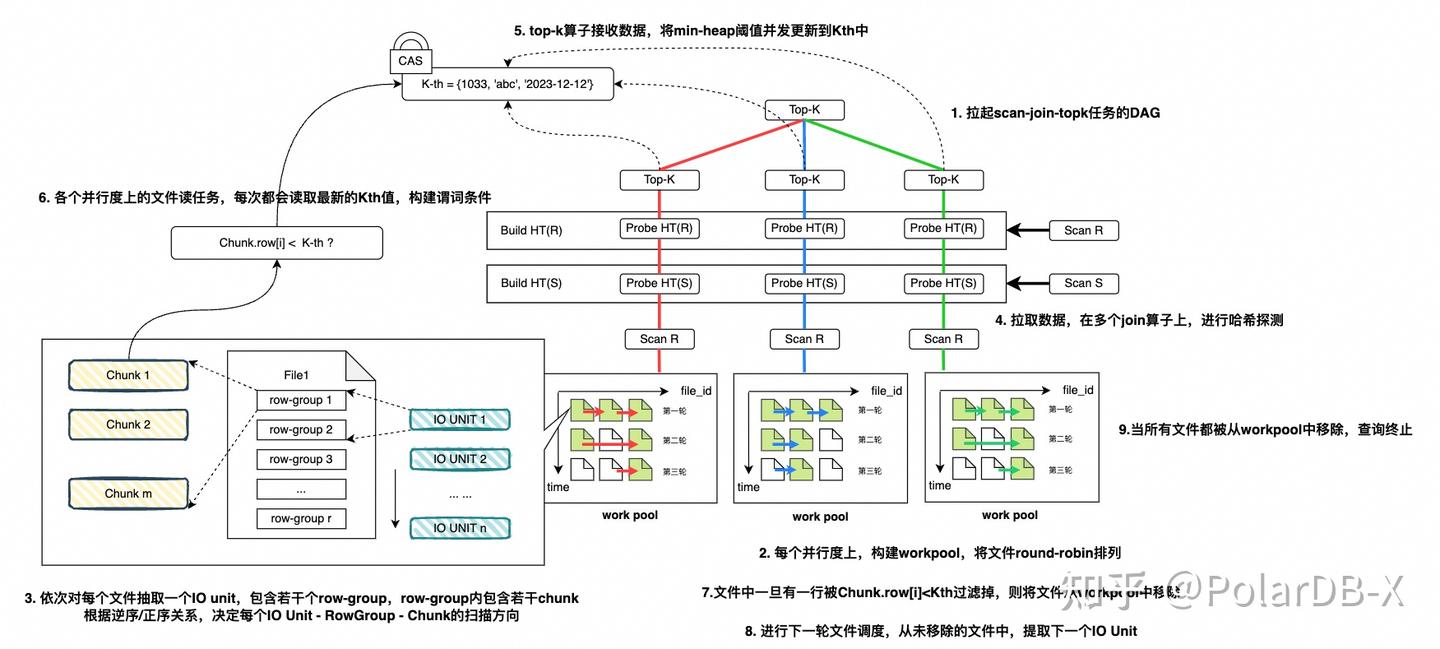
根据以上的步骤讲解,我们重新梳理一下,PolarDB-X执行器内部是如何处理复杂查询分页的:
- 首先,对于传来的用户SQL,执行器拉起一个DAG结构,用于执行scan-join-topk任务。
- DAG的每个并行度上,构建work-pool,将列存数据文件进行round-robin排列。
- 依次对每个文件抽取一个IO Unit,包含若干个row-group,row-group内部包含若干chunk。根据正序/逆序关系,决定每个IO Unit - Row-Group -Chunk的扫描方向。
- DAG利用scan算子从work-pool中拉取数据,并在多个Join算子上,进行哈希探测。
- DAG中的Top-K算子接收到Join输出的数据,将min-heap的top-k阈值并发更新到共享阈值中。
- 各个并行度上的文件读任务,根据共享阈值的瞬时值,实时构造出动态谓词条件。
- 每个文件中一旦有一行数据被动态谓词条件 Chunk.row[i] < Kth 过滤掉,就立即终止该文件的读流程,并将文件从workpool中移除
- 进行下一轮文件调度,从未移除的文件中,提取下一个IO Unit
- 当所有文件都从workpool中移除,终止查询,得到最终结果。
性能效果
- TPC-H 100G数据集
- 规格 2 * 16C 64GB
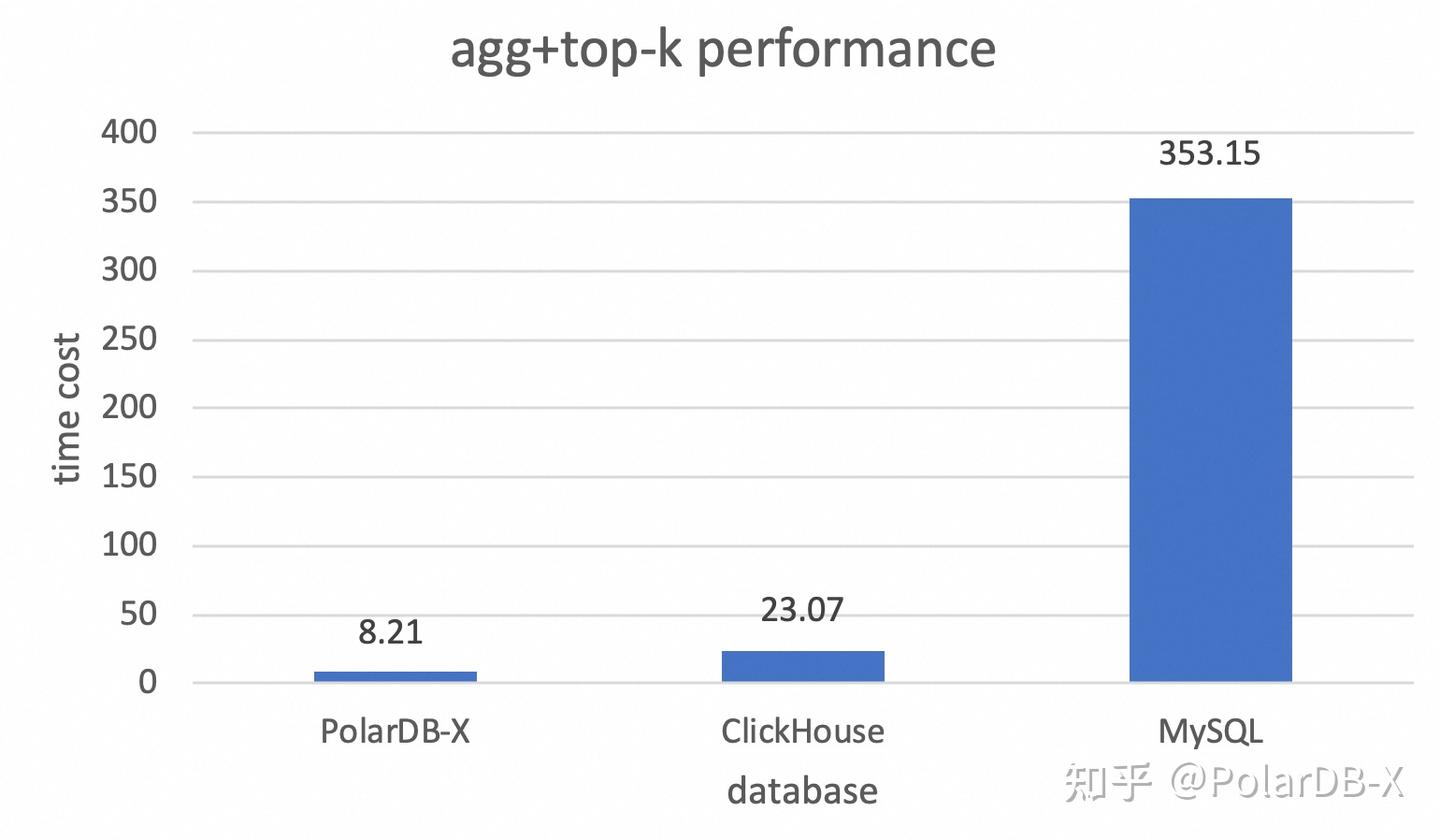
聚合结果分页查询
- SQL: select sum(l_quantity),l_orderkey from lineitem group by l_orderkey order by sum(l_quantity) desc limit 1000000, 10;
- 测试结果如下:
| PolarDB-X | ClickHouse | MySQL |
| 8.21 sec | 23.07 sec | 353.15 sec |
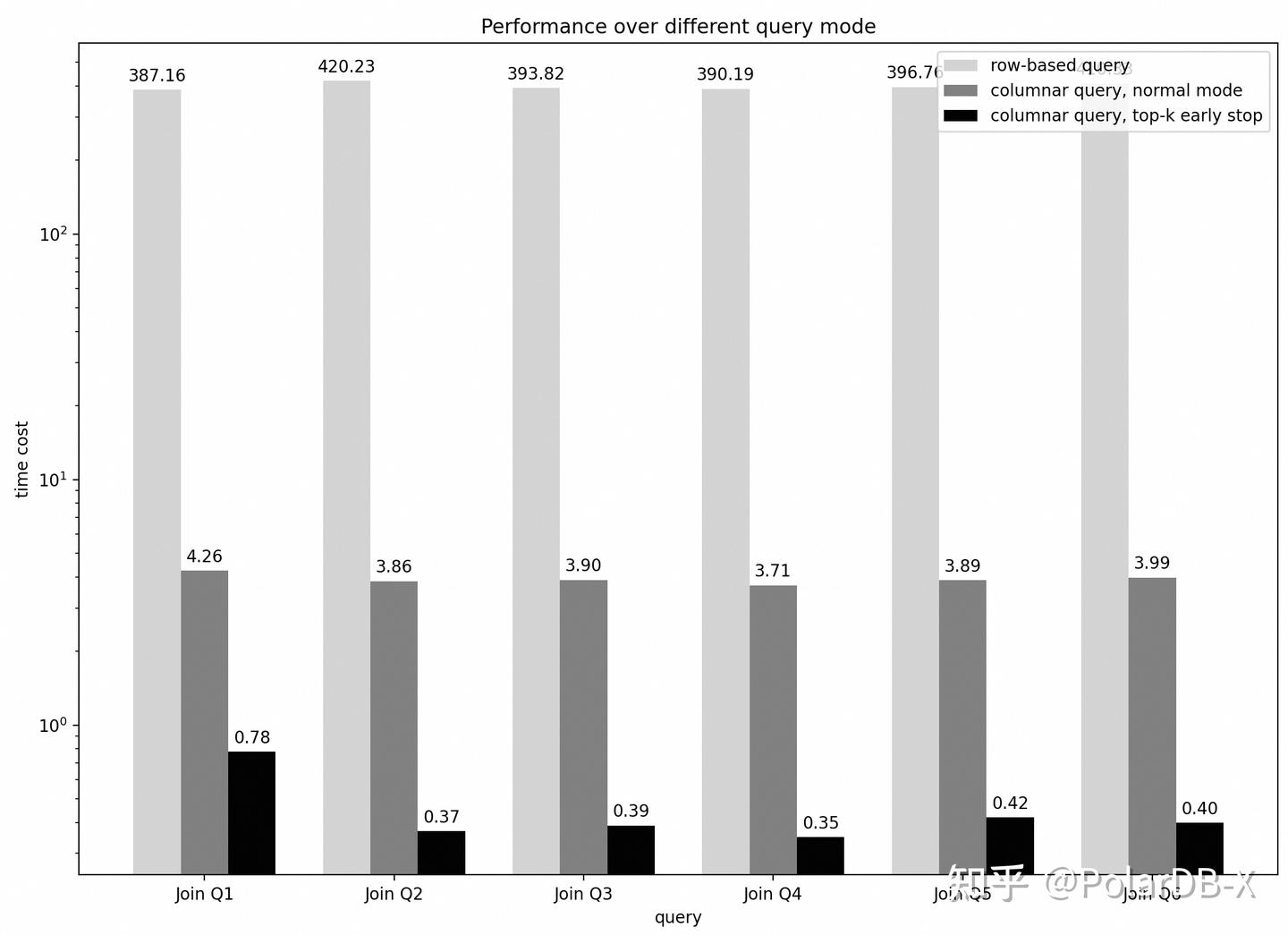
多表连接+分页查询
下图针对6种多表连接查询场景进行测试:
| 编号 | SQL |
| Q1 | select l_shipdate,l_orderkey from lineitem, supplier where lineitem.l_suppkey = supplier.s_suppkey order by l_shipdate limit 20000,10; |
| Q2 | select l_shipdate,l_orderkey from lineitem, supplier where lineitem.l_suppkey = supplier.s_suppkey order by l_shipdate, l_orderkey limit 20000,10; |
| Q3 | select l_shipdate,l_orderkey from lineitem, supplier where lineitem.l_suppkey = supplier.s_suppkey order by l_shipdate, l_orderkey desc limit 20000,10; |
| Q4 | select l_shipdate,l_orderkey from lineitem, supplier where lineitem.l_suppkey = supplier.s_suppkey order by l_shipdate desc limit 20000,10; |
| Q5 | select l_shipdate,l_orderkey from lineitem, supplier where lineitem.l_suppkey = supplier.s_suppkey order by l_shipdate desc, l_orderkey limit 20000,10; |
| Q6 | select l_shipdate,l_orderkey from lineitem, supplier where lineitem.l_suppkey = supplier.s_suppkey order by l_shipdate desc, l_orderkey desc limit 20000,10; |
测试对比结果如下:
总结
PolarDB-X通过一系列设计来提升大规模数据环境下的Top-K查询和分页查询性能。本文介绍的关键点:
- 多层次并行Top-K算子结构
- L1 Top-K算子:部署在每个计算节点上,负责本地数据的初步Top-K筛选,充分利用多核并行能力。
- L2 Top-K算子:汇总同一节点内多个L1算子的结果,减少跨节点的数据传输,优化网络开销。
- L3 Top-K算子:集中汇总所有节点的L2结果,计算全局的Top-K结果,确保最终查询的准确性。
- 多线程协同更新Kth值
- 全局Kth值维护:所有线程共同维护一个全局第K大值(Kth),通过并发安全的机制(如CAS)动态更新,加速Kth值的收敛。
- 提高过滤效率:快速收敛的Kth值能够更有效地过滤掉不符合条件的数据,减少堆的写入操作,提高整体查询效率。
- 上下游算子之间的紧密协作
- Runtime-filter机制:利用动态更新的Kth值作为过滤条件,实时传递给Scan算子,减少扫描数据量。
- 有序数据块处理:L2和L3算子利用上游算子输出数据的有序性,提前丢弃不必要的数据块,进一步优化处理流程。
- Top-K算子内部执行流程
- 堆顶清理:在数据写入前,先清理堆顶元素,确保堆中始终保持最优的K个元素。
- 动态过滤与更新:根据当前Kth值动态过滤输入数据,同时更新堆和Kth值,实现高效的数据处理。
- 提前终止文件读取:基于全局阈值Vk,动态决定是否继续读取某文件的数据,显著减少I/O开销。
- 基于阈值的提前终止文件调度策略
- 正序与逆序扫描:根据排序列与文件存储顺序的关系,决定扫描的方向和终止条件,实现高效的数据筛选。
- 交错文件读取策略:避免集中处理单个文件,通过轮询方式反复读取多个文件的IO单位,提升数据处理的均衡性和效率。
这些设计使得PolarDB-X在处理复杂查询和大规模数据集时,能够高效、低延迟地返回Top-K结果,满足性能需求。
