




前言
前段时间发了一篇文章介绍了如何利用AI优化SQL,并提供了一个思路利用AI实现SQL自动优化,本文介绍一下如何实现的,只需10块钱!
https://www.modb.pro/db/1892402473294376960
一.如何调用deepseek
1.打开deepseek官网首页,点击右上角的API开放平台

2.充值,首次充值会要求实名,我这里只是测试所以就冲了10元
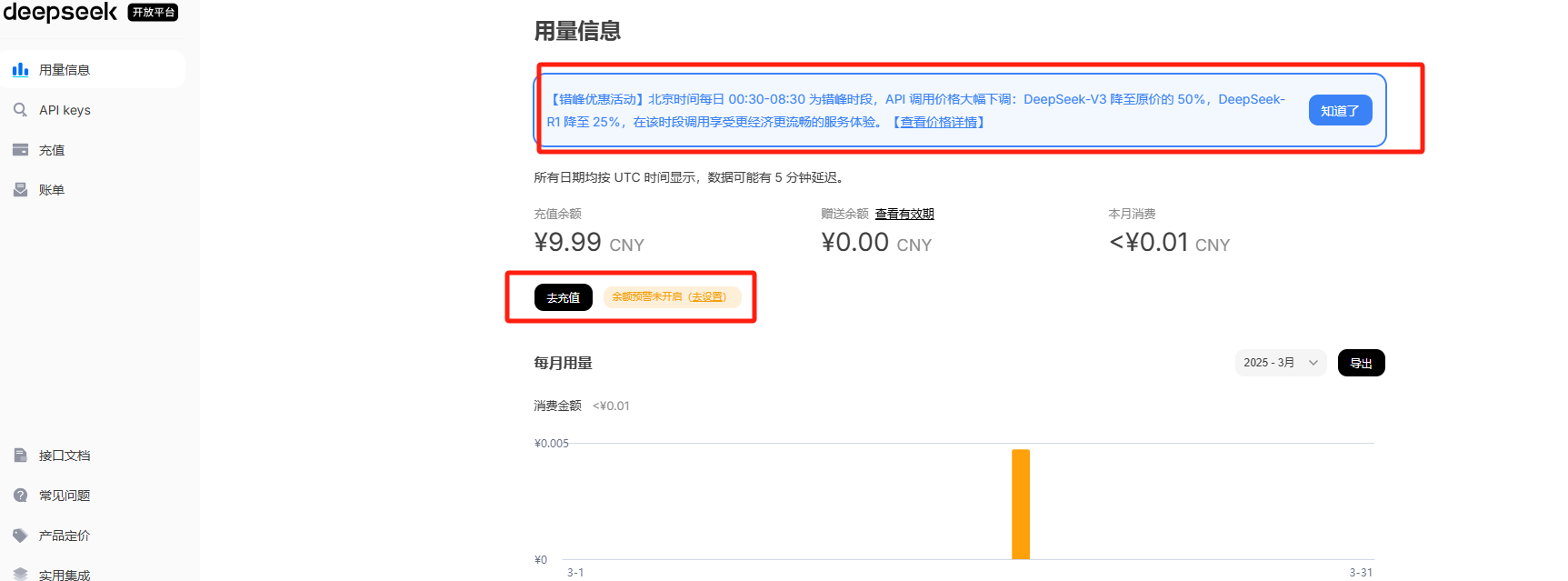
价格信息参考如下,基本上百万tokens输出在8块钱,还是很便宜的。
3.创建API key,创建好记得记录下API key
4.首次调用 看一下接口文档
接口文档代码可以copy使用
二.测试API 调用
主机是Centos 7.9 ,python3.13,pip 25.0.1
[oracle@orcoem01 ~]$ python3 --version
Python 3.13.0
[oracle@orcoem01 ~]$ pip --version
pip 25.0.1 from /home/oracle/.local/lib/python3.13/site-packages/pip (python 3.13)
1.安装依赖requests
pip install requests2.开通网络端口
主机需要开通网络api.deepseek.com 443
ping api.deepseek.com
PING api.deepseek.com (116.205.40.120) 56(84) bytes of data.
64 bytes from ecs-116-205-40-120.compute.hwclouds-dns.com (116.205.40.120): icmp_seq=1 ttl=49 time=33.2 ms
64 bytes from ecs-116-205-40-120.compute.hwclouds-dns.com (116.205.40.120): icmp_seq=2 ttl=49 time=33.1 ms
64 bytes from ecs-116-205-40-120.compute.hwclouds-dns.com (116.205.40.120): icmp_seq=3 ttl=49 time=33.0 ms3.测试python调用
python代码如下,替换为自己的API key
import requests
API_URL = "https://api.deepseek.com/chat/completions"
API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxx"
def ask_deepseek(prompt):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
"stream": False
}
response = requests.post(API_URL, json=data, headers=headers)
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
else:
return f"Error: {response.text}"
# API
response = ask_deepseek("Hello!")
print("DeepSeek AI Response:", response)我这里测试一个最简单的hello,看到如下返回,就表明我们在Linux上调用deepseek API 成功了。
[root@orcoem01 ~]# python3 test.py
DeepSeek AI Response: Hello! How can I assist you today? 😊三.利用Python脚本调用官方API,处理数据库问题
我的思路是利用python脚本,抓取oracle信息(比如异常sql,比如报错,比如异常等待等) 将需要分析的信息抛给deepseek,并将返回的信息邮件发送给相关人员,比如数据库层的发送给DBA,sql优化层的发送给开发人员;
首先安装python依赖包
oracle 12+以上的版本使用 python oracledb
oracle 11.2之前的版本使用 cx_Oracle
##windows如下直接拉取pip install oracledb requests smtplib email cx_Oracle
##Linux 使用如下 oracle 12+以上的版本使用oracledb[root@orcoem01 pip]# python3 -m pip install oracledb Collecting oracledb Using cached oracledb-3.0.0-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_28_x86_64.whl.metadata (5.5 kB) Collecting cryptography>=3.2.1 (from oracledb) Downloading cryptography-44.0.2-cp39-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (5.7 kB) Collecting cffi>=1.12 (from cryptography>=3.2.1->oracledb) Downloading cffi-1.17.1-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting pycparser (from cffi>=1.12->cryptography>=3.2.1->oracledb) Downloading pycparser-2.22-py3-none-any.whl.metadata (943 bytes) Downloading oracledb-3.0.0-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_28_x86_64.whl (2.7 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.7/2.7 MB 996.8 kB/s eta 0:00:00 Downloading cryptography-44.0.2-cp39-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.2 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.2/4.2 MB 5.0 MB/s eta 0:00:00 Downloading cffi-1.17.1-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (479 kB) Downloading pycparser-2.22-py3-none-any.whl (117 kB) Installing collected packages: pycparser, cffi, cryptography, oracledb Successfully installed cffi-1.17.1 cryptography-44.0.2 oracledb-3.0.0 pycparser-2.22##oracle 11.2之前的版本使用cx_Oracle[root@szsplorcoem01 ~]# python3 -m pip install cx_Oracle Collecting cx_Oracle Downloading cx_Oracle-8.3.0.tar.gz (363 kB) Installing build dependencies ... done Getting requirements to build wheel ... done Preparing metadata (pyproject.toml) ... done Building wheels for collected packages: cx_Oracle Building wheel for cx_Oracle (pyproject.toml) ... done Created wheel for cx_Oracle: filename=cx_oracle-8.3.0-cp313-cp313-linux_x86_64.whl size=794487 sha256=60204a2ffb0dc1c2d574d43f00228becf71ea5e6312a7ffa0e77037d9eb6ba72 Stored in directory: /root/.cache/pip/wheels/51/d5/df/61146784a04f4192f24a4ae0d3795d8016e8bea735f768e2e1 Successfully built cx_Oracle Installing collected packages: cx_Oracle Successfully installed cx_Oracle-8.3.0 WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
我这里来实现我上篇文章想的sql自动优化,大概的路径是这样的,因为我一个管理几十套ORACLE集群,没有时间对每个库进行sql优化,那么我就按如下路径来尝试利用AI来做自动优化

https://www.modb.pro/db/1892402473294376960
Python脚本如下
import oracledb
import requests
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# Oracle 数据库配置
DB_CONFIG = {
"host": "10.xxx.xxx.xx",
"port": 1521,
"service_name": "orcl",
"user": "norton",
"password": "norton"
}
# DeepSeek API 配置
API_URL = "https://api.deepseek.com/chat/completions"
API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxx" # 请替换为你的 API Key
# 邮件服务器配置
SMTP_SERVER = "10.xx.xx.xx"
SMTP_PORT = 25
SMTP_SENDER = "test@163.com"
EMAIL_RECEIVER = "xiaofan23z@163.com"
def get_sql_monitor():
"""连接 Oracle 并查询 SQL Monitor 信息"""
try:
# 建立 Oracle 连接
conn = oracledb.connect(
user=DB_CONFIG["user"],
password=DB_CONFIG["password"],
dsn=f"{DB_CONFIG['host']}:{DB_CONFIG['port']}/{DB_CONFIG['service_name']}"
)
cursor = conn.cursor()
# 1. 获取执行时间最长的 SQL ID ,这里的逻辑是抓取最近一天中执行次数超过10 平均执行时间大于10s 中总执行时间最久的一个sqlid,
sql_get_top1 = """
SELECT SQL_ID
FROM (
SELECT
SQL_ID,
COUNT(*) AS EXEC_COUNT,
AVG(ELAPSED_TIME/EXECUTIONS)/1e6 AS AVG_ELAPSED_TIME_SEC,
MAX(ELAPSED_TIME/EXECUTIONS)/1e6 AS MAX_ELAPSED_TIME_SEC,
SQL_TEXT
FROM V$SQL
WHERE
LAST_ACTIVE_TIME > SYSDATE - 1 -- 过去一天
AND EXECUTIONS > 10 -- 执行次数超过10次
AND (ELAPSED_TIME / EXECUTIONS) / 1e6 > 10 -- 平均执行时间超过10秒
GROUP BY SQL_ID, SQL_TEXT
ORDER BY MAX_ELAPSED_TIME_SEC DESC -- 排序,最大执行时间在前
)
WHERE ROWNUM = 1
"""
cursor.execute(sql_get_top1)
sql_id_row = cursor.fetchone()
if not sql_id_row:
return "未找到符合条件的 SQL 语句"
sql_id = sql_id_row[0] # 获取 SQL ID
# 2. 生成 SQL Monitor 报告
sql_monitor_query = f"""
SELECT DBMS_SQLTUNE.report_sql_monitor(
sql_id => '{sql_id}',
type => 'TEXT'
) AS report
FROM dual
"""
cursor.execute(sql_monitor_query)
report = cursor.fetchone()[0] # 获取 SQL Monitor 报告
# 处理 LOB 数据,转换为字符串
if isinstance(report, oracledb.LOB):
report = report.read()
# 关闭连接
cursor.close()
conn.close()
return report
except Exception as e:
return f"Oracle 查询失败: {str(e)}"
def ask_deepseek(sql_report):
"""调用 DeepSeek API 获取 SQL 优化建议"""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一个 Oracle 数据库优化专家,请分析以下SQL执行计划,并给出优化建议。"},
{"role": "user", "content": sql_report}
],
"stream": False
}
response = requests.post(API_URL, json=data, headers=headers)
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
else:
return f"DeepSeek API 请求失败: {response.text}"
def send_email(subject, content):
"""发送邮件"""
try:
msg = MIMEText(content, "plain", "utf-8")
msg["From"] = Header(SMTP_SENDER, "utf-8")
msg["To"] = Header(EMAIL_RECEIVER, "utf-8")
msg["Subject"] = Header(subject, "utf-8")
server = smtplib.SMTP(SMTP_SERVER, SMTP_PORT)
server.sendmail(SMTP_SENDER, [EMAIL_RECEIVER], msg.as_string())
server.quit()
return "邮件发送成功"
except Exception as e:
return f"邮件发送失败: {str(e)}"
if __name__ == "__main__":
# 1. 获取 SQL Monitor 报告
sql_monitor_report = get_sql_monitor()
print("🔹 SQL Monitor 报告获取成功")
# 2. 发送 SQL Monitor 信息到 DeepSeek 获取优化方案
optimization_suggestions = ask_deepseek(sql_monitor_report)
print("🔹 DeepSeek 优化建议获取成功")
# 3. 发送优化方案邮件
email_subject = "SQL 优化建议"
email_content = f"【SQL Monitor 报告】\n{sql_monitor_report}\n\n【优化建议】\n{optimization_suggestions}"
send_status = send_email(email_subject, email_content)
print(send_status)
执行python脚本
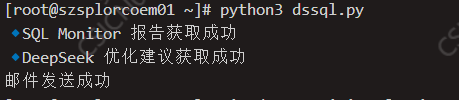
看看效果
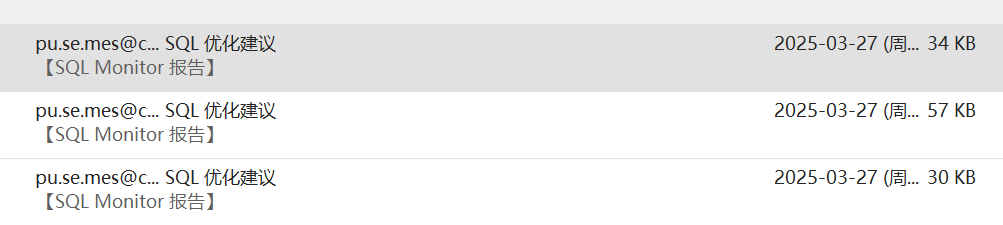
邮件中先列出oracle sql montior的基本信息

因为这是一个存储过程,没有具体sql和执行计划,所以deepseek的优化能力很有限,只是给出了一些通用的建议


总结
这里只是实现了一个非常简单的功能,通用API的能力应付基本的sql优化,日常排错还是没有问题;使用本地化部署的deepseek,即使是加了知识库,可能还是无法与官方满血的deepseek相提并论,不过受限于数据安全问题和网络限制无法访问官方API, 我这里也不是使用的数据库直接调用,而是使用EMCC主机,EMCC主机已经打通了所有被管理数据库的网络和端口,只需要将EMCC加个白名单api.deepseek.com 443即可。
以上的方法大家也可以自己尝试一下,非常方便复刻,也可以根据自己的想法,探索其他的运维场景,欢迎留言转发。
