




1、 词法分析部分:
openGauss采用flex和bison两个工具来完成词法分析和语法分析的主要工作。对于用户的每个输入的SQL语句,flex工具会先把这些语句进行词法分析,然后生成词法分析的代码
这一部分定义的是扩展注释语法,这部分和允许的运算符语法类似,但是这里实现的主要方式是让lex识别以斜杠星作为一个注释,当注释的部分不对劲的时候,就会自动跳出来,把它解释为运算符。现在,只要发现斜杠星这样的东西,lex就可以认为它是一个3字符的操作符,这里把{op_char}追加到xcstart,让它可以匹配尽可能多的{op_char}文本然后通过规则确保xcstart可以完成自己的任务,多余的东西利用yyless()放回去,避免把停止注释的操作符给一并注释掉。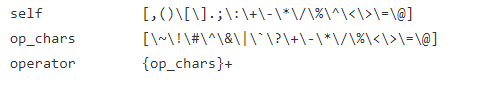
接下来看这里:self是作为单个字符返还的字符集,op_char则是可以组成op标记的字符集,可以是一个或者多个字符长,在下面的operator就是由多个operator完成的。这些集合虽然重叠,但是每个集合都有一些不在另一个集合中的字符,还是有所区别的。
这里是对于解析的补充,将一元负数单独传递给解析器,其中添加了realfail1和realfail2,当real规则无法匹配时,这两个会辅助进行备份操作。这样,数据和各种解析就可以对应匹配,完成各自的任务。


这里,operator的作用是检查是否嵌入斜杠星或者短划线(即注释开始的标志)如果是第一个字符的斜杠星或者短划线,则将要匹配之前的规则,但是不冲突。需要注意,为了SQL兼容考虑,‘+’‘-’不能是多字符操作符的最后一个字符,比如‘=-’,这需要被作为两个操作符考虑。
identifier主要定义的是关键字,在其他地方,定义了很多的关键字,那么在处理标识符的时候,如果一个标识符匹配到关键字,则认为是关键字,否则才是标识符,即关键字优先。随后对识别出的关键字进行分析,最后获得它的具体表达含义,然后完成其相关功能,当然,这部分就不是词法分析部分的事情了。这些就是我认为最主要的词法分析的结构
接下来就是扫描错误,当出现错误词法或者错误语法的时候,这里会有显示。消息的光标位置是YYLLOC上次设置的位置,如果在yylex()内调用,就是挡墙标记的开始,语法调用就是最新的词法化标记。Bison解析器传来的语法错误消息这里是可以进行处理和报告的,因为只要bison碰到解析不出来的东西,就直接报告了。这里的目的就是为了识别和显示。
这些只是词法分析中的一部分,毕竟太多了,不过值得一提的是,opengauss定义了大量的关键字,按照字母的顺序进行排列,这样做的目的是方便查找关键字的时候通过二分法进行查找。定义大量关键字的好处就是,到时候编写代码的时可以直接用,更加便捷,而不是慢慢的一点一点的自己想如何实现该功能。在处理标识符的时候,回到关键字列表中进行匹配,如果标识符匹配到关键字,就会跳过标识符的认定直接进行下一步,关键字优先的原则在这里,不是关键字的话,才会认定其为标识符,这样做提高了效率。
2、 语法分析部分:
首先先需要确定,在没有AS的情况下支持target_el,必须在POSTFIXOP和OP之间给ident一个明确的优先级,通过优先级分配不同的关键字,避免出现奇异的问题,或者是出现了一些较小的歧义的时候可以自行找到。对于关键字而已,需要对分区、范围、行去执行操作,去支持现有的窗口以及名称。同样,在区别运算符与关键字等东西的时候也需要用到优先级,这里就有所显示了。
这些可能看起来优先级比较低,但是实际上并不是同一部分。在算数层次结构中,它们被用作连接运算符,它们是高优先级,用作为函数名。联接规则本身之间的左关联性也体现了这一点。


在openGauss语法分析中,根据SQL语言的不同定义了一系列表达Statement的结构体(这些结构体通常以Stmt作为命名后缀),用来保存语法分析结果。以select为例在语法分析的代码中,对于select命令,定义了一个结构体,并且给他创造了节点,这个结构体可以看成是一个多叉树,每一个叶子节点都对应了一个select命令的功能,通关这种方式,select命令的功能被逐一拆分出来,最后通过简单基本的SQL命令,去一个个实现其功能,最后再把所有的汇聚到一起,成为一个完整的select命令。

首先看simple_select,这个规则分析可以出现在集合操作中的(包括UNION、INTERSECT和EXCEPT)中的SELECT语句。可用于指定集合操作的顺序。如果没有和,那么就按照此文件开头的优先规范进行排序,排序字句的级别不完全相同。从simple_select语法分析结构可以看出,一条简单的查询语句由以下子句组成:去除行重复的distinctClause、目标属性targetList、SELECT INTO子句intoClause、FROM子句fromClause、WHERE子句whereClause、GROUP BY子句groupClause、HAVING子句havingClause、窗口子句windowClause和plan_hint子句。到这里,结构体创造完成。这里的主要目的就是为关键字select创建一个多叉树,把他的各种功能拆掉,拆成简单的功能分别实现,这样做可以减少一个函数的函数量,从而减少bug的出现。
接下来又创建了一个对应目标的表达式target_list,由多个target_el组成。

不难看出target_el的功能有很多,ident负责通过指定优先级,去实现表达式的解析以及作为表达式,取别名的表达式和“*”等,对应target_list部分进行定义。并且完成该部分的功能。而在成功匹配到功能的时候,在以已经编好的程序下,系统会产生一个名为ResTarget的结构体,该结构体的作用是储存目标对象的信息,比如名称,目标属性,各种表达式以及符号出现的位置。这就是select的目标列表

实际上from对于信息的处理方法与target_el类似,也是通过from_list和from_clause之间的关系来实现的,右侧便是from_list的功能集合,记录的东西要比target更多,table_ref可以定义为关系表达式、取别名的关系表达式、函数、SELECT语句、表连接等形式。通过结构体中定义好的节点,去完成连接等功能。
尽管功能更多,但是在处理方式上还是一致的,最终from还是会生成一个结构体,该结构体会包含表的数据库名,表的模式名,表或者序列名,记录分区表名,是否将表的操作递归到子表上,表的类型,表的别名,符号出现的位置,是否为分区表,当前是否为哈希桶类型的表,以及对应的哈希桶中的桶等相关信息。通过这些信息以及判断,最后完成from字句的功能
所有可优化的stmt通用的字句,from字句表达的东西是允许联接表达式和表名的列表。而where字句,则表示加入或限制条款。
With字句,通过使用递归<query name>[(<column>,…)]。查询或者搜索或者循环字句。到目前为止,不支持search或者cycle字句的使用,还需要特别注意。
此处需要冗余,去避免轮班/减少冲突,因为temo不是保留字。
WHERE子句给出了元组的约束信息,对应语法定义中的where_clause,与select_into类似,由WHERE关键字和一个表达式组成,对于运算关系,会调用makeSimpleA_Expr函数生成A_Expr结构体,存储表达式的相关信息。A_Expr结构如下,字段lexpr和rexpr分别保存左、右两个子表达式的相关信息。存储表达式名称,操作符名称,左子表达式,右子表达式以及符号出现的位置。
以select为例拆完了大部分功能以后,不难看出基本上语法分析都是这样的思路,先拆后实现,不仅仅是select关键字,如CREATE、INSERT、UPDATE、DELETE等其他关键字处理方式也是类似的。在完成词法分析和语法分析后,raw_parser函数会将所有的语法分析树封装为一个List结构,名为raw_parse_tree_list,返回给exec_simple_query函数,用于后面的语义分析、查询重写等步骤,该List中的每个ListCell包含一个语法树。
