




相比MySQL社区版,PolarDB-X DN有较大改动,它不支持原生xtrbackup备份工具,所以不借助DTS工具时,就只能用mysqldump逻辑迁移。 在阿里专家的协助下,我们通过全量迁移(mysqldump、load) + 增量迁移(主从复制)的方式完成了迁移,本文记录了详细迁移步骤和迁移遇到的一些问题。
迁移过程有GTID和偏移位点两种模式。如果源库没有GTID,就选用传统偏移位点模式;如果源库有GTID,两种模式都可以选择。
一、基于GTID模式的迁移
源库:mysql8 社区版 10.0.0.101
目标库:polardbx标准版 10.0.0.102
1.1 全量数据迁移
使⽤mysqldump⼯具导出源库需要迁移的库,⽐如迁移db1和db2。
# 源库全量导出
mysqldump -h 127.0.0.1 -uroot -p --source-data=2 --single-transaction --routines --events --max_allowed_packet=32M --set-gtid-purged=OFF -B db1 db2 > /cloud_backup/dump/db.sql
注意:
- 执行mysqldump时要指定–set-gtid-purged=ON,即记录gtid到dump⽂件中(后面增量同步需要);
- polardbx不⽀持系统库系统表的全量迁移,所以不要导出mysql、performance_schema等系统库。
1.2 修改dump文件
修改上面mysqldump导出的⽂件,开启binlog。⽐如
sed -i '/SET @@SESSION\.SQL_LOG_BIN/ s/^/-- /' db.sql
注意:
其⽬的是让导⼊的全量数据(db.sql)在⽬标端polardbx的leader节点应用时可以⽣成binlog, 然后能同步给其他follower节点。如果缺少这⼀步,最终导⼊的数据只有leader上有,follower没有。
1.3 导⼊全量数据
导⼊数据前,要求⽬标polardbx的 select @@gtid_executed 与源MySQL库的 select @@
gtid_executed 没有任何重叠。
/u01/xcluster80/bin/mysql -S /data/polardbx-engine/tmp/mysql.sock < /tmp/db.sql
注意:
- 如果⽬标PolarDB-X DN的 select @@gtid_executed 与源MySQL库的 select @@gtid_e
xecuted有重叠,需要使⽤新的server_id重建⽬标PolarDB-X DN集群;- 导⼊完成后,在leader节点查看延迟监控视图,确保polardbx集群副本之间同步正常、无延迟。语句:select * from information_schema.ALISQL_CLUSTER_HEALTH;
1.4 导⼊增量数据
在源库与目标库之间配置异步复制。主库为mysql社区版,从库是⽬标polardbx的leader节点。
源端(mysql社区版)执行,即dump导出数据节点
#1. 主库上创建主从复制使⽤的账户
CREATE USER 'repl'@'%' IDENTIFIED by '123456';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
目标端执行,即polardbx leader节点
#2. 在从库配置复制链路sync_test, source_host、source_port为主库的host和port,source_user和source_password是第一步在主库创建的账号
change replication source to
source_host = '10.0.0.101',
source_port = 3306,
source_user = 'rep',
source_password = '123456',
source_auto_position=1 for channel 'sync_test';
#3. 从库启动主从复制线程,即在polardbx的leader节点上执行
start replica for channel 'sync_test';
#查看该链路的线程状态,确保Slave_IO_Running、Slave_SQL_Running都是Yes
show replica status for channel 'sync_test'\G
注意:
- PolarDB-X DN的主从复制功能从20250101版本开始⽀持;
- 增量数据期间,从库PolarDB-X DN集群不能切主。切主后,需要重新再新leader上配置复
制链路;- 增量数据同步过程中,实时观察leader的延迟监控,确保没有应⽤中断。select * from
information_schema.ALISQL_CLUSTER_HEALTH;
1.5 目标端 follower节点执行dump文本中的purge语句
在polardbx的所有follower节点执行dump文本中的purge命令。
截图为dump文件db.sql
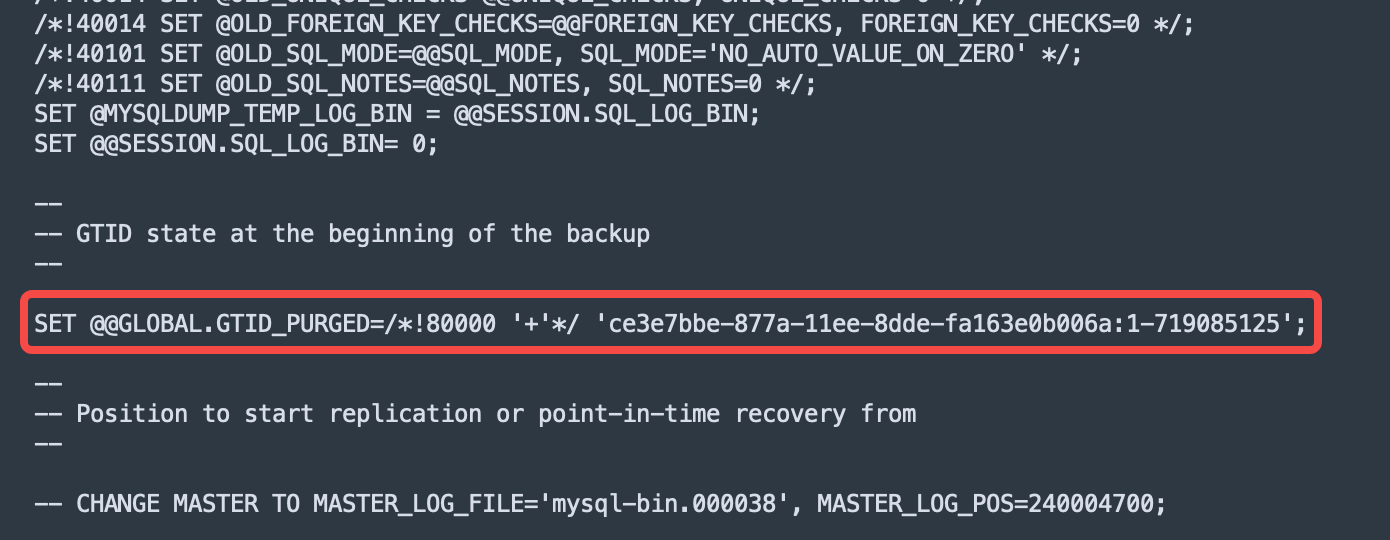
--在polardbx DN的所有follwer节点手工执行这条命令
SET GLOBAL GTID_PURGED='ce3e7bbe-877a-11ee-8dde-fa163e0b006a:1-719085125';
--对比polardbx dn所有副本,保证gtid purge集合一致
show variables like 'gtid%';
注意:
在leader节点导入dump文件(db.sql)时,会自动执行文本中的SET @@GLOBAL.GTID_PURGED=/!80000 ‘+’/ ‘ce3e7bbe-877a-11ee-8dde-fa163e0b006a:1-719085125’;命令,但是该语句不会写binlog,即不会同步到follower节点。所以执行命令,可以避免目标端切主重新配置复制线程后,purge gtid集不一致引发的gtid找不到等问题。
1.6 迁移过程中遇到报错
错误1: 增量同步过程中出现下面错误
--复制线程报错,show replica status\G;
Last_SQL_Error: Error executing row event: '@@SESSION.GTID_NEXT cannot be set to ANONYMOUS when @@GLOBAL.GTID_MODE = ON.'
解决方法
--1、先尝试重启复制线程
stop replica for channel 'sync_test';
start replica for channel 'sync_test';
--2、重启无效后执行下面语句解决
stop replica for channel 'sync_test';
change replication source to master_auto_position=1 for channel 'sync_test';
start replica for channel 'sync_test';
show replica status\G;
错误2
--复制线程报错,show replica status\G;
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Cannot replicate because the source purged required binary logs. Replicate the missing transactions from elsewhere, or provision a new replica from backup. Consider increasing the source's binary log expiration period. The GTID set sent by the replica is 'ce3e7bbe-877a-11ee-8dde-fa163e0b006a:700200748:711689463-715394855,f3fadd6b-0960-11f0-b439-fa163ead407a:1-229615', and the missing transactions are 'ce3e7bbe-877a-11ee-8dde-fa163e0b006a:1-70020078'.
解决方法
#查看源库,发现这部分gtid已经purge掉了。
root@localhost: 11:06: [(none)]> show variables like 'gtid%';
+----------------------------------+--------------------------------------------------+
| Variable_name | Value |
+----------------------------------+--------------------------------------------------+
| gtid_executed | ce3e7bbe-877a-11ee-8dde-fa163e0b006a:1-718895586 |
| gtid_executed_compression_period | 0 |
| gtid_mode | ON |
| gtid_next | AUTOMATIC |
| gtid_owned | |
| gtid_purged | ce3e7bbe-877a-11ee-8dde-fa163e0b006a:1-700200748 |
+----------------------------------+--------------------------------------------------+
6 rows in set (0.00 sec)
#解决方法:对比源库gitd purge,清理掉目标库gtid_executed前gtid集,这样复制线程就不会再去找这段gtid了。
#目标库查看
mysql> show variables like 'gtid%';
+----------------------------------+---------------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+----------------------------------+---------------------------------------------------------------------------------------------------------------------+
| gtid_executed | ce3e7bbe-877a-11ee-8dde-fa163e0b006a:711689463-715394855 |
| gtid_executed_compression_period | 0 |
| gtid_mode | ON |
| gtid_next | AUTOMATIC |
| gtid_owned | |
| gtid_purged | ce3e7bbe-877a-11ee-8dde-fa163e0b006a:1-700200747 |
+----------------------------------+---------------------------------------------------------------------------------------------------------------------+
6 rows in set (0.01 sec)
--目标库执行
SET GLOBAL gtid_purged = 'ce3e7bbe-877a-11ee-8dde-fa163e0b006a:1-711689462';
--然后重启复制线程
stop replica for channel 'sync_test';
start replica for channel 'sync_test';
二、基于偏移位点模式的迁移
源库:mysql8 社区版 10.0.0.101
目标库:polardbx标准版 10.0.0.102
2.1 全量数据迁移
# 源库全量导出
mysqldump -h 127.0.0.1 -uroot -p --source-data=2 --single-transaction --routines --events --max_allowed_packet=32M --set-gtid-purged=OFF -B db1 db2 > /cloud_backup/dump/db.sql
注意:
执行mysqldump时要指定–set-gtid-purged=OFF,即dump⽂件不记录GTID。其他同上。
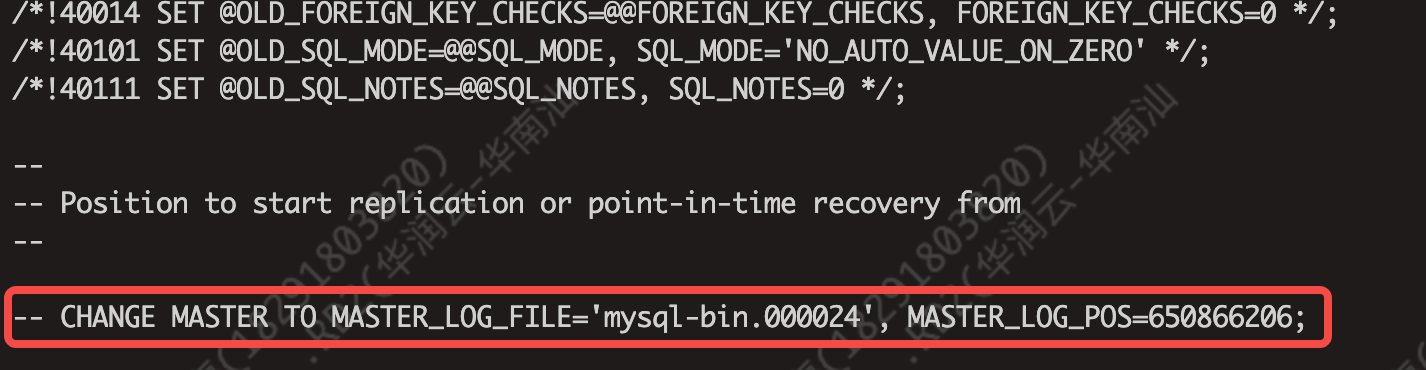
如下截图,db.sql中不会记录gtid,只记录master_log_file和master_log_pos。
2.2 导⼊全量数据
/u01/xcluster80/bin/mysql -S /data/polardbx-engine/tmp/mysql.sock < /tmp/db.sql
注意:
导⼊完成后,在leader节点查看延迟监控视图,确保polardbx集群副本之间同步正常、无延迟。语句:select * from information_schema.ALISQL_CLUSTER_HEALTH;
2.3 导⼊增量数据
在源库与目标库之间配置异步复制。主库为mysql社区版,从库是⽬标polardbx的leader节点。
源端(mysql社区版)执行,即dump导出数据节点
#1. 主库上创建主从复制使⽤的账户
CREATE USER 'repl'@'%' IDENTIFIED by '123456';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
从dump文件(db.sql)中获取偏移位点
#2 获取dump文件中的偏移位点:MASTER_LOG_FILE='mysql-bin.000024', MASTER_LOG_POS=650866206;
-- MySQL dump 10.13 Distrib 8.0.33, for Linux (aarch64)
--
-- Host: localhost Database: djms_youth
-- ------------------------------------------------------
-- Server version 8.0.33
--
-- Position to start replication or point-in-time recovery from
--
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000024', MASTER_LOG_POS=650866206;
......
目标端执行,即polardbx leader节点
#3. 在从库配置复制链路sync_test, source_host、source_port为主库的host和port,source_user和source_password是第1步在主库创建的账号
change replication source to
source_host = '10.0.0.101',
source_port = 3306,
source_user = 'rep',
source_password = '123456',
source_log_file='mysql-bin.000024',
source_log_pos=650866206 for channel 'sync_test';
#4. 从库启动主从复制线程,即在polardbx的leader节点上执行
start replica for channel 'sync_test';
#查看该链路的线程状态,确保Slave_IO_Running、Slave_SQL_Running都是Yes
show replica status for channel 'sync_test'\G
注意:
增量数据同步过程中,实时观察leader的延迟监控,确保没有应⽤中断。select * from
information_schema.ALISQL_CLUSTER_HEALTH;
三、应用切流
切流环节⽐较关键,需要确保业务端停写,然后切换写到新的⽬标端。为了保证整体原⼦性,可以采⽤如下流程。
3.1 源库(mysql)
#1. 业务主动停写
#2. MySQL禁写
SET GLOBAL read_only = ON;
SET GLOBAL super_read_only = ON;
#3. 检查主库当前@@gtid_executed
select @@gtid_executed;
3.2 检查目标库(polardbx)
#4.检查从库当前@@gtid_executed,确保完全包含主库MySQL的@@gtid_executed
select @@gtid_executed;
#5. 业务切流到从库PolarDB-X DN上
3.3 源库下线(mysql)
#源库下线,测试业务所有数据源,保证都连到polardb上。
SQL> shutdown;
3.4 清理复制信息
全量+增量数据追完后,业务切流到新的PolarDB-X DN集群后,需要清理PolarDB-X DN集群的主从复
制链路
stop slave for channel 'sync_test';
reset slave all for channel 'sync_test';
四、迁移过程中可能用到的运维命令
4.1 polardbx切换leader节点
#在leader节点执行,指定新leader的ip
call dbms_consensus.change_leader("10.133.175.217:14886");
4.2 跳过一个冲突事务
stop replica for channel 'sync_test';
SET GTID_NEXT='ce3e7bbe-877a-11ee-8dde-fa163e0b006a:714392444'; #冲突GTID
BEGIN;COMMIT;
SET SESSION GTID_NEXT = AUTOMATIC;
start replica for channel 'sync_test';
4.3 清理指定的复制链路信息
#停止指定的通道并清理复制关系
stop replica for channel 'sync_test';
reset replica all for channel 'sync_test';
4.4 增量复制过程中,调整参数加速日志应用
--临时调整
set global binlog_row_image=MINIMAL;
set global innodb_flush_log_at_trx_commit = 0;
set global sync_binlog = 10000;
set global weak_consensus_mode=1;
--导入完成后复位
set global binlog_row_image=FULL;
set global innodb_flush_log_at_trx_commit = 1;
set global sync_binlog = 1;
set global weak_consensus_mode=0;
