




在 CAMEL-AI.org,我们始终致力于推动多智能体系统(Multi-Agent Systems)的发展,探索 AI 的边界。在CAMEL- AI社区两周年之际,本篇博客将重申我们的使命,讨论当前 AI 智能体面临的限制与趋势,并介绍我们为 AI 构建“数据驱动”环境的最新方向。
🎯 我们的使命:探索智能体的 Scaling Laws
Key Dimensions
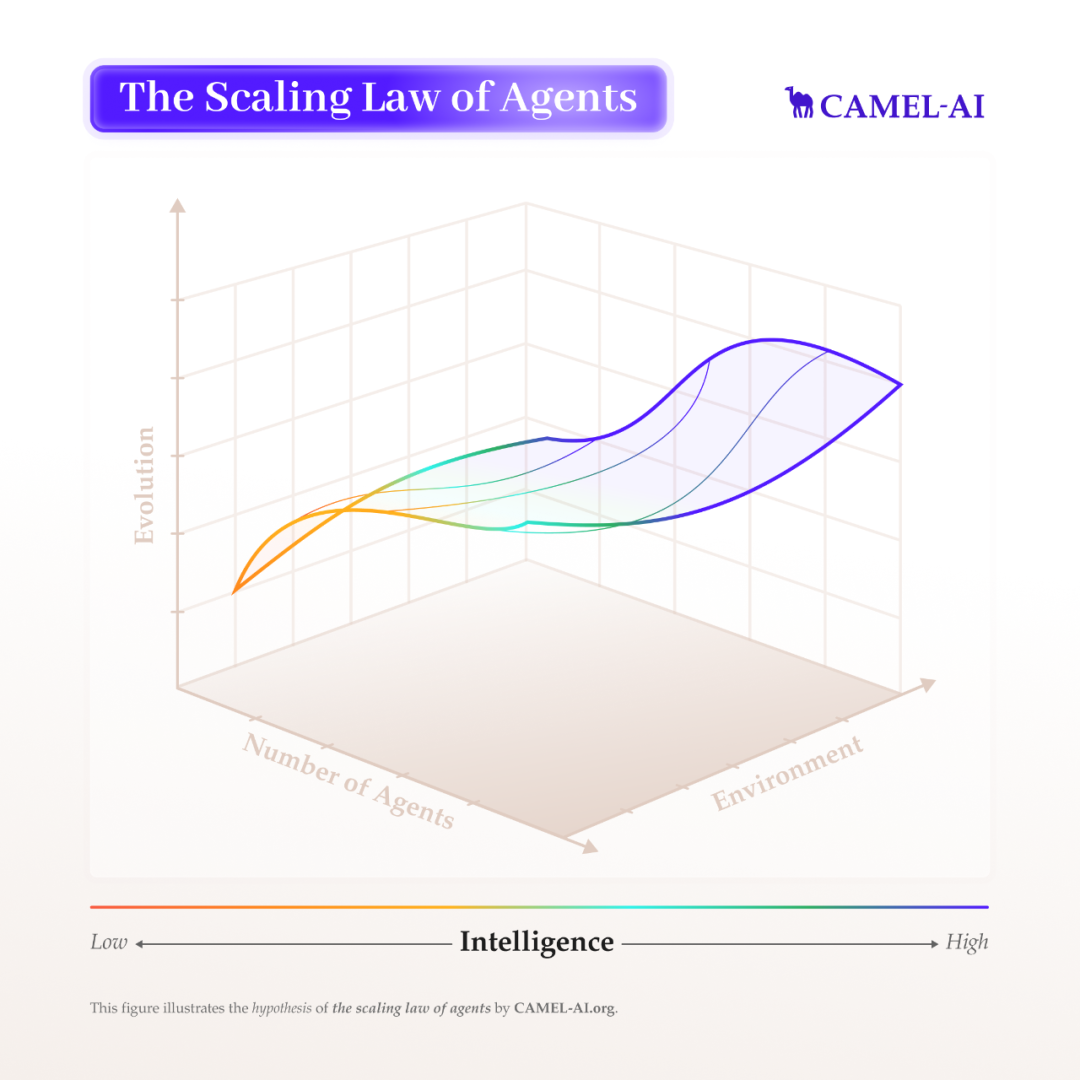
📈 智能体 Scaling 的三个关键维度:
智能体数量:当智能体系统规模扩大时,它们会出现怎样的群体行为和涌现能力?我们致力于研究这些互动中产生的新能力与规律。
环境设计:我们如何构建能够促使智能体学习复杂推理、长期决策和适应性行为的环境?目标是创建贴近真实世界复杂性的交互式环境,为智能体提供有意义的奖励信号,引导其不断进化。
智能体进化:我们正搭建强化学习环境与记忆系统,让智能体能够在任务中泛化、适应新挑战,并通过经验不断进化。
我们认为环境本身就是智能体最缺乏的“数据”。仅靠网络抓取的数据并不足以训练真正适应世界的智能体。智能体需要的,是一个可以不断交互、反馈、试错的“动态空间”。
Prompt Engineering to RL
🤖 从 Prompt Engineering 走向 End-to-End 强化学习
最初,构建 LLM 智能体的方法主要依赖于Prompt Engineering(提示词工程),包括:
角色扮演提示:让模型以某种身份执行任务;
Few-Shot 示例:用多个示例引导模型推理;
输出格式控制:用技巧让模型输出结构化结果(如 JSON)。
这些方法虽然能快速做出原型,但存在很多局限:当任务复杂或场景突变时,智能体往往容易出错,缺乏鲁棒性和灵活性;对提示词的依赖,也让模型容易产生偏差或“幻觉”;而且制作高质量提示词本身就需要大量的人工试错,难以规模化。
因此,整个领域开始转向一个更具潜力的方向:基于端到端强化学习(End-to-End RL)的智能体训练方法。
Raise of RL Agent
🚀 RL 智能体的崛起
越来越多研究机构和初创公司投入到 RL 智能体的研发中,下面是一些代表性的项目:
OpenAI Operator:结合 GPT-4o 的视觉能力,通过强化学习实现与 GUI 的交互,比如下单、订餐、制作 meme 等任务。
OpenAI Deep Research:强化学习训练智能体完成跨网页的复杂浏览与多步骤推理任务。
xAI Grok 3:利用十倍算力进行强化学习训练,具备强大的 Chain-of-Thought 推理能力,能纠错、思考更久、给出更准确答案。
DeepSeek R1:一开始完全靠 RL 训练出的 R1-Zero 展现了复杂推理能力,后续版本通过混合强化学习与小样本监督微调,提升了输出连贯性与实用性。
此外,像 Cursor 这样的垂直智能体初创团队,也开始将 RL 应用于真实开发环境中,例如用 RL 模型提升 AI 编程助手的能力。
Environment is the Key
🌍 环境是智能体训练中最关键却最缺失的“数据”
虽然语言模型在许多任务中已经达到了人类水平,但要实现超越人类的通用智能(AGI),强化学习仍是最值得期待的路径。
正如 AlphaGo 战胜李世石的那一刻那样,未来我们也可能见证更多 “Lee Sedol 时刻” 在 LLM 智能体领域的到来。但目前,RL 的潜力还远未被完全释放,其中最核心的障碍就是——环境的缺失。
网页和文本数据虽然丰富,却无法提供长期交互、时序反馈与复杂因果链条。要让智能体真正理解世界并形成决策能力,它们必须在真实、动态且结构化的环境中学习和试错。
而设计奖励函数(Reward Function)同样是挑战之一。我们正在构建高质量的“验证器(Verifier)”,用于评估智能体输出,帮助形成更加稳定、可靠、与目标对齐的奖励机制。
For Community
🛠 CAMEL 的开源基础设施:为社区协作而生
为了解决这些难题,CAMEL-AI.org 推出了开源框架,聚焦社区驱动的研发模式。我们已经搭建了包括以下模块在内的初始基础设施:
多种环境模块
输出验证器
数据生成管线
智能体工具集
我们希望未来能打造面向各领域的专属环境,包括合成数据生成、任务自动化、虚拟世界模拟等。同时,我们也欢迎社区开发者贡献新的环境类型,共同完善我们的 RL 生态。
如果你对构建智能体环境感兴趣,欢迎填写这个表单: https://www.camel-ai.org/collaboration-questionnaire,一起来探索 RL 智能体的无限可能!
CAMEL 微信号




