





RAGFlow 是一款基于深度文档理解的开源检索增强生成(Retrieval-Augmented Generation,RAG)引擎。旨在通过深度文档理解技术,解决现有 RAG 技术在数据处理和生成答案方面的挑战。
RAGFlow 具有如下功能特点:
● 深度文档理解。
● 可控可解释的文本切片。
● 可视化文本处理过程。
● 兼容多种异构数据。
● 自动化边界的 RAG 工作流。
● 支持多种 LLMs 和向量模型。

步骤一:获取 API 密钥和域名

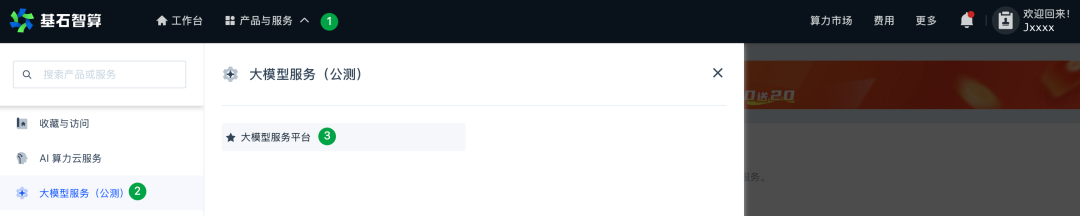
● 若平台内无可用的 API 密钥,用户可参考http://docs.coreshub.cn/console/big_model_server/api_key/create_api_key 创建和获取新的 API 密钥。
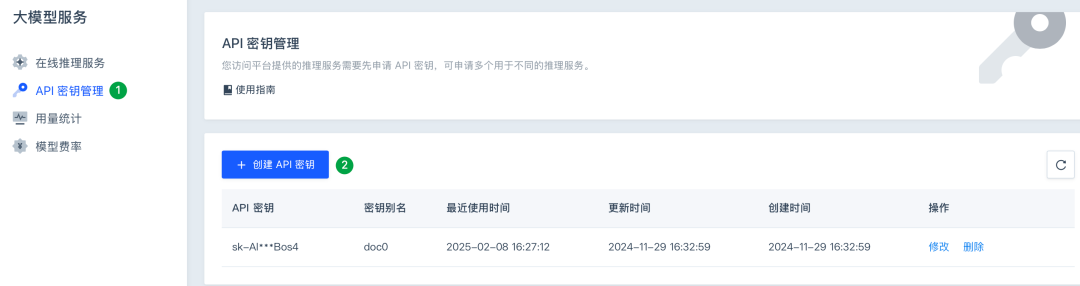
● 若平台内已有可用的 API 密钥,用户可直接将鼠标悬停在指定密钥上,点击 API 密钥右侧的复制按钮,即可获取完整的 API 密钥。
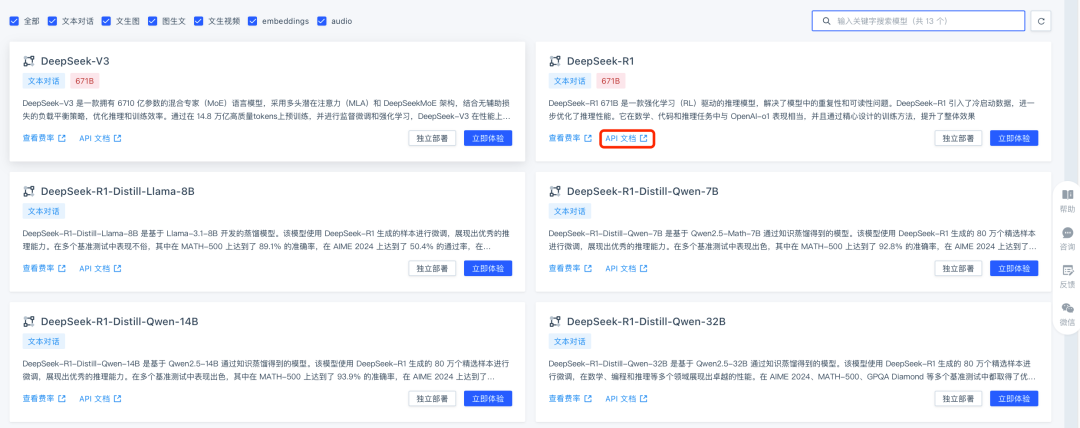
步骤二:配置模型服务

● 每次只能添加一种模型类型,即 chat 和 embedding 模型不能同时添加。
● 如需添加不同类型模型,可完成一种模型的添加后,选中相应的模型供应商后,点击添加模型,进行再一次的添加。
● 模型类型:根据待添加的模型,选择相应的类型。若添加 DeepSeek-R1 模型则选择 chat,若添加基石智算平台上的 bce-embedding-base_v1 模型则选择 embedding。
● 模型名称:填写待添加模型的名称即可,若需使用平台内其他模型,用户仅需在智算平台的在线推理服务页面,复制得到相应模型名称即可。
● 基础 url:直接填写 https://openapi.coreshub.cn/v1 即可。
● API-Key:用户在获取 API 密钥中复制得到的完整 API 密钥,需根据实际情况进行修改。
● 最大 token 数:根据所选择模型支持的最大数量填写。
● 其他参数,根据实际情况设置或保持默认即可。
步骤三:创建知识库
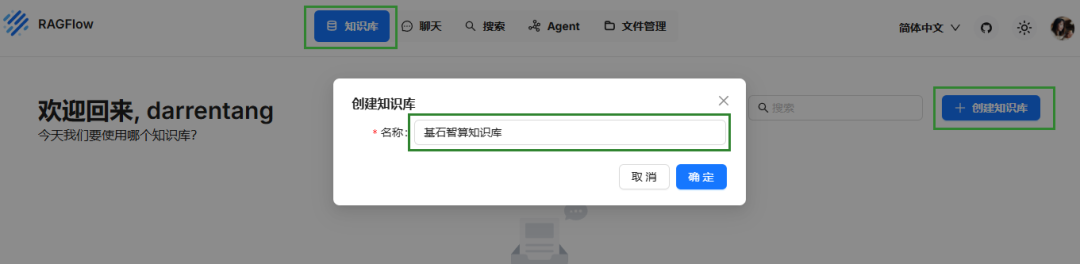
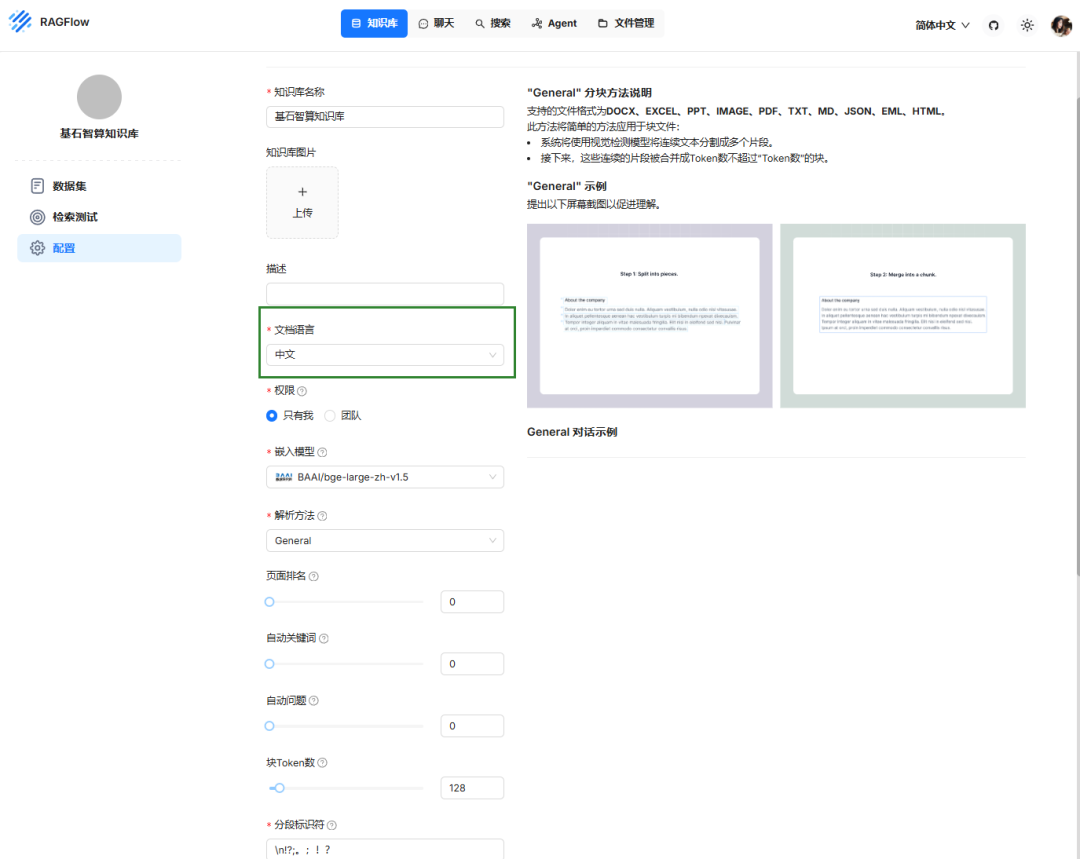
● 知识库名称:用户自定义。
● 文档语言:本实践中选择中文。
● 嵌入模型:选择前文也成功添加的 embedding 类型的模型。
● 解析方法:根据实际需要选择相应的解析方法即可。
● 其他参数:根据实际情况进行设置或保持默认即可。
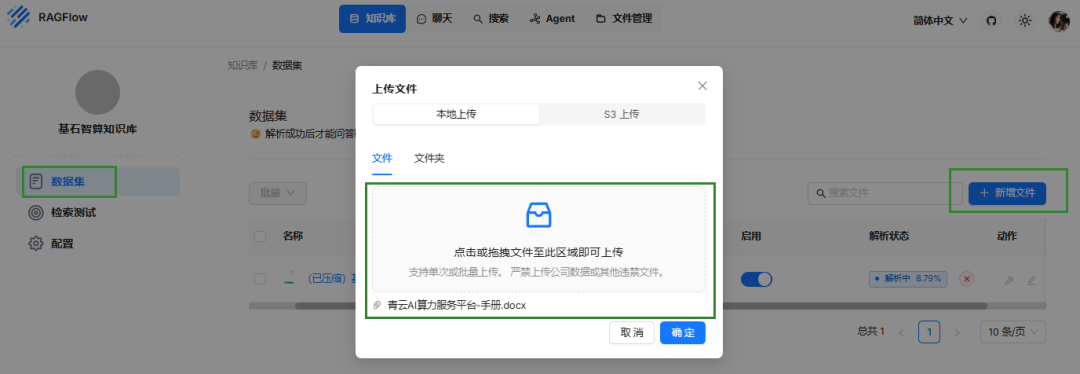
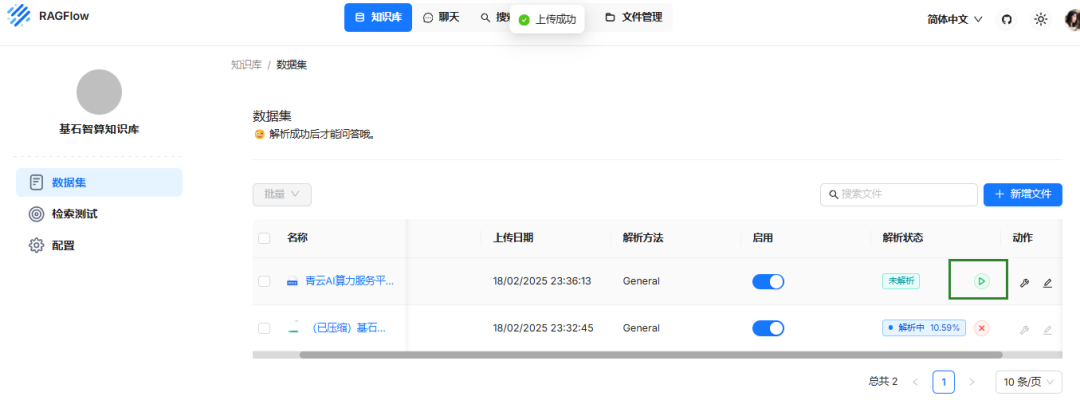
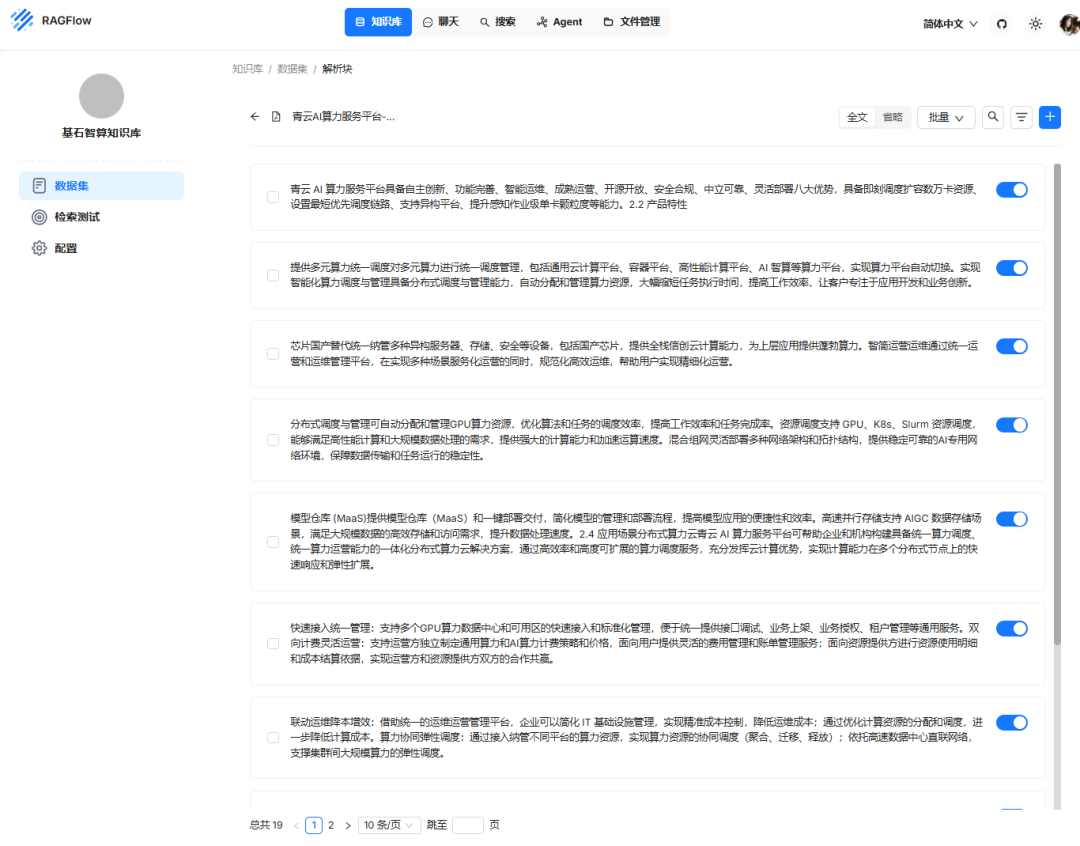
步骤四:构建应用
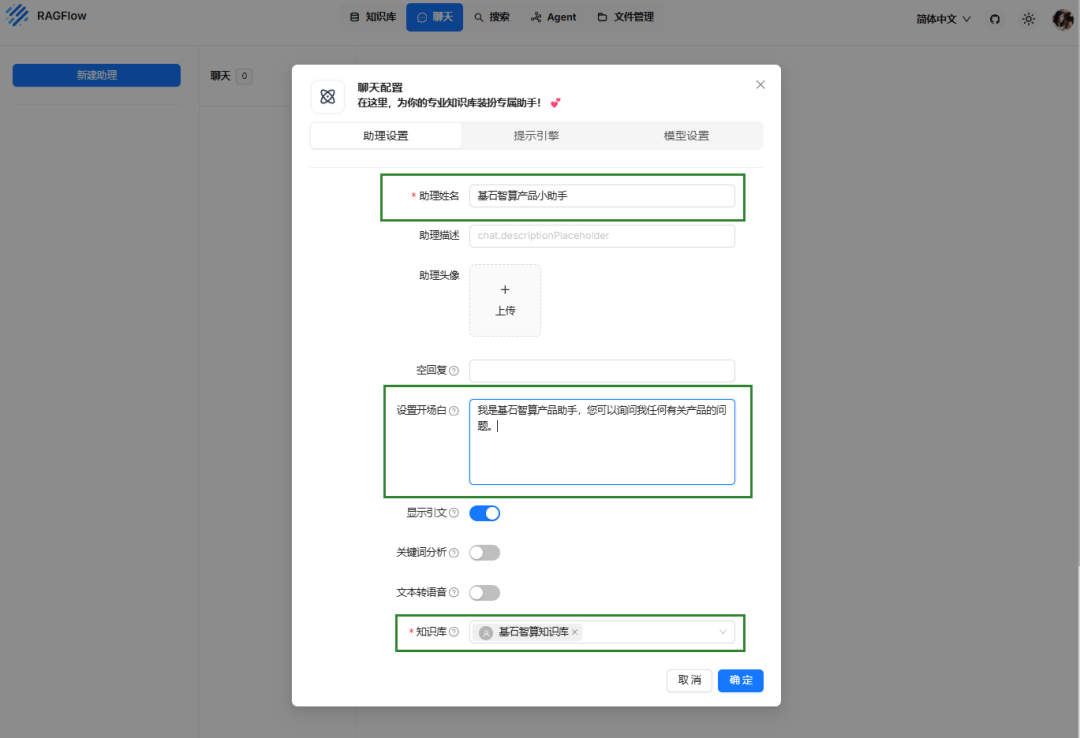
● 助理姓名:用户自定义。
● 设置开场白:用于设置聊天助理回复问题时的首句话,用户自定义。
● 知识库:选择前文新建的知识库即可。
● 其他参数,用户根据实际情况进行修改或保持默认即可。
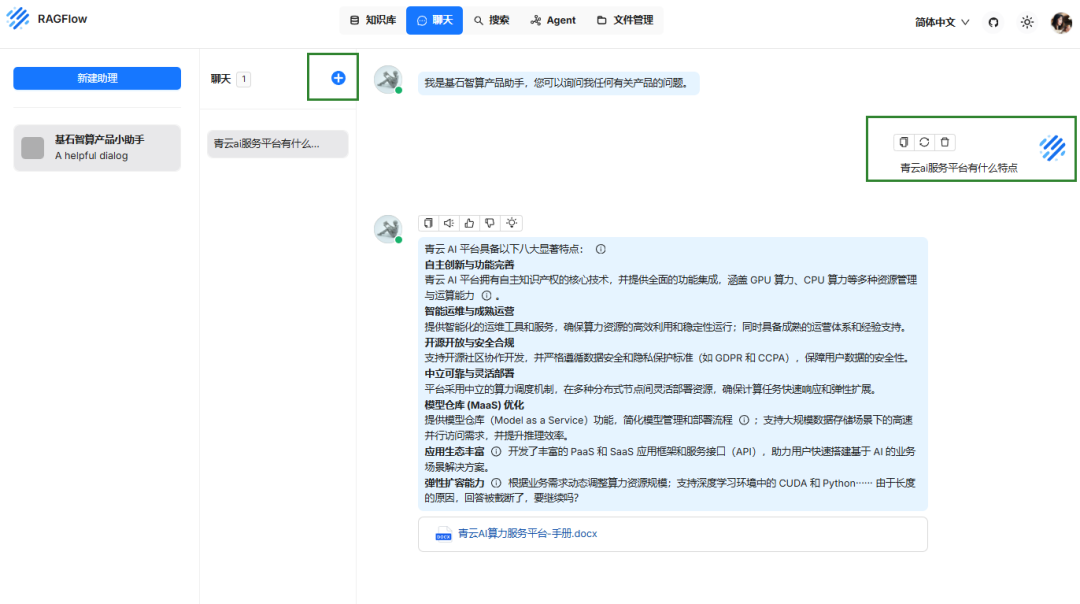
更多福利,速来体验

扫码立即体验


咨询售前专家

更多推荐





 点击“阅读原文”了解更多
点击“阅读原文”了解更多