




感谢大家一直以来对墨天轮问答平台的关注与支持!在数据库技术飞速演进的今天,我们见证了云原生、AI+数据库、向量检索等创新技术的落地实践,也看到越来越多的技术专家在社区内贡献智慧,帮助解决实际问题,推动行业发展。
在这里,每一次提问都可能引发一场智慧的碰撞,每一次解答都可能成为推动技术前行的一股力量。感谢大家一直以来对墨天轮问答平台的关注与支持,让我们携手共进,共同探索数据库技术的无限可能!接下来,我们更新本期 【墨天轮问答平台】中的高质量问题与专家解答,助力技术成长,启发更多思考。欢迎持续关注、积极参与!
1、各位老师,Oceanbase在truncate的表之后可以把这张表恢复出来吗?用的是什么方法?
解答:
应该要用到备份来做恢复了。
-
恢复租户(ob的恢复相当于恢复出一个新租户)到truncate之前(时间戳/SCN)。 表数据导出,导入回原租户表中。
-
或者可以试试按表恢复:https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000218375
和在传统数据库比如Oracle中类似,truncate table 在ob中也是DDL操作。v4版本truncate table不会进入recyclebin回收站。历史版本中曾经有变量ob_enable_truncate_flashback,但这个功能已经取消了。 这个变量已不再使用。在 V4.x 版本中,执行 TRUNCATE TABLE 操作不再支持进入回收站。尽管在 V4.x 版本中,该变量仍可查询和设置,但相关功能并不会生效。
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000220798
2、Oracle12c数据库,为什么有些表收集不了统计信息?报错如下,请帮看看
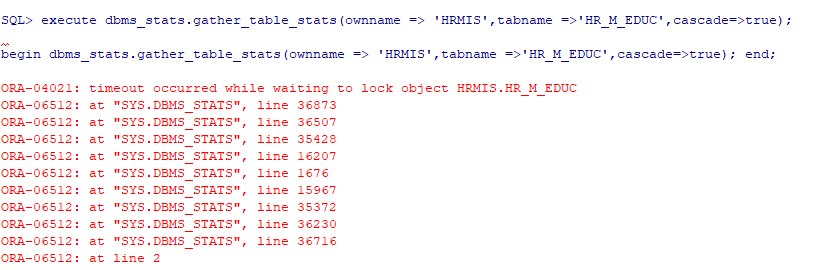
解答:
这应该是有锁,其他事物占用着,超过了等待时间限制就报错了,可以查询一下是那个会话是源头锁,kill掉源头锁再试试。
如何查询到有锁呢?查询当前收集统计信息的的会话信息,看看blocking_session,final_blocking_session列有没有值
3、在centOS 7.9 的系统上安装openGauss 数据库,预安装都成功了,但是就是启不起来,ffic_gaussdb 日志中爆出的错误信息提示CPU指令不兼容。 这是什么问题呢?
解答:
遇到这个情况,首先你需要看你主机的CPU架构是ARM的还是X86的,下载对应版本;另外就是需要关注glibc的版本问题。
4、pgbench 调用脚本不成功
postgresql
create table test_per2(id int,flag varchar(5));
cat update_per2.sql
\set v_id random(1,200000)
update test_per2 set flag='1' where id=:v_id;
pgbench -c 2 -T 20 -d postgres -U postgres -n N -M prepared -f update_per2.sql >update_per2.log
提示v_id取不到值,这个\set v_id random(1,200000) 哪里错了?
解答:
1.你的命令可能有点问题 -n N语法是不对的
2.可能跟你使用的数据库版本有关系
我测试下面的语句是正常的
pgbench -c 2 -T 20 -d postgres -U postgres -n -M prepared -f update_per2.sql
我准备搭建一套oracle 11g 的dg。主库是AIX上的双节点RAC,备库是虚拟机上的linux单实例。
主库上使用rman备份了全库、归档、控制文件,命令如下:
全库备份:backup as compressed backupset database format='/backup/rmanbak/bak/${ORACLE_SID}_%Y-%M-%D_%U.full';
归档备份:backup as compressed backupset archivelog all format='/backup/rmanbak/bak/${ORACLE_SID}_%Y-%M-%D_%U.arc';
控制文件备份:backup device type disk format '/backup/rmanbak/standby_%U.ctl' current controlfile for standby;
查看主库上备份的控制文件的权限:
# ls -l /backup/rmanbak
-rw-r----- 1 oracle asmadmin 24903680 Mar 24 15:43 standby_ff3l5kkb_1_1.ctl
使用sftp传输备份到备库,赋权
chown -R oracle:oinstall /data/rmanbak
查看备库上的备份的权限:
[root@mdmdb rmanbak]# ls -l /data/rmanbak/
-rw-r--r-- 1 oracle oinstall 24903680 Mar 24 15:43 standby_ff3l5kkb_1_1.ctl
备库使用rman恢复控制文件:
[oracle@mdmdb rmanbak]$ rman target /
Recovery Manager: Release 11.2.0.4.0 - Production on Tue Mar 25 17:55:10 2025
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
connected to target database (not started)
RMAN> startup nomount
Oracle instance started
Total System Global Area 4275781632 bytes
Fixed Size 2260088 bytes
Variable Size 1157628808 bytes
Database Buffers 3103784960 bytes
Redo Buffers 12107776 bytes
RMAN> restore standby controlfile from '/data/rmanbak/standby_ff3l5kkb_1_1.ctl';
Starting restore at 2025-03-25 17:55:31
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=385 device type=DISK
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of restore command at 03/25/2025 17:55:31
RMAN-06172: no AUTOBACKUP found or specified handle is not a valid copy or piece
在主库上备份的文件都是 asmadmin组的,备库上没有这个组,我在备库新建了这个组并把oracle用户加入进去,然后授权控制文件的备份为oracle:asmadmin,再恢复依然报RMAN-06172:
不知道到底是哪里的问题,希望能得到大神的指点
解答:
这个问题在问答区也是引发了众多技术专家的广泛讨论,后面在大家的帮助下,题主找到了答案并解决,我们一起来看看解决思路!
- aix到linux的字节序不一样,不能直接搭建dg,最好用操作系统的
- 题主从主库备份过来的密码文件也不能用,换了一个从其他linux操作系统上传过来的密码文件就可以远程登录了。目前在使用rman的duplicate方式搭建,可以正常连接target和auxilirary。但是报错:
RMAN> DUPLICATE TARGET DATABASE FOR STANDBY FROM ACTIVE DATABASE DORECOVER
2> ;
Starting Duplicate Db at 2025-03-26 15:23:13
using target database control file instead of recovery catalog
allocated channel: ORA_AUX_DISK_1
channel ORA_AUX_DISK_1: SID=1149 device type=DISK
contents of Memory Script:
{
backup as copy reuse
targetfile '/db/oracle/product/11.2.0/db/dbs/orapwmdmdb2' auxiliary format
'/u01/app/oracle/product/11.2.0/db_1/dbs/orapwmdmdb' ;
}
executing Memory Script
Starting backup at 2025-03-26 15:23:40
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=1182 instance=mdmdb2 device type=DISK
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of Duplicate Db command at 03/26/2025 15:23:42
RMAN-05501: aborting duplication of target database
RMAN-03015: error occurred in stored script Memory Script
RMAN-03009: failure of backup command on ORA_DISK_1 channel at 03/26/2025 15:23:41
ORA-17629: Cannot connect to the remote database server
ORA-17627: ORA-12514: TNS:listener does not currently know of service requested in connect descriptor
ORA-17629: Cannot connect to the remote database server
- 怀疑是tnsnames.ora没能被识别,因为oracle只在启动的时候加载一次tnsnames.ora,我的备库tns信息是新加入的,数据库识别不到。
- 重启一下主库试试
6、AWR分析报告问题求助:ASM file metadata operation 这个后台等待怎么查原因
解答:
要排查和解决Oracle数据库中的“ASM file metadata operation”等待事件,可按照以下步骤进行:
1. 检查ASM实例的等待事件
登录ASM实例,执行以下SQL查看当前等待事件:
SELECT sid, state, event, final_blocking_instance, final_blocking_session
FROM gv$session
WHERE event = 'enq: DD - contention';
- 如果存在大量enq: DD - contention且阻塞会话指向GPnP Get Item(如文档[1]所述),则可能是GPnP或RBAL进程导致。
2. 检查GPnP进程状态
- 在操作系统层面检查GPnP进程:
ps -ef | grep -i gpnpc
- 如果发现异常或挂起的GPnP进程,需谨慎终止(需评估集群影响):
kill -9
3. 确认ASM磁盘组权限及配置
检查ASM磁盘的权限和udev规则是否正确:
ls -l /dev/oracleasm/disks/*
udevadm info /dev/ # 确认规则匹配
- 检查存储空间及日志
- 查看ASM磁盘组空间使用:
SELECT name, total_mb, free_mb FROM v$asm_diskgroup;
- 检查ASM和数据库的告警日志:
tail -f $ORACLE_BASE/diag/asm/+asm//trace/alert_.log
tail -f $ORACLE_BASE/diag/rdbms///trace/alert_.log
5. 分析Hanganalyze及Systemstate Dump
在问题发生时生成诊断信息:
-- ASM实例中执行
ALTER SESSION SET EVENTS 'immediate trace name hanganalyze level 3';
ALTER SESSION SET EVENTS 'immediate trace name systemstate level 266';
6. 解决方案
- 若确认GPnP进程阻塞(如文档[1]):
- 在OS层终止GPnP进程(需集群环境允许,并评估风险)。
- 观察ASM和数据库恢复情况。
- 若问题反复出现,考虑升级集群软件或应用相关补丁。
- 其他可能原因:
- 存储延迟或故障:检查存储性能(I/O延迟、路径健康)。
- ASM元数据损坏:联系Oracle支持进行ASM元数据验证。
7. 预防措施
- 定期监控ASM和集群健康,确保磁盘组空间充足。
- 更新集群及数据库至推荐版本,修复已知Bug。
- 避免在高峰时段执行ASM元数据操作(如磁盘扩容、Rebalance)。

随着新一期问答集萃的发布,我们再次见证了技术社区的活力与智慧。衷心感谢每一位参与其中的朋友,无论是提问者、解答者还是默默关注的读者。让我们继续携手,乐知乐享,同心共济!
