




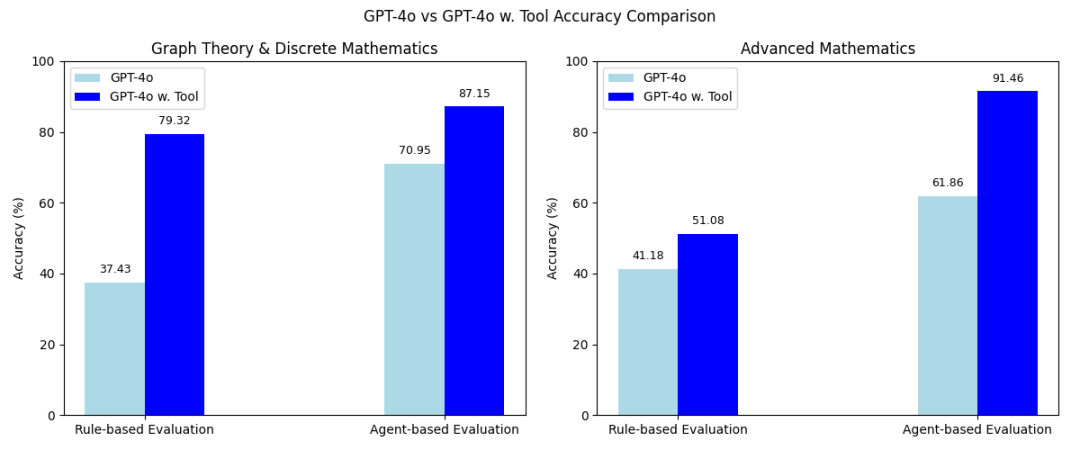
近年来,像 DeepSeek-R1 这样的大型推理模型表明,当基础模型在具有可验证奖励的强化学习(RL)机制下进行后训练时,其通用推理能力会显著提升。这种方法在数学和编程等领域表现尤为突出,因为这类任务的答案易于验证,从而能够对 LLM 的输出进行精确解释,并在语义层面对比真实答案。这种“可验证性是提升特定领域能力关键因素”的观点,已在学术界获得广泛认可。
另一个常被忽视的关键前提是:高质量数据集的充足性,这些数据集在数学和编程领域中往往包含了经过验证的正确答案与问题对。这些精心构建的数据为模型提供了可靠信号,使其能够学习如何构造连贯的 Chain-of-Thought(CoT),并稳定地导向正确答案。
然而,在许多同样需要可靠推理的领域——如逻辑、图论、物理和金融——却缺乏同类的数据集。而大规模地依赖人类监督生成数据成本极高。缺乏足够的正确示例,模型便难以习得特定领域的推理模式。这引出了一个关键问题:
我们是否能在数学与编程以外的领域,也实现类似水平的推理能力?
所以在这篇公众号中,我们将介绍 Loong 🐉 项目,一个致力于利用验证器(verifiers)扩展多领域 合成数据(synthetic data)生成规模的探索性工作。我们认为,synthetic data generation 不仅对于弥补数据稀缺领域的训练缺口至关重要,同时也能够通过扩充数据集规模,在数学与编程等领域进一步提升模型的推理能力。
|Project Loong 🐉 介绍|
// Closing the Verification Gap in Sythetic Data for RL
在合成问题与其对应答案之间,天然存在“正确性缺失”的差距——因为合成答案并不一定是正确的。若想彻底弥合这一差距,通常需要人类监督,但这在大规模上不可行。因此,我们的目标是尽可能在不引入人类监督的前提下缩小这一差距。
为此,我们构建了一个多智能体系统,从一个种子数据集(seed dataset)出发,自动生成合成问题及对应答案。这些问题被交由目标训练模型进行解答,我们再使用领域特定的 verifiers 对模型输出与合成答案进行语义层面的比较,以判断其正确性。
我们核心的设想基于一个简单的假设:
一个配备了 code interpreter 和人类构建的库或工具的 LLM,相较于仅依赖自然语言 chain-of-thought 推理的模型,能够以显著更高的可靠性解决问题。两者在性能上的差距可用于生成 synthetic data 以及用于 reinforcement learning。
这一点也符合直觉:很多非计算机科学领域(如物理学、神经生理学、经济学和计算生物学)在日常研究中都依赖代码来解决实际问题。
// The Loong Environment
由于我们的目标是进行 RL 实验,我们将所有组件构建成一个统一的、类似 OpenAI Gym 的 环境(environment),提供清晰的 RL 实验接口。
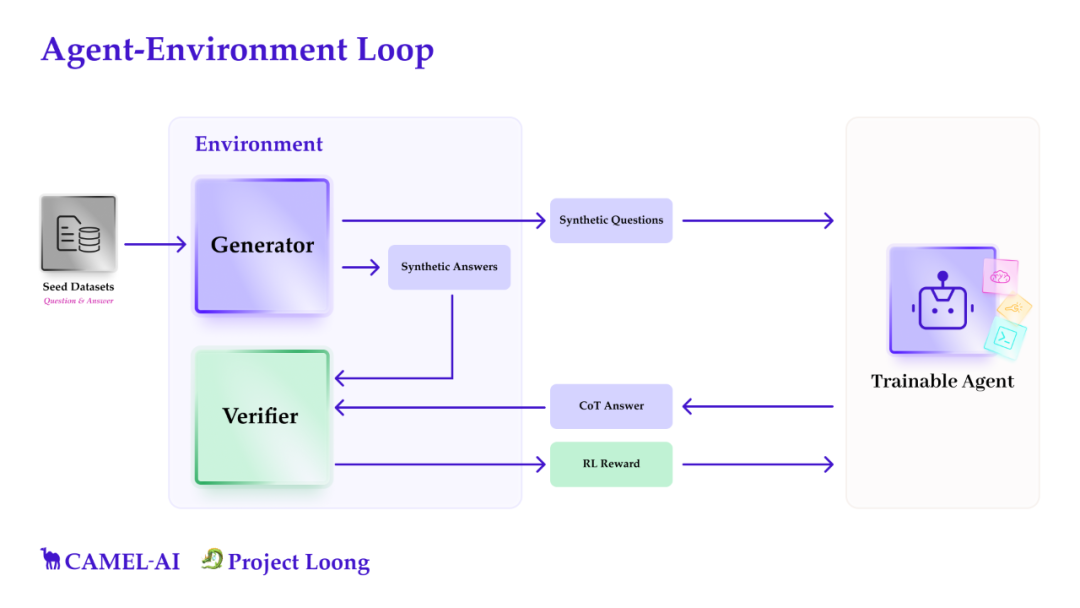
我们的环境由三大核心组件组成:
1. Seed Dataset
我们首先手动收集特定领域的问题-答案对,构成一个基础的种子数据集。每个问题都确保可以通过代码求解,并在可行时记录得到答案的代码。这些数据并不是用于直接训练的大规模数据集,而是用于bootstrap——即引导 LLM 开始生成合成数据的基础。
2. Synthetic Data Generator
合成数据生成器可以看作一个黑箱,它接收种子数据并据此生成任意数量的合成问题及其合成答案。环境本身并不对合成方法做任何假设,这意味着其内部可灵活更换为任何生成算法。当前,我们支持基于种子数据的 few-shot prompting 方式,也支持多智能体系统(multi-agent system),其中我们使用 self-instruct或者evol-instruct等方法生成问题,并用 solver agent 生成对应的合成答案。
需要特别强调的是,我们并不期望所有合成答案都是正确的。虽然我们认为由于引入代码执行机制,合成答案的正确率将优于 naive CoT 推理,但仍然不可避免地会有错误答案。
但这并不构成问题,因为我们并不会直接使用这些“原始合成数据”来训练模型。下一步我们将进行严格筛选,仅从被验证为正确的数据中学习。
3. Verifier
虽然合成数据生成器会产出大量数据,但在用于训练前必须对其进行过滤,剔除错误答案。为此,我们采用两种独立验证方式:
使用生成器代码执行,得到第一种解答;
使用自然语言 CoT 推理方式,独立生成第二种解答。
若两种解法结果一致,则我们有很大把握认为该答案是正确的。虽然存在两种方式在错误上“巧合一致”的极小概率,但考虑到两种方式的本质差异,这种情况应该非常罕见,不至于对训练构成重大影响。
此外,环境中还包含一个专门的 verifier,用于对模型的自然语言回答与合成答案进行语义等价性验证。这一验证步骤对于过滤语义等价但形式不同的正确答案至关重要,可显著减少“假阴性”——即语义正确却被误判为错误的情况。
我们最终希望训练的,是那个通过自然语言生成 Chain-of-Thought 的 agent。在强化学习过程中,只有当该 agent 生成的 CoT 答案与 verifier 判定的 synthetic answer 在语义上等价时,才会获得正向奖励(positive reward)。这样,我们就确保了模型只从可能正确的数据中学习。
// 使用 Loong 环境进行开发与实验
我们将使用 FewShotGenerator,它通过简单的 few-shot prompting,从种子数据集中随机选取若干数据点作为示例,生成新的数据样本。
种子数据集可以直接视为一种 StaticDataset,因此我们将以 StaticDataset 的形式初始化我们的种子数据集。
# 🐍 Install in editable mode with dependencies!pip install "git+https://github.com/camel-ai/camel.git@bec98152d3df3dd1731b78208608b4a9438a010e#egg=camel-ai[all]"# ⬅️ Return to notebook root%cd ..
from camel.datasets import StaticDatasetfrom datasets import load_datasetdataset_dict = load_dataset("camel-ai/loong")dataset = dataset_dict["train"].filter(lambda example: example['source_type'] == 'graph_discrete_math')seed_dataset = StaticDataset(dataset)
seed_dataset[0]
FewShotGenerator 需要一个 Python 解释器来执行其生成的代码,并据此计算伪 ground truth。为此,我们需要定义一个 PythonVerifier。
我们很快将会使用专门基于 CAMEL 的代码解释器来替代目前复用 PythonVerifier 的做法。
from camel.verifiers import PythonVerifierfrom camel.agents import ChatAgentfrom camel.extractors import BaseExtractor, BoxedStrategyinterpreter = PythonVerifier(required_packages=["numpy", "networkx"])await interpreter.setup(uv=True)
最后,我们需要为generation agent配置一个模型后端。这里我们使用 ModelFactory 来创建该模型实例。
本示例默认使用 GPT-4o mini,因此我们加载了 OpenAI 的 API 密钥。你也可以根据需要替换为其他模型。
import osfrom getpass import getpass# Prompt for the API key securelyopenai_api_key = getpass('Enter your API key: ')os.environ["OPENAI_API_KEY"] = openai_api_key
from camel.models import ModelFactoryfrom camel.types import ModelPlatformType, ModelTypefrom camel.configs import ChatGPTConfigfrom camel.datasets import FewShotGeneratormodel = ModelFactory.create(model_platform=ModelPlatformType.OPENAI,model_type=ModelType.GPT_4O_MINI,model_config_dict=ChatGPTConfig().as_dict(),)# Note: When the generator needs to create new datapoints, it will by default create 20 new datapoints# Since we are paying for the API, let's set this number to 2 insteadgenerator = FewShotGenerator(puffer=2, seed_dataset=seed_dataset, verifier=interpreter, model=model)
接下来,我们将创建一个 verifier,它能够从 LLM 的回复中提取 \boxed{...}
内的内容,并将其与参考答案进行语义级别的比较。
from camel.verifiers import PythonVerifierfrom camel.agents import ChatAgentfrom camel.extractors import BaseExtractor, BoxedStrategy# Initialize extractorextractor = BaseExtractor([[BoxedStrategy()]])verifier = PythonVerifier(extractor=extractor, required_packages=["numpy", "networkx"])await verifier.setup(uv=True)
现在我们已经配置好了 generator 和 verifier,接下来可以使用它们来创建一个 SingleStepEnv 环境。
随后,我们可以调用 env.reset()
来从底层 generator 中采样一个样本,该样本将作为一个 observation(观测值) 返回。然后,我们可以将这个 observation 输入到 CoT agent 中进行处理。
from camel.environments import Action, SingleStepEnvenv = SingleStepEnv(generator, verifier)obs = await env.reset(seed=42)print(obs)
智能体接收到该 observation 后,会对其进行处理并生成一个 action(动作),然后将该 action 输入到环境的 step
函数中。该函数会将动作传递回环境,更具体地说,会将其传递给 verifier,由 verifier 判断 LLM 的回复与参考答案是否一致,并据此返回一个 reward(奖励)。
我们首先定义一个 CAMEL agent 并将 observation 输入给它;随后,使用环境的 step
函数来获取对应的 reward。
agent = ChatAgent(model=model)USER_PROMPT = r"""You are an agent designed to answer mathematical questions with clarity and precision. Your task is to provide a step-by-step explanation forany mathematical problem posed by the user, ensuring the response is easy to follow. Adhere to these guidelines:Analyze the mathematical question carefully and break down the solution process into clear, logical steps.Use natural language to explain each step, incorporating LaTeX notation (e.g., $x + 2$)for mathematical expressions when helpful. Conclude your response with the final answer enclosedin a LaTeX \boxed{} environment (e.g., \boxed{5}).Place this at the end of your explanation as a standalone statement.It should be a Python expression, for example "[1, 2, 3]" for a list.The question you should answer is: """
最后,我们将智能体的输出与我们的伪 ground truth 进行比较,以评估其在当前任务中的表现:
response = agent.step(USER_PROMPT + obs.question).msgs[0].contentresult = await env.step(Action(index=0, llm_response=response))agent.reset()print(result)
Environment Loop
接下来,让我们看看这一过程在loop的实际运行方式。
for i in range(2):obs = await env.reset()response = agent.step(USER_PROMPT + obs.question).msgs[0].contentnext_obs, reward, done, info = await env.step(Action(llm_response=response))print(f"Reward at step {i}: {reward}")agent.reset() # to clear context window
// 如何参与
研究者与开发者可以使用 Loong 环境,在多个领域生成合成数据。目前,我们已收集了数学、图论、数理规划与逻辑领域的种子数据。
这些种子数据及使用手册可在 Github 上获取(欢迎给我们点🌟呀):
https://github.com/camel-ai/loong
Seed Dataset也已上传至HuggingFace:
https://huggingface.co/datasets/camel-ai/loong
同时,我们鼓励大家自行收集特定领域的种子数据,并借助 Loong 🐉 为你的领域构建合成数据集。目前我们正基于 Loong 环境,在不同规模的 LLM 上进行 post-training 实验,观察其在通用推理与特定领域推理能力上的提升。我们正在尝试多种 reward 设置,目前主要关注于 accuracy reward,遵循 DeepSeek 的相关方法。更多实验细节及结果将在我们即将发布的 preprint 论文中公布。
在 CAMEL,我们相信环境(environment)是提升领域推理能力的关键机制。只要问题能够被清晰地形式化为一个环境,智能体就有可能在其中实现自主学习与精通。
通过 Loong 🐉,我们希望解决合成数据生成中的一个核心挑战:通过可验证性(verifiability)来保障数据质量。我们的目标,是让各类领域的可靠推理数据集更容易构建,哪怕该领域缺乏现有的人工数据。
我们也诚挚邀请研究者与开发者贡献种子数据、verifier 模块与新的创意,共同完善和扩展这个项目。可扫码进群共同交流 Project Loong 🐉

在 CAMEL,我们相信环境(environment)是提升领域推理能力的关键机制。所以除了Loong项目,我们还有其他与环境相关的项目,比如说OASIS、OWL、CRAB。对共建环境(Environments for agents)感兴趣的朋友也可以扫描下方二维码进群交流!

我们接下来还有3天对Scaling Environments for Agents的项目发布,欢迎关注CAMEL AI的发布网页获取最新信息:
https://www.camel-ai.org/launchweek-environments

CAMEL微信群


加入CAMEL微信群,请添加CAMEL官方微信号CamelAIOrg,会有工作人员通过您的好友申请并邀请您加入我们的微信群~
Join CAMEL Community

www.camel-ai.org

https://github.com/camel-ai/camel

https://discord.camel-ai.org
