




Galaxybase原生分布式图数据库
1、属性图
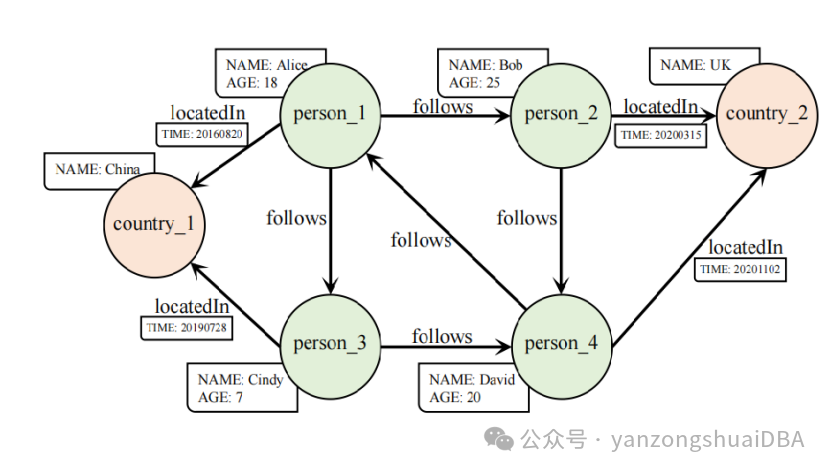
属性图模型:点和边上可以处理各种属性。如上图所示,点和边分配了一个类型,例如person(点)、country(点)、follows(边)、locatedIn(边)以及一组属性,比如NAME:ALICE and TIME:20201102。
2、galaxybase架构
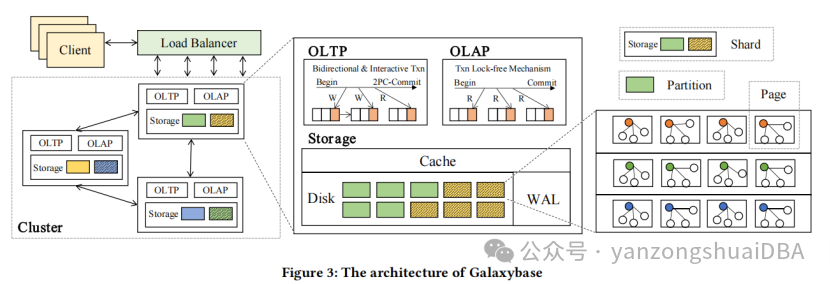
原生分布式并行架构。存储模型分为三级:shard、partition和page。
1)和关系性分布式数据库类似,在关系型数据库(比如GreenPlum)中将一个表根据分布键进行分片,从而将表数据分布在各个Segment数据节点上;
2)这里以边切的方式切图,根据点的ID进行分布,并将对应边存储在一起(这里指的是放在同一个存储节点上)。将图根据点ID分布在各个存储节点上,每个图的分片在单个存储节点上形成一个partition,同样的partition内容在其他存储节点上构成副本。他这里的shard定义和其他地方不同,它将同一个存储节点上所有的partition包括副本构成一个shard,而不是同一个partition和其他存储节点上的副本构成一个shard,这点需要注意
3)每个partition中部署了日志结构邻接表用于存储点和边数据,实现无索引邻接,从而方便图遍历和从磁盘上顺序读写。
4)为了进一步优化边查询性能,partition中为每个点创建了一个Edge Page,将每个点的所有邻边放到一个页中。
5)WAL和关系型数据库中的一样,作为变更日志写到磁盘,系统崩溃重启时可以通过WAL进行恢复
3、数据存储
Partition中处理Log-Structured Adjacency List(日志结构邻接表),将点和表作为邻接表,并存储多版本数据,最后将数据批量写回磁盘;Page级别部署了Edge Page结构,在图遍历和单边查询等基本操作中实现高性能。
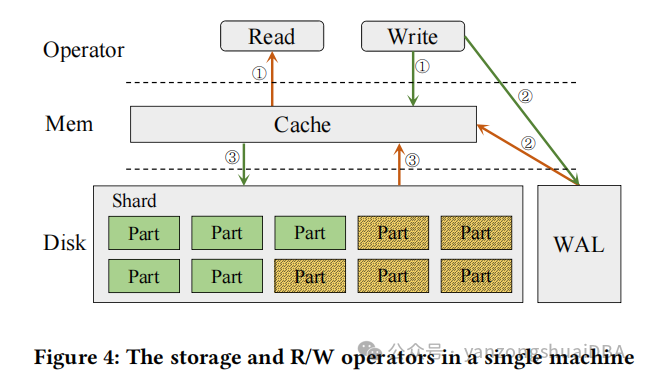
如上图所示,galaxybase对集群中每个服务构建了两层存储模式,内存中是cache模块,以及磁盘上的持久化模块。持久化模块包括WAL和数据。
写操作:绿色箭头展示了写流程,首先数据会写到cache和WAL到磁盘:cache提高了读写效率,WAL确保数据一致性。当数据的WAL持久化到磁盘,并且数据更新到cache后就认为写完成了。当缓存中的数据满足驱逐标准时,异步、顺序、批量写到shard的partition中
读操作:黄色线表示了读操作,首先从cache中进行查找,如果数据都在cache中就可以返回,否则需要从磁盘上的shard中加载检索,合并cache中和读上来的数据。默认情况下,WAL中的数据会同步到cache中
数据驱逐策略:内存的使用影响到了系统稳定性;利用LRU策略驱逐最近读的数据;cache中更新的数据达到了阈值。
4、日志结构邻接表
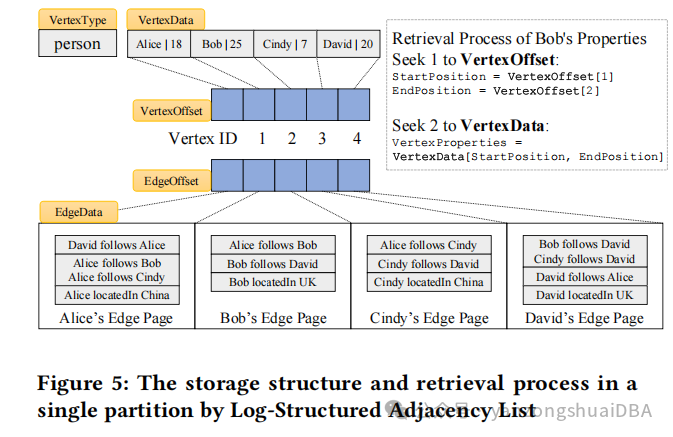
1)一个partition用来存储一个单一类型的点和它的边,在这些partition中,点和他们的属性存储在一起
2)它的邻边分组放在一个Edge Page中
3)每个点分配了一个唯一的ID,允许高效检索点的属性;通过一个offset数组高效访问边。
如上图所示:
(1)person类型的点,它的VertexData中存储了Alice、Bob、Cindy、David四个点,后面分别一起存储着他们的年龄属性。VertexOffset数组存储着每个点的偏移
(2)检索Bob的属性,起使位置StartPosition=VertexOffset[1],EndPosition=VertexOffset[2],然后VertexProperties = VertextData[StartPosition,EndPosition]
(3)EdgeOffset数组存储着对应点的每个边的Edge Page的偏移,比如Bob的边:
EdgeOffset[1]就是bob的Edge Page的地址
(4)Bob的Edge Page中存储着它的所有边,包括入边、出边
邻接表的方式提升了批量数据读比如执行图遍历查询或者指定类型的所有点的性能;但是在VertexData中找指定点或者它的边时,提出了挑战。为此,JanusGraph等使用LSM-Tree(使用有序存储)来进行磁盘数据检索。磁盘上数据以Sorted String Tables(SSTables)形式存储,数据有序组织,最坏情况下的读时间复杂度为O(Log(n)),n为磁盘上记录的数量。为了克服这么个限制,使用如上图5所示方法,galaxybase的读时间复杂度为O(1),
5、Edge Page
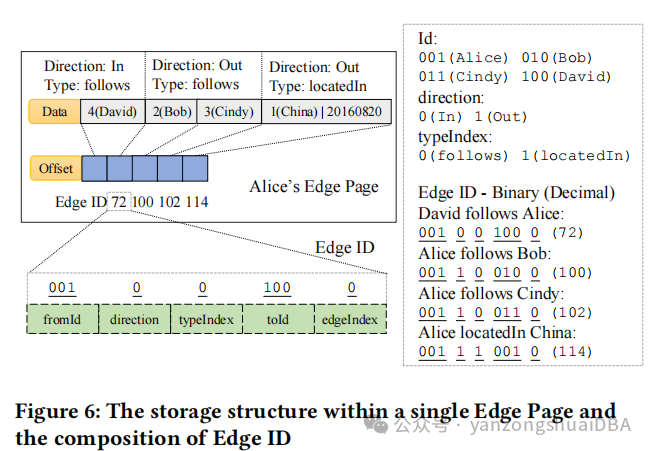
邻边检索提升性能的关键点:查询过程中减少磁盘seek,不同查询条件上的过滤时避免冗余数据的读。为此,利用一个每个点的唯一ID利用Edge Offset精确定位Edge Page。
没有过滤检索点的邻边:给定Vertex ID,直接遍历它的整个Edge Page中的所有边数据。如上图所示,每个Edge Page基于type、direction、size来组织边。第一个page存储了follows类型+In方向。引入Offset[]数组存储Edge ID(唯一的ID)通过direction、type等参数定位指定边。Edge ID由起使点的ID、direction、type index、终止点ID、边index组成:
1)fromID:起使点的唯一ID
2)direction:边的方向。0表示In,1表示Out
3)typeIndex:表示edge的类型,对应不同的边类型,比如flolows、locatedIn等
4)toId:终点的唯一ID
5)edgeIndex:边的唯一索引,唯一标记相同fromId和toId的所有边
每个Edge Page中基于Edge ID使用一个多维排序方法,fromId、direction、typeIndex、toId和edgeIndex有序。边存储策略应该该结构,自然的就会将同样type和direction的边进行分组,确保Edge Page内有序。
指定方向遍历一个点的邻居:为了找Alice的In方向的邻居,首先定位该点的Edge Page,然后计算In和Out的边界,Edges同样方向的会顺序存储。fromId为001,direction为1,typeIndex和toId和edgeIndex为0,我们获得了001100000,转换成数字96。在Offset中进行二分查找定位位置。然后从遍历edge数据从starting位置到located位置。同样的策略应用在Out方向的邻居遍历。
指定direction和type遍历点的邻居:为了遍历Alice的follows和Out方向的邻居,首先定位到点的Edge Page,然后计算follows和Out的Offset数组中的start和end位置。同样direction和type的边连续存储,fromId为001,direction为1,start的typeIndex为0、end的typeIndex为1,其他值是0,得到了001100000作为start(96),001110000作为end(112),然后执行二分查找。最后遍历两个located position中的值就是需要的值
定位指定边:为了通过Edge ID定位边,首先需要找到点的Edge Page,然后使用Edge Page的Offset数组进行二分查找,精确定位边
优点:1)将点的所有邻边组织在也给Edge Page内,避免频繁磁盘IO;2)每个Edge Page内确保同样type和direction的边连续存储,便于高效处理各种查询;3)Edge Id的构建使得有序存储,便于高效定位指定边
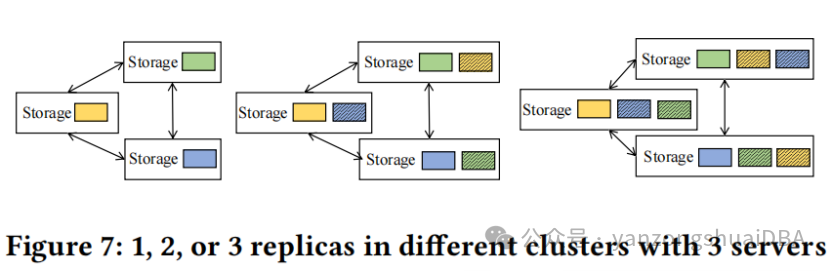
6、分布式存储策略
使用两种分布式存储策略:data partitioning和data replication:
数据partition策略:
1)内置图分片策略:可以使用hash(默认);METIS基于图结构的分片;METIS带属性,基于图结构和点/边属性
George Karypis and Vipin Kumar. 1997. METIS: A software package for partitioning unstructured graphs, partitioning meshes, and computing fill-reducing orderings of sparse matrices.
2)自定义图分片策略:如果向将同样属性的数据分片到相同的partition,用户可以在导入数据时指定partition ID;即使对原始数据不太了解,可以利用默认或者自定义算法分析图数据,为每个点插入何使的ID
数据副本策略:每个partition可以在其他服务上存储副本。和分布式数据库比如GreenPlum类似,多副本保证一个故障后,仍旧可用
7、参考
Glaxybase2024年VLDB的论文:Galaxybase: A High Performance Native Distributed Graph
Database for HTAP
