




Oracle HeatWave MySQL 服务为用户提供了修改数据库系统形状和配置的灵活性,使他们能够适应不断变化的工作负载并提高性能。
在这篇博文中,我们将分享与数据库系统形状和配置变化相关的最新变化的见解,主要关注高可用性和读取副本支持。
为什么要更改数据库系统形状和配置?
扩展数据库系统的容量是更新其形状的最常见原因。更大的形状可提供更强的计算能力、更大的内存,并可解锁可选功能,例如支持只读副本和 HeatWave 集群。Oracle HeatWave MySQL 服务在此页面中提供了受支持形状的列表,每种形状都有自己的特点和限制。
DB 系统配置是特定于形状的。不同的默认配置针对不同的形状进行了优化,内存和 CPU 选项使用预定义值进行调整。因此,更改 DB 系统的形状还需要在同一请求中更新其配置。
最大化数据库系统可用性
在 DB 系统中启用高可用性 (HA)可以显著减少读/写点的恢复时间目标 (RTO),不仅在故障情况下,而且在维护或形状和配置更新期间。
通过依赖高可用性,您还可以最大限度地降低维护或形状和配置更新期间 READ/WRITE 端点受到影响的风险。这可以通过以滚动方式协调 HA 组成员上的更改来实现(与HA DB 系统的维护中描述的方法相同):
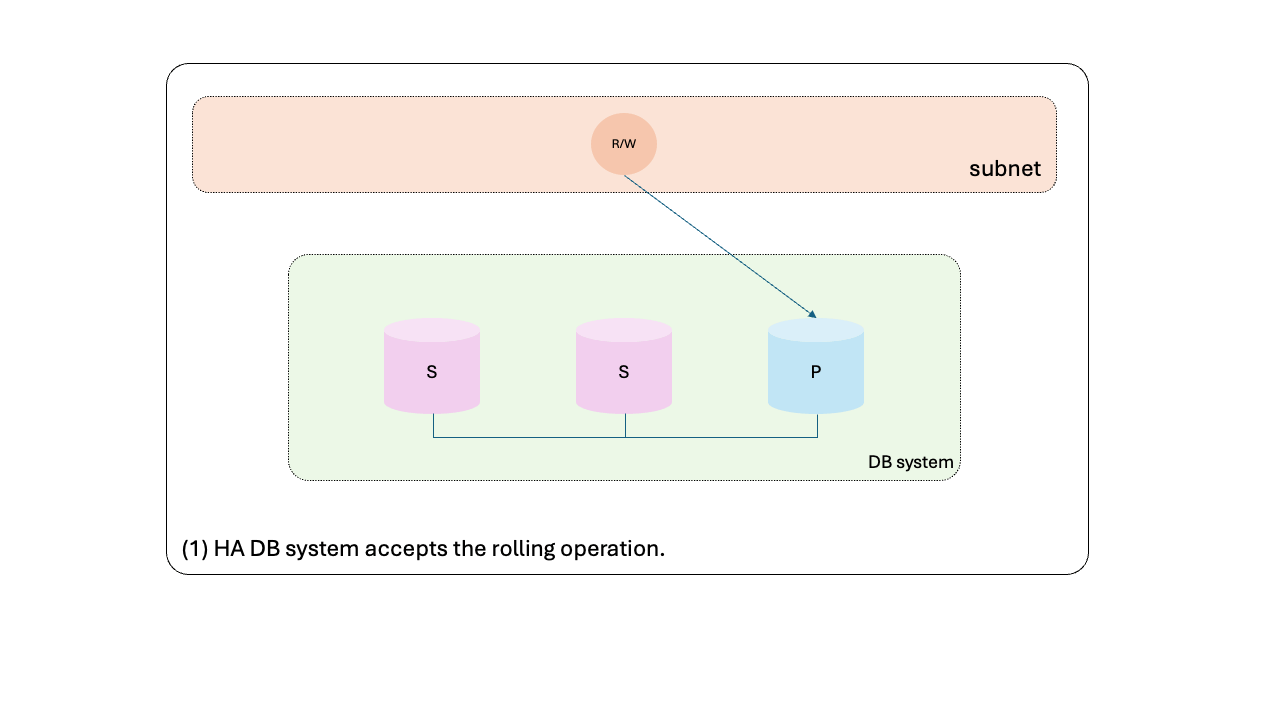
- HA DB 系统接受滚动操作。
- 第一个辅助节点已从要更新的组中删除。
- 第一次更新。
- 将第一个辅助节点添加回 HA 组。
- 第二个辅助节点已从要更新的组中删除。
- 第二次更新。
- 第二个辅助节点被添加回 HA 组。
- 受控故障转移启动:停止主服务器上的写入并将其从 HA 组中删除。
- 受控故障转移:选出新的主节点。
- 受控故障转移完成:R/W 端点重新连接到新的主端点。
- 前主要内容已更新。
- 将前一个主节点重新添加至 HA 组。
可以将上述步骤根据其对 READ/WRITE 端点的影响分组为:
- 先在次级中逐一执行操作(步骤 1 至 7):
- 主服务器保持不变,直到所有辅助服务器都成功更新为止;
- 每个更新的辅助节点在操作完成后重新加入该组。
- 执行我们所说的“受控故障转移”(步骤 8 至 10):
- 一旦只剩下主组成员可供操作,编排框架就会隔离主成员并将其从 HA 组中删除,以触发新的主选举;
- 最近操作的辅助节点之一接管了 HA 组中的主节点角色,并且在几秒钟内,数据库系统读/写端点将重新连接到新的主节点。
- 在这种情况下,在 READ/WRITE 端点中观察到的停机时间发生在从前一个主节点被隔离到将 READ/WRITE 端点重新连接到新的主节点之间。
- 在前一个主节点中执行操作(步骤 11 和 12):
- 它将作为辅助服务器重新加入 HA 组。
不会刻意切换回之前的主服务器,以避免在操作过程中再次停机。如果需要,用户可以在最方便的时候进行手动切换。
注意:任何更新 HA DB 系统配置的请求(即使仅更改动态变量)都将利用具有“受控故障转移”的滚动框架来确保最小的中断。
最大化读取可用性
读取副本是扩展读取和避免只读工作负载停机的重要组成部分。
在更新数据库系统的形状和配置时,新的滚动框架也会以滚动方式逐一协调对只读副本的更改。此过程可确保只读副本负载均衡器终端节点的停机时间可忽略不计。在更改高可用性数据库系统的任何 HA 组成员(或为独立数据库系统服务的读/写终端节点的实例)之前,先更新只读副本。
对于具有多个只读副本的数据库系统,负载均衡器终端节点将始终具有可用的只读副本,以便在更新过程中处理读取请求。以下是编排过程的概述:
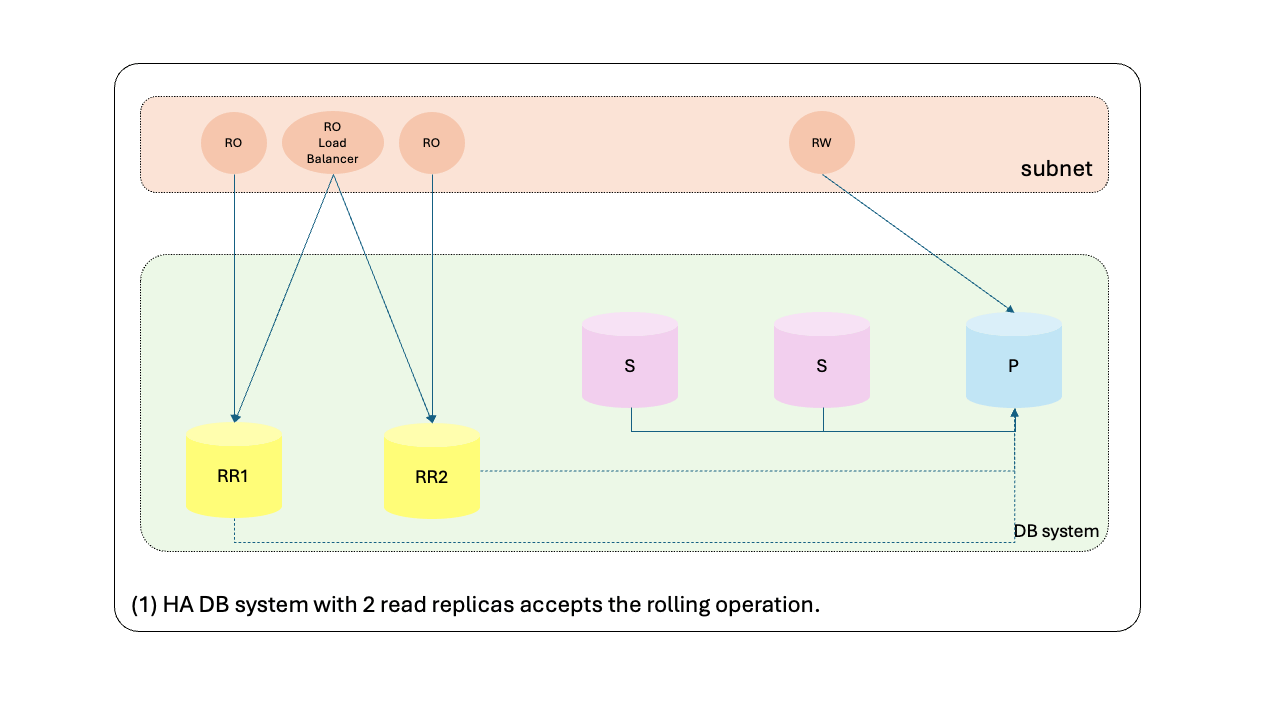
- 具有 2 个只读副本的 HA DB 系统接受滚动操作。
- 第一个读取副本已准备好更新。
- 第一个读取副本已更新。
- 设置第一个读取副本以再次提供读取流量。
- 第二个读取副本已准备好更新。
- 第二个读取副本已更新。
- 设置第二个读取副本来再次提供读取流量。
更新只读副本后,应按照前面描述的 HA DB 系统更新中的步骤 2 到 12 进行操作(与 HA 组成员更新相关)。
这意味着读取副本负载均衡器端点上的停机时间可以忽略不计!此外,在业务流程更新读取副本时,READ/WRITE 端点预计不会有任何停机时间。
注意:只读副本可以更新为具有其自己独特的形状和配置。只有不覆盖数据库系统形状和配置的只读副本才会通过更新数据库系统形状和配置的请求自动更新。
弹性运营
在滚动操作期间,如果检测到任何故障,编排框架将停止该过程以防止长时间停机。这种主动措施可确保我们保持系统完整性。
对于 HA DB 系统,我们的设计可确保如果其中一个辅助数据库遇到问题,从应用程序角度来看不会出现可观察到的停机时间。即使在更新前一个主数据库时发生故障,停机时间仍与成功更新保持一致,从而最大限度地减少任何潜在影响。
发生故障时,数据库系统生命周期详细信息可能会指示形状名称、配置 OCID 或 MySQL 版本等属性存在不一致:
DB 系统资源在以下属性中包含不一致之处:...
请验证属性并更新 DB 系统,或联系支持人员。
当更新请求失败导致部分 HA 组成员更新不一致时,使用相同目标属性值的重试操作将仅影响需要更新的成员。这可确保已更新的 HA 组成员不会再次更改。
或者,您可以通过使用当前 DB 系统属性值发起新的更新请求来执行回滚。与重试类似,只会操作需要更新的 HA 组成员。
您还可以请求新的更新,其目标值既不是当前值,也不是之前失败尝试时的目标值。在这种情况下,预计所有 HA 组成员都会被操作。
尽管系统设计为即使存在不一致也能保持运行,但不建议长时间运行这些差异。始终验证属性并采取必要步骤更新 DB 系统或联系支持人员获取指导。
自动 HeatWave 集群恢复
滚动数据库系统形状和配置操作将自动恢复高可用性数据库系统上的任何 HeatWave 集群,就像维护期间或意外主要故障后发生的情况一样。
概括
以最少的停机时间更新数据库系统对于资源优化和适应云服务内不断变化的工作负载至关重要。
为了确保顺利过渡,避免常见错误并遵循最佳实践非常重要。彻底测试新配置、应用详细规划、了解应用程序要求并关注持续可用性对于为最终用户维持不间断的服务至关重要。
通过利用这一新功能并遵循上面概述的指导原则,您可以自信地调整数据库系统形状和配置,并以最少的停机时间。
要探索 HeatWave MySQL 的功能,请访问oracle.com/heatwave/free并免费创建一个。
要了解有关 HeatWave MySQL 的更多信息,请访问oracle.com/mysql。
原文地址:https://blogs.oracle.com/mysql/post/changing-heatwave-mysql-shape-and-configuration-with-minimal-downtime
原文作者:João Gramacho
