




本文对复旦大学入选2024 ICDE论文《METASQL: A Generate-then-Rank Framework for Natural Language to SQL Translation》进行解读,文共4926字,预计阅读需要15至25分钟。
在大数据时代,自然语言接口到数据库(NLIDB)技术的重要性日益凸显。NLIDB通过自然语言交互,使非技术用户能够访问数据库。然而,现有的NLIDB方法在处理复杂查询时存在局限性。文章提出的MetaSQL框架,通过引入查询元数据来控制SQL查询候选的生成,并利用学习排序算法来检索全局优化的查询,从而显著提高了翻译的准确性。
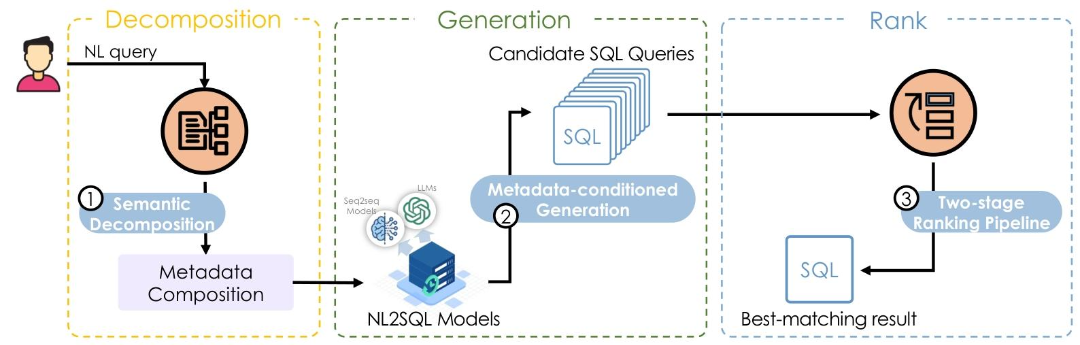
METASQL 概述
1.1 自然语言接口到数据库的重要性
在当今数字化时代,数据库已成为存储和管理海量数据的核心工具。然而,传统的数据库查询语言如SQL,对普通用户来说具有较高的技术门槛。自然语言接口到数据库(NLIDB)技术应运而生,旨在通过自然语言交互,使非技术用户能够轻松访问和操作数据库。NLIDB技术不仅降低了数据库使用的复杂性,还扩大了数据库的用户群体,使更多人能够从数据中获取有价值的信息。
NLIDB技术的应用场景非常广泛,包括但不限于:
◆ 商业智能:帮助业务分析师快速生成报告和图表。
◆ 客户服务:通过自然语言查询客户数据,提高服务效率。
◆ 教育领域:辅助教师和学生查询教育数据,提升教学效果。
◆ 医疗健康:帮助医疗工作者快速查询患者数据,支持临床决策。
随着数据量的爆炸式增长和应用场景的多样化,NLIDB技术的重要性日益凸显。它不仅提高了数据的可访问性,还促进了数据驱动决策的普及。
1.2 现有方法的局限性
1.2.1 自回归解码的局限性
现有的NLIDB方法主要依赖于神经序列到序列(Seq2seq)模型或大型语言模型(LLMs),通过自回归解码生成SQL查询。自回归解码是一种逐个生成输出序列的方法,每个输出元素的生成依赖于之前生成的元素。尽管这些方法在翻译准确性上取得了显著进展,但在生成单个SQL查询时,自回归解码存在以下局限性:
1. 输出多样性的缺乏:自回归解码通常使用束搜索或采样方法(如Top-K采样)来生成候选序列。然而,这些方法往往生成的候选序列相似度较高,缺乏多样性。例如,在图1中,LGE SQL模型生成的前五个SQL查询候选几乎完全相同,只是在细节上略有差异,导致最终翻译结果不准确。
2. 全局上下文意识的不足:由于自回归解码是基于之前生成的标记逐个生成输出,因此容易陷入局部最优解。它无法充分利用全局上下文信息,导致在复杂查询中难以找到正确的翻译结果。
1.2.2 现有方法的性能瓶颈
尽管现有的NLIDB方法在一些基准测试中取得了不错的性能,但在处理复杂查询时仍存在明显的性能瓶颈。例如,在SPIDER基准测试中,最先进的模型在测试集上的语法等价翻译准确率仅为74.0%。这表明现有方法在处理复杂SQL查询时仍有很大的改进空间。
1.3 提出MetaSQL的动机
为了解决现有方法的局限性,MetaSQL框架应运而生。MetaSQL的核心思想是通过引入查询元数据来控制SQL查询候选的生成,并利用学习排序算法来检索全局优化的查询。具体来说,MetaSQL通过以下方式提高翻译准确性:
1. 语义分解:将自然语言查询的语义映射到一组查询元数据,这些元数据作为生成SQL查询的约束条件。
2. 元数据条件生成:利用查询元数据作为控制信号,指导翻译模型生成多样化的SQL查询候选。
3. 两阶段排名管道:通过粗粒度和细粒度的排名模型,从生成的候选查询中选择最符合自然语言查询语义的SQL查询。
1.3.1 语义分解的必要性
语义分解是MetaSQL框架的第一步,它将自然语言查询的语义映射到一组查询元数据。这些元数据包括操作标签、复杂度值和正确性指示器,能够捕捉自然语言查询的高层语义。通过语义分解,MetaSQL能够更精细地理解自然语言查询的意图,从而生成更准确的SQL查询。
1.3.2 元数据条件生成的优势
元数据条件生成步骤通过将查询元数据作为语言提示,指导翻译模型生成多样化的SQL查询候选。这种方法不仅增加了生成结果的多样性,还通过元数据的约束减少了生成错误查询的可能性。例如,在图1中,MetaSQL通过条件生成步骤生成了多个不同的SQL查询候选,从而提高了找到正确翻译结果的概率。
1.3.3 两阶段排名管道的有效性
两阶段排名管道通过粗粒度和细粒度的排名模型,从生成的候选查询中选择最符合自然语言查询语义的SQL查询。第一阶段的粗粒度排名模型快速筛选出一组较小的候选集,第二阶段的细粒度排名模型则利用多粒度监督信号,精确地确定最终的顶级排名SQL查询。这种两阶段的排名方法能够充分利用全局上下文信息,克服自回归解码的局限性,显著提高翻译的准确性。
2.1 框架概述
MetaSQL是一个用于自然语言到SQL翻译的生成然后排序框架,旨在提高现有NLIDB系统的翻译准确性。其核心思想是通过引入查询元数据来控制SQL查询候选的生成,并利用学习排序算法来检索全局优化的查询。MetaSQL框架主要包括三个步骤:语义分解、元数据条件生成和两阶段排名管道。
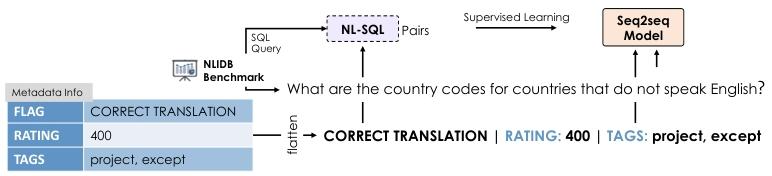
METASQL 中基于 Seq2seq 的模型的训练过程
2.2 语义分解
2.2.1 语义分解的概念
语义分解是MetaSQL框架的第一步,它将自然语言查询的语义映射到一组查询元数据。这些元数据包括操作标签、复杂度值和正确性指示器,能够捕捉自然语言查询的高层语义。
2.2.2 查询元数据的设计
◆ 操作标签:每个操作标签对应一个逻辑操作,如选择实体、检索属性信息或聚合实体信息。例如,对于一个涉及“项目”和“除外”操作的自然语言查询,相应的操作标签为“project”和“except”。
◆ 复杂度值:复杂度值用于量化查询的潜在复杂性。根据SQL查询中包含的SQL组件的数量和类型,为每个SQL组件分配一个难度分数,然后将这些分数相加得到查询的复杂度值。
◆ 正确性指示器:用于区分正确和错误的查询。在训练阶段,正确性指示器可以是“正确”或“错误”,以帮助模型学习如何避免错误的解析路径。
2.2.3 语义分解的实现
语义分解通过多标签分类模型实现。该模型将自然语言查询和数据库模式作为输入,输出一组相关的查询元数据。具体来说,模型使用编码器对自然语言查询和数据库模式进行联合编码,然后通过分类层计算不同类别值的可能性质量。
2.3 元数据条件生成
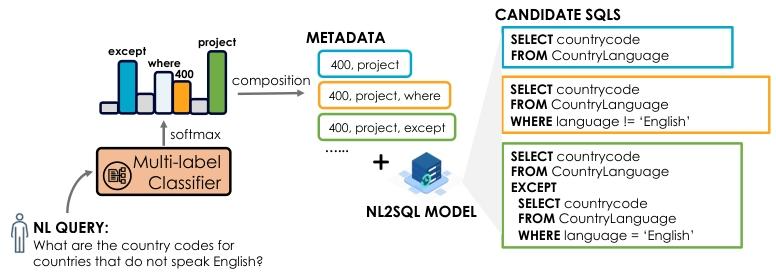
METASQL 中的元数据条件生成
2.3.1 元数据条件生成的概念
元数据条件生成步骤利用从语义分解步骤获得的元数据,通过调节翻译模型的行为,生成多样化的SQL查询候选。这一步骤通过将查询元数据作为语言提示,指导翻译模型生成SQL查询。
2.3.2 元数据的使用
在模型训练中,查询元数据作为前缀语言提示添加到自然语言查询中,遵循传统的序列到序列学习范式。元数据提供了额外的学习信号,减轻了模型解析复杂查询的负担。
2.3.3 条件生成过程
在推理阶段,由于查询元数据未知,MetaSQL使用多标签分类模型获得查询元数据,然后通过条件生成过程生成SQL查询候选。具体来说,MetaSQL通过组合不同的元数据标签,生成多样化的SQL查询候选。
2.4 两阶段排名管道
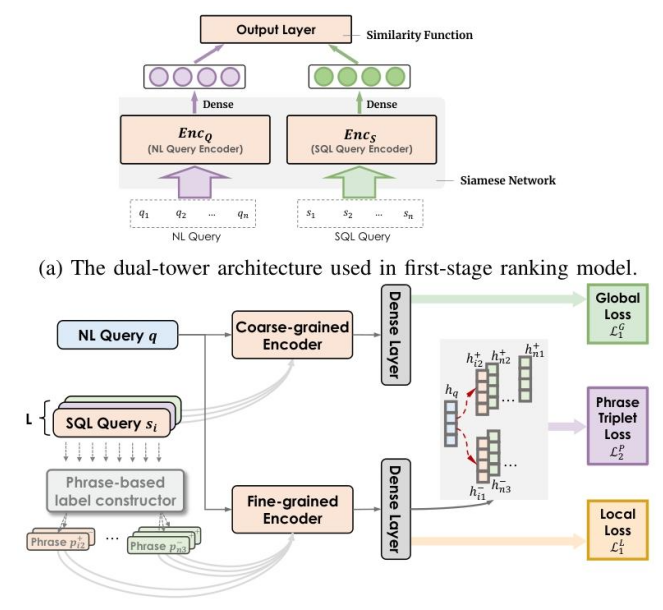
METASQL 中使用的两阶段排名模型
2.4.1 两阶段排名的概念
两阶段排名管道利用两个基于机器学习的排名模型,在自然语言和SQL两个模态上进行排名。第一阶段的粗粒度排名模型快速筛选出一组较小的候选SQL查询,第二阶段的细粒度排名模型则从第一阶段的结果中确定最终的顶级排名SQL查询。
2.4.2 第一阶段排名模型
第一阶段排名模型采用双塔架构,包括两个BERT类似的双向文本编码器(NL查询编码器和SQL查询编码器),并使用余弦函数作为相似性函数来衡量NL查询和SQL查询之间的语义相似性。
2.4.3 第二阶段排名模型
第二阶段排名模型旨在准确地从第一阶段的结果中找到与给定NL查询语义最匹配的SQL查询。该模型通过引入多粒度监督信号(包括句子级和短语级监督),更好地识别SQL查询中的不匹配部分。
3.1 实验设置
3.1.1 基准测试
实验在两个公共NLIDB基准测试上进行:SPIDER和SCIENCEBENCHMARK。
◆ SPIDER:一个大规模的跨领域基准测试,包含10,181个自然语言查询和5,693个独特的SQL查询,覆盖206个数据库和138个不同领域。SPIDER数据集根据SQL复杂度分为简单、中等、困难和额外困难四个级别。
◆ SCIENCEBENCHMARK:针对三个真实的科学数据库(OncoMx、Cordis和Sdss)的复杂基准测试。每个数据库包含103/100/100个高质量的NL-SQL对,通过GPT-3生成的合成数据进行扩展。
3.1.2 训练设置
◆ 多标签分类模型:基于LGESQL模型实现,使用其编码器替换为分类层,以输出查询元数据的标量值。
◆ 第一阶段排名模型:使用预训练的sentence-transformers STSB-MPNET-BASE-V2模型初始化嵌入层,采用Adam优化器,学习率为2e-5,批大小为8。
◆ 第二阶段排名模型:基于ROBERTA-LARGE,使用Adam优化器,学习率为1e-5,批大小为2。
3.1.3 推理设置
◆ 多标签分类模型:分类阈值设为0,选择所有可能的查询元数据标签。
◆ 第一阶段排名模型:选择排名前10的候选SQL查询传递给第二阶段排名模型。
3.1.4 评估指标
◆ 翻译准确率(EM):评估生成的SQL查询是否与“黄金”SQL匹配。
◆ 执行匹配(EX):通过在关系数据库上执行生成的SQL查询,评估其结果是否与真实结果匹配。
◆ 翻译精确率(Precision@K):评估NLIDB系统在前K个翻译结果中包含“黄金”SQL查询的比例。
◆ 翻译MRR(Mean Reciprocal Rank):评估NLIDB系统在响应每个NL查询时提供排名SQL查询列表的有效性。
3.2 实验结果
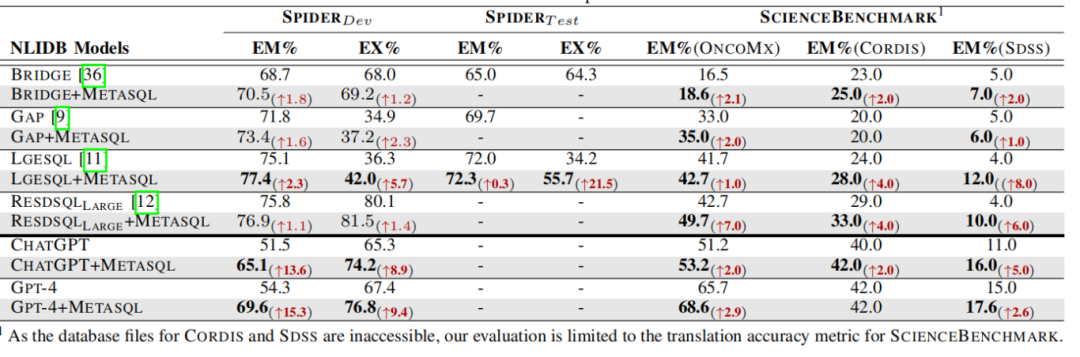
两个公共 NLIDB 基准测试的翻译结果
3.2.1 总体性能
MetaSQL在多个模型和基准测试上表现出色。在SPIDER基准测试中,应用MetaSQL的LGESQL模型在验证集上的翻译准确率达到77.4%,在测试集上达到72.3%,分别比基线模型提高了2.3%和0.3%。在SCIENCEBENCHMARK上,应用MetaSQL的GPT-4模型在三个科学数据库上的翻译准确率分别为68.6%、42.0%和17.6%。
3.2.2 模型对比
◆ Seq2seq模型:MetaSQL显著提高了BRIDGE、GAP、LGESQL和RESDSQLLARGE等模型的性能,特别是在SCIENCEBENCHMARK基准测试中,LGESQL在SDSS数据库上的性能提升了8.0%。
◆ 大型语言模型(LLMs):MetaSQL显著提升了CHATGPT和GPT-4的性能。例如,GPT-4在SPIDER验证集上的翻译准确率从54.3%提升到69.6%,执行准确率从67.4%提升到76.8%。
3.3 详细分析
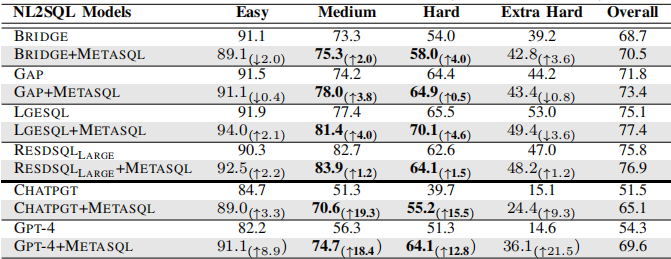
3.3.1 SQL难度级别的性能表现
在SPIDER基准测试中,所有模型的性能随着SQL查询难度的增加而下降。MetaSQL在“中等”和“困难”查询上表现出显著的改进。例如,LGESQL在“困难”查询上的性能从65.5%提升到70.1%,在“中等”查询上从77.4%提升到81.4%。
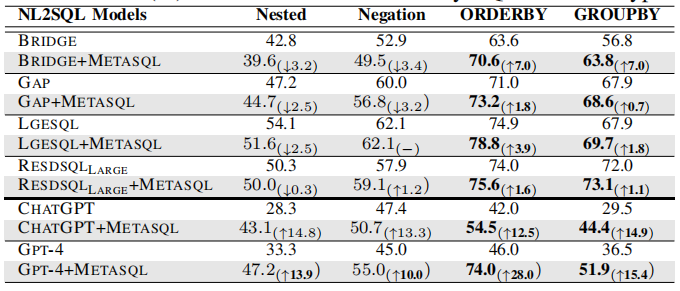
3.3.2 SQL语句类型的性能表现
MetaSQL在涉及ORDER BY和GROUP BY子句的查询翻译上表现出显著的提升。例如,LGESQL在GROUP BY子句上的性能从67.9%提升到69.7%,在ORDER BY子句上的性能从67.9%提升到69.7%。
3.3.3 排名管道的性能
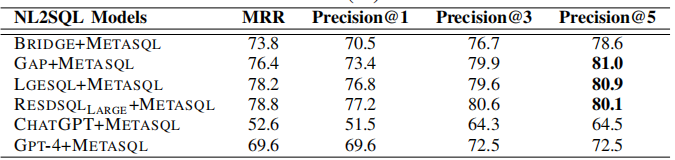
MetaSQL的排名管道在大多数情况下能够正确地在前几个返回的排名结果中选择目标SQL查询。例如,RESDSQLLARGE+METASQL在SPIDER验证集上的翻译MRR达到78.8%,表明其能够有效地从生成的候选查询中选择最符合自然语言查询语义的SQL查询。
3.4 失败案例分析
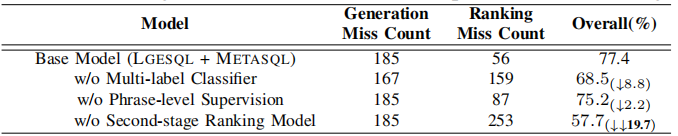
SPIDER 验证集的消融研究
3.4.1 自回归解码问题
尽管MetaSQL提供了准确的元数据,但底层翻译模型的自回归解码仍可能导致错误翻译。例如,在处理复杂查询时,模型可能无法生成正确的JOIN路径。
3.4.2 元数据不匹配问题
多标签分类器提取的元数据不准确可能导致翻译错误。例如,如果错误地提取了子查询元数据,模型可能生成不符合预期的SQL查询。
3.4.3 排名问题
即使“黄金”查询包含在候选查询中,MetaSQL的排名管道可能无法将其排在首位。这在涉及JOIN操作的查询中尤为常见,因为查询语义的抽象性增加了排名的难度。
4.1 自然语言接口到数据库的历史发展
自然语言接口到数据库(NLIDB)技术已有数十年的研究历史。早期的工作主要采用基于规则的方法,使用手工编写的语法规则将自然语言查询映射到特定数据库的SQL查询。这些方法在特定领域和简单查询上表现良好,但在处理复杂查询和跨领域应用时显得力不从心。
4.2 深度学习方法的兴起
随着深度学习技术的发展,基于机器学习的方法开始主导NLIDB领域。这些方法将NLIDB视为一个序列到序列(Seq2seq)的翻译任务,使用编码器-解码器架构来生成SQL查询。代表性的工作包括:
◆ SQLNet:通过神经网络模型生成结构化查询,无需强化学习。
◆ RAT-SQL:引入关系感知的模式编码和链接,用于跨领域上下文依赖问题的文本到SQL解析。
◆ GRAPPA:基于语法的预训练模型,用于表格语义解析。
这些方法在处理复杂查询时仍存在局限性,尤其是在生成多样性和全局上下文意识方面。
4.3 大型语言模型的应用
近期,大型语言模型(LLMs)在自然语言处理领域取得了巨大成功。相关工作开始探索将LLMs应用于NL2SQL任务:
◆ GPT-4:在NL2SQL任务中表现出色,能够生成高质量的SQL查询,但需要特定的提示工程。
◆ SQL-Palm:通过改进大型语言模型的适应性,提高文本到SQL的性能。
◆ DIN-SQL:通过自纠正的上下文学习方法,提高NL2SQL的能力。
这些研究表明,LLMs在NL2SQL任务中具有巨大的潜力,但仍然存在改进空间,特别是在生成多样性和复杂查询处理方面。
5.1 结论
MetaSQL通过引入查询元数据和两阶段排名管道,有效地提高了NL2SQL模型的翻译准确性。实验结果证明了MetaSQL在多个模型和基准测试上的有效性。
5.2 未来展望
未来的工作可以探索如何将生成然后排序的方法扩展到现有的自回归解码范式之外,以克服现有翻译模型解码过程中的局限性。此外,开发更精确的多粒度语义标记方法,特别是在复杂的查询排名过程中,对于进一步提高MetaSQL的性能至关重要。最后,探索将其他类型的元数据集成到MetaSQL中也是一个潜在的研究方向。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





