




https://www.cnblogs.com/vajoy/p/5471308.html
LevelDB 是由谷歌重量级工程师(Jeff Dean 和 Sanjay Ghemawat)开发的开源项目,它是能处理十亿级别规模 key-value 型数据持久性存储的程序库,开发语言是C++。
除了持久性存储,LevelDB 还有一个特点是 —— 写性能远高于读性能(当然读性能也不差)。
1.特点
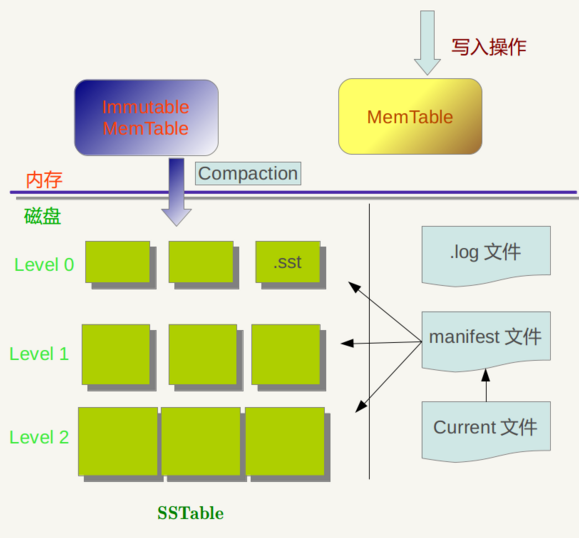
LevelDB 作为存储系统,数据记录的存储介质包括内存以及磁盘文件,当LevelDB运行了一段时间,此时我们给LevelDb进行透视拍照,那么您会看到如下一番景象:
(图1)
LevelDB 所写入的数据会先插入到内存的 Mem Table 中,再由 Mem Table 合并到只读且键值有序的 Disk Table(SSTable) 中,再由后台线程不时的对 Disk Table 进行归并。
内存中存在两个 Mem Table —— 一个是可以往里面写数据的table A,另一个是正在合并到硬盘的 table B。
Mem Table 用 skiplist 实现,写数据时,先写日志(.log),再往A插入,因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,所以这是为何说LevelDb写入速度极快的主要原因。如果当B还没完成合并,而A已经写满时,写操作必须等待。
DiskTable(SSTable,格式为.sst)是分层的(leveldb的名称起源),每一个大小不超过2M。最先 dump 到硬盘的 SSTable 的层级为0,层级为0的 SSTable 的键值范围可能有重叠。如果这样的 SSTable 太多,那么每次都需要从多个 SSTable 读取数据,所以LevelDB 会在适当的时候对 SSTable 进行 Compaction,使得新生成的 SSTable 的键值范围互不重叠。
进行对层级为 level 的 SSTable 做 Compaction 的时候,取出层级为 level+1 的且键值空间与之重叠的 Table,以顺序扫描的方式进行合并。level 为0的 SSTable 做 Compaction 有些特殊:会取出 level 0 所有重叠的Table与下一层做 Compaction,这样做保证了对于大于0的层级,每一层里 SSTable 的键值空间是互不重叠的。
SSTable 中的某个文件属于特定层级,而且其存储的记录是 key 有序的,那么必然有文件中的最小 key 和最大 key,这是非常重要的信息,LevelDB 应该记下这些信息 —— Manifest 就是干这个的,它记载了 SSTable 各个文件的管理信息,比如属于哪个Level,文件名称叫啥,最小 key 和最大 key 各自是多少。下图是 Manifest 所存储内容的示意:

图中只显示了两个文件(Manifest 会记载所有 SSTable 文件的这些信息),即 Level0 的 Test1.sst 和 Test2.sst 文件,同时记载了这些文件各自对应的 key 范围,比如 Test1.sstt 的 key 范围是“an”到 “banana”,而文件 Test2.sst 的 key 范围是“baby”到“samecity”,可以看出两者的 key 范围是有重叠的。
那么上方图1中的 Current 文件是干什么的呢?这个文件的内容只有一个信息,就是记载当前的 Manifest 文件名。因为在 LevleDB 的运行过程中,随着 Compaction 的进行,SSTable 文件会发生变化,会有新的文件产生,老的文件被废弃,Manifest 也会跟着反映这种变化,此时往往会新生成 Manifest 文件来记载这种变化,而 Current 则用来指出哪个 Manifest 文件才是我们关心的那个 Manifest 文件。
注意,鉴于 LevelDB 不属于分布式数据库,故CAP法则在此处不适用。

2. Node下的使用
Node 下可以使用 LevelUP 来操作 LevelDB 数据库:

var levelup = require('levelup')
// 1) Create our database, supply location and options.
// This will create or open the underlying LevelDB store.
var db = levelup('./mydb')
// 2) put a key & value
db.put('name', 'LevelUP', function (err) {
if (err) return console.log('Ooops!', err) // some kind of I/O error
// 3) fetch by key
db.get('name', function (err, value) {
if (err) return console.log('Ooops!', err) // likely the key was not found
// ta da!
console.log('name=' + value)
})
})
LevelUp 的API非常简洁实用,具体可参考官方文档。

3. 优缺点
优势
1. 操作接口简单,基本操作包括写记录,读记录和删除记录,也支持针对多条操作的原子批量操作;
2. 写入性能远强于读取性能,
3. 数据量增大后,读写性能下降趋平缓。
缺点
1. 随机读性能一般;
2. 对分布式事务的支持还不成熟。而且机器资源浪费率高。
适应场景
适用于对写入需求远大于读取需求的场景(大部分场景其实都是这样)。
