前言
大数据使用的OGG版本原先叫ogg for bigdata,到了23ai之后,名字叫GoldenGate for Distributed Applications and Analytics 23ai,简称叫OGG for DAA。
这里将演示如何将Oracle的数据同步到Hadoop HDFS里面。
环境规划
本次实验采用5台机器,其中2台机器安装OGG,3台机器配置成Hadoop集群。
主机名 | IP | 操作系统 | 软件版本 |
ogg-bigdata00 | 172.16.1.19 | Oracle Linux 8.10 | oracle 19.26/ OGG for Oracle 23.7.1.25.0.2 |
ogg- bigdata01 | 172.16.1.20 | Oracle Linux 8.10 | Zookeeper 3.8.4/Hadoop 3.4 |
ogg- bigdata02 | 172.16.1.21 | Oracle Linux 8.10 | Zookeeper 3.8.4/Hadoop 3.4 |
ogg- bigdata03 | 172.16.1.22 | Oracle Linux 8.10 | Zookeeper 3.8.4/Hadoop 3.4 |
ogg- bigdata04 | 172.16.1.23 | Oracle Linux 8.10 | OGG for DAA 23.6/Hadoop 3.4 |
Oracle 19.26采用多租户特性,PDB1作为源端,Hadoop作为目标端,数据写入到HDFS。安装OGG for DAA的机器上也安装Hadoop客户端,远程写入。
配置Oracle
Oracle的配置跟前面几篇文档一样,这里就不写了。可以参考之前的文章。
配置Hadoop服务端
默认情况下使用root用户,在每个机器上分别执行
安装JDK
rpm -ivh jdk-8u441-linux-x64.rpm创建用户
Hadoop用hadoop用户配置
useradd hadoop
passwd hadoop
mkdir /bigdata
chown hadoop:/bigdata配置hadoop用户等价性和sudo
配置zookeeper
解压缩zookeeper
将apache-zookeeper-3.8.4-bin.tar.gz上传到/bigdata目录里
cd /bigdata
tar zxvf apache-zookeeper-3.8.4-bin.tar.gz
mv apache-zookeeper-3.8.4-bin zookeeper
mkdir -p /bigdata/zookeeper/{data,logs}
chown -R zookeeper: /bigdata/zookeeper配置zookeeper profile
cat > /etc/profile.d/zookeeper.sh <<'EOF'
export ZOOKEEPER_HOME=/bigdata/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
EOF配置zookeeper配置文件
cd /bigdata/zookeeper
cp /bigdata/zookeeper/conf/{zoo_sample.cfg,zoo.cfg}
cat > /bigdata/zookeeper/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/bigdata/zookeeper/data
dataLogDir=/bigdata/zookeeper/logs
clientPort=2181
server.1=ogg-bigdata01:2888:3888
server.2=ogg-bigdata02:2888:3888
server.3=ogg-bigdata03:2888:3888
EOF
chown zookeeper: conf/zoo.cfg为每个机器设置myid
ogg-bigdata01
echo '1' >/bigdata/zookeeper/data/myid
ogg-bigdata01
echo '2' >/bigdata/zookeeper/data/myid
ogg-bigdata01
echo '3' >/bigdata/zookeeper/data/myid所有节点
chown zookeeper: /bigdata/zookeeper/data/myid配置zookeeper服务
cat > /usr/lib/systemd/system/zookeeper.service << EOF
[Unit]
Description=Zookeeper Service
[Service]
Type=simple
WorkingDirectory=/bigdata/zookeeper/
PIDFile=/bigdata/zookeeper/data/zookeeper_server.pid
SyslogIdentifier=zookeeper
User=zookeeper
Group=zookeeper
ExecStart=/bigdata/zookeeper/bin/zkServer.sh start
ExecStop=/bigdata/zookeeper/bin/zkServer.sh stop
Restart=always
TimeoutSec=20
SuccessExitStatus=130 143
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF启动zookeeper服务
systemctl enable --now zookeeper查看zookeeper服务状态
zkServer.sh status配置hadoop
本节内容默认使用hadoop用户执行
解压缩hadoop
cd /bigdata
tar zxvf hadoop-3.4.0.tar.gz
mv hadoop-3.4.0 hadoop
chown oracle: hadoop配置hadoop profile
cat >/etc/profile.d/hadoop.sh<<'EOF'
export HADOOP_HOME=/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
EOF
source /etc/profile配置hadoop参数
hadoop-env.sh
cat >> /bigdata/hadoop/etc/hadoop/hadoop-env.sh <<'EOF'
export HDFS_DATANODE_SECURE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_ZKFC_USER=hadoop
export HDFS_JOURNALNODE_USER=hadoop
export JAVA_HOME=/usr/java/latest
export HADOOP_SHELL_EXECNAME=hadoop
export HADOOP_PID_DIR=$HADOOP_HOME/tmp/pids
EOFyarn-env.sh
cat >> /bigdata/hadoop/etc/hadoop/yarn-env.sh <<EOF
export YARN_REGISTRYDNS_SECURE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
EOFcore-site.xml
cat > /bigdata/hadoop/etc/hadoop/core-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://moon</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>ogg-bigdata01:2181,ogg-bigdata02:2181,ogg-bigdata03:2181</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
EOFhdfs-site.xml
cat > /bigdata/hadoop/etc/hadoop/hdfs-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>moon</value>
</property>
<property>
<name>dfs.ha.namenodes.moon</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.moon.nn1</name>
<value>ogg-bigdata01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.moon.nn2</name>moon
<value>ogg-bigdata02:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.moon.nn3</name>
<value>ogg-bigdata03:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.moon.nn1</name>
<value>ogg-bigdata01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.moon.nn2</name>
<value>ogg-bigdata02:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.moon.nn3</name>
<value>ogg-bigdata03:9870</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ogg-bigdata01:8485;ogg-bigdata02:8485;ogg-bigdata03:8485/moon</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/bigdata/hadoop/tmp/dfs/journal</value>
</property>
<property>
` <name>dfs.client.failover.proxy.provider.moon</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
` <value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
EOFmapred-site.xml
cat > /bigdata/hadoop/etc/hadoop/mapred-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
EOFyarn-site.xml
cat > /bigdata/hadoop/etc/hadoop/yarn-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
` <value>moon</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ogg-bigdata01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
` <value>ogg-bigdata02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>ogg-bigdata03</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>ogg-bigdata01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>ogg-bigdata02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>ogg-bigdata03:8088</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>ogg-bigdata01:2181,ogg-bigdata02:2181,ogg-bigdata03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
EOFworkers
cat > /bigdata/hadoop/etc/hadoop/workers <<EOF
ogg-bigdata01
ogg-bigdata02
ogg-bigdata03
EOF初始化hadoop
格式化zookeeper
在zookeeper主节点上格式化
hdfs zkfc -formatZK每个节点启动journalnode
hdfs --daemon start journalnode主节点格式化hdfs
hdfs namenode -format主节点启动namenode
hdfs --daemon start namenode其他节点同步namenode
hdfs namenode -bootstrapStandby其他节点启动namenode
hdfs --daemon start namenode停止hadoop
stop-all.sh启动hadoop
start-dfs.sh
start-yarn.sh或者使用
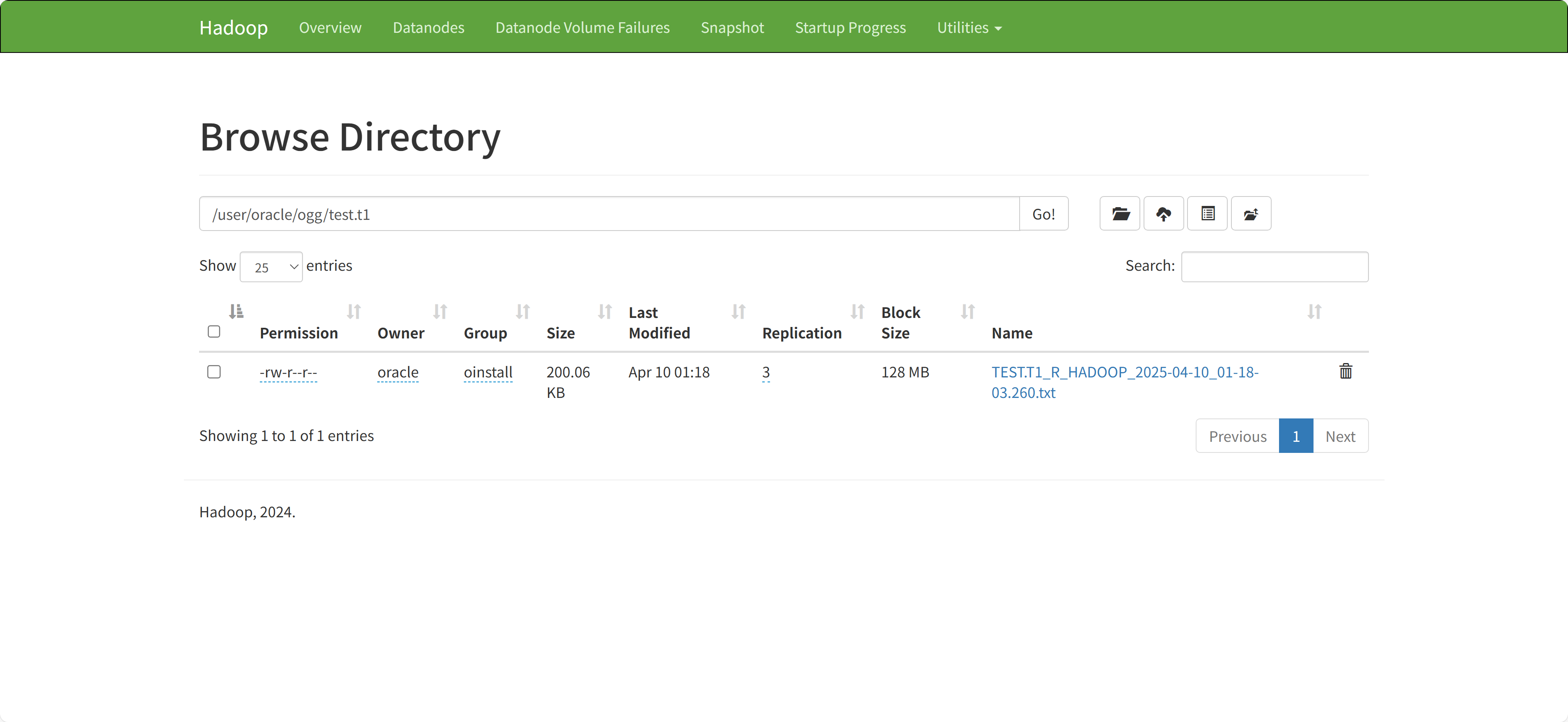
start-all.sh使用http://ogg-bigdata01:9870访问hadoop,单个节点只有一个是读写状态,登录对应节点就行。
创建hdfs目录
在hdfs上面为ogg建了相关目录
hdfs dfs -chmod -R 755 /
hdfs dfs -mkdir -p /user/oracle/ogg
hdfs dfs -chown -R oracle:oinstall /user配置hadoop客户端
在ogg-bigdata04上面配置hadoop客户端,远程连接hadoop。
安装JDK
rpm -ivh jdk-8u441-linux-x64.rpm配置hadoop
解压缩hadoop
cd /bigdata
tar zxvf hadoop-3.4.0.tar.gz
mv hadoop-3.4.0 hadoop
chown oracle: hadoop配置hadoop profile
cat >/etc/profile.d/hadoop.sh<<'EOF'
export HADOOP_HOME=/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
EOF
source /etc/profile配置hadoop参数
hadoop-env.sh
cat >> /bigdata/hadoop/etc/hadoop/hadoop-env.sh <<'EOF'
export HDFS_DATANODE_SECURE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_ZKFC_USER=hadoop
export HDFS_JOURNALNODE_USER=hadoop
export JAVA_HOME=/usr/java/latest
export HADOOP_SHELL_EXECNAME=hadoop
export HADOOP_PID_DIR=$HADOOP_HOME/tmp/pids
EOFyarn-env.sh
cat >> /bigdata/hadoop/etc/hadoop/yarn-env.sh <<EOF
export YARN_REGISTRYDNS_SECURE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
EOFcore-site.xml
cat > /bigdata/hadoop/etc/hadoop/core-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://moon</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
EOFhdfs-site.xml
cat > /bigdata/hadoop/etc/hadoop/hdfs-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>moon</value>
</property>
<property>
<name>dfs.ha.namenodes.moon</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.moon.nn1</name>
<value>ogg-bigdata01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.moon.nn2</name>moon
<value>ogg-bigdata02:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.moon.nn3</name>
<value>ogg-bigdata03:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.moon.nn1</name>
<value>ogg-bigdata01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.moon.nn2</name>
<value>ogg-bigdata02:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.moon.nn3</name>
<value>ogg-bigdata03:9870</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ogg-bigdata01:8485;ogg-bigdata02:8485;ogg-bigdata03:8485/moon</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/bigdata/hadoop/tmp/dfs/journal</value>
</property>
<property>
` <name>dfs.client.failover.proxy.provider.moon</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
` <value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
EOFmapred-site.xml
cat > /bigdata/hadoop/etc/hadoop/mapred-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
EOFyarn-site.xml
cat > /bigdata/hadoop/etc/hadoop/yarn-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>moon</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ogg-bigdata01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ogg-bigdata02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>ogg-bigdata03</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>ogg-bigdata01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>ogg-bigdata02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>ogg-bigdata03:8088</value>
</property>
</configuration>
EOF安装OGG for DAA
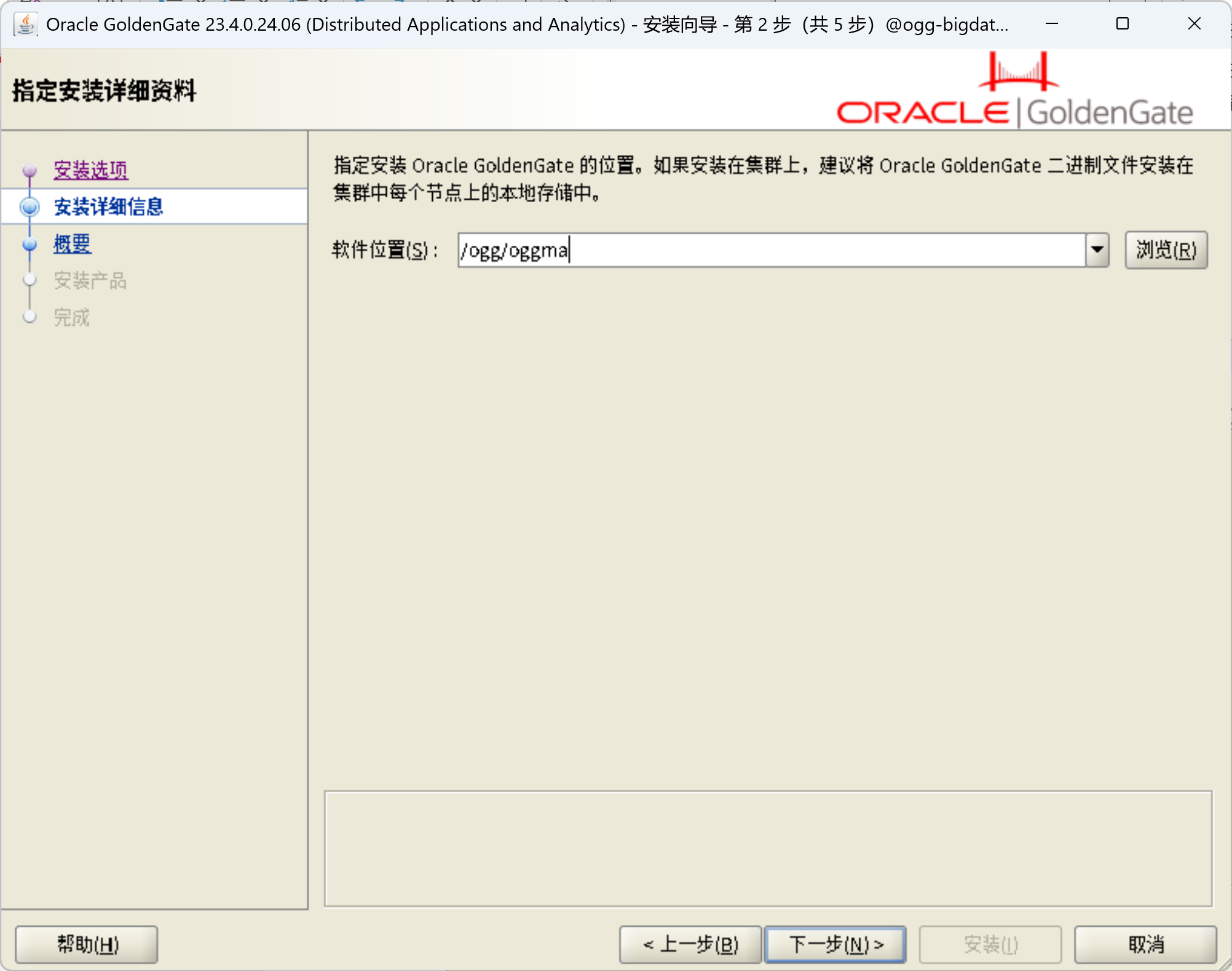
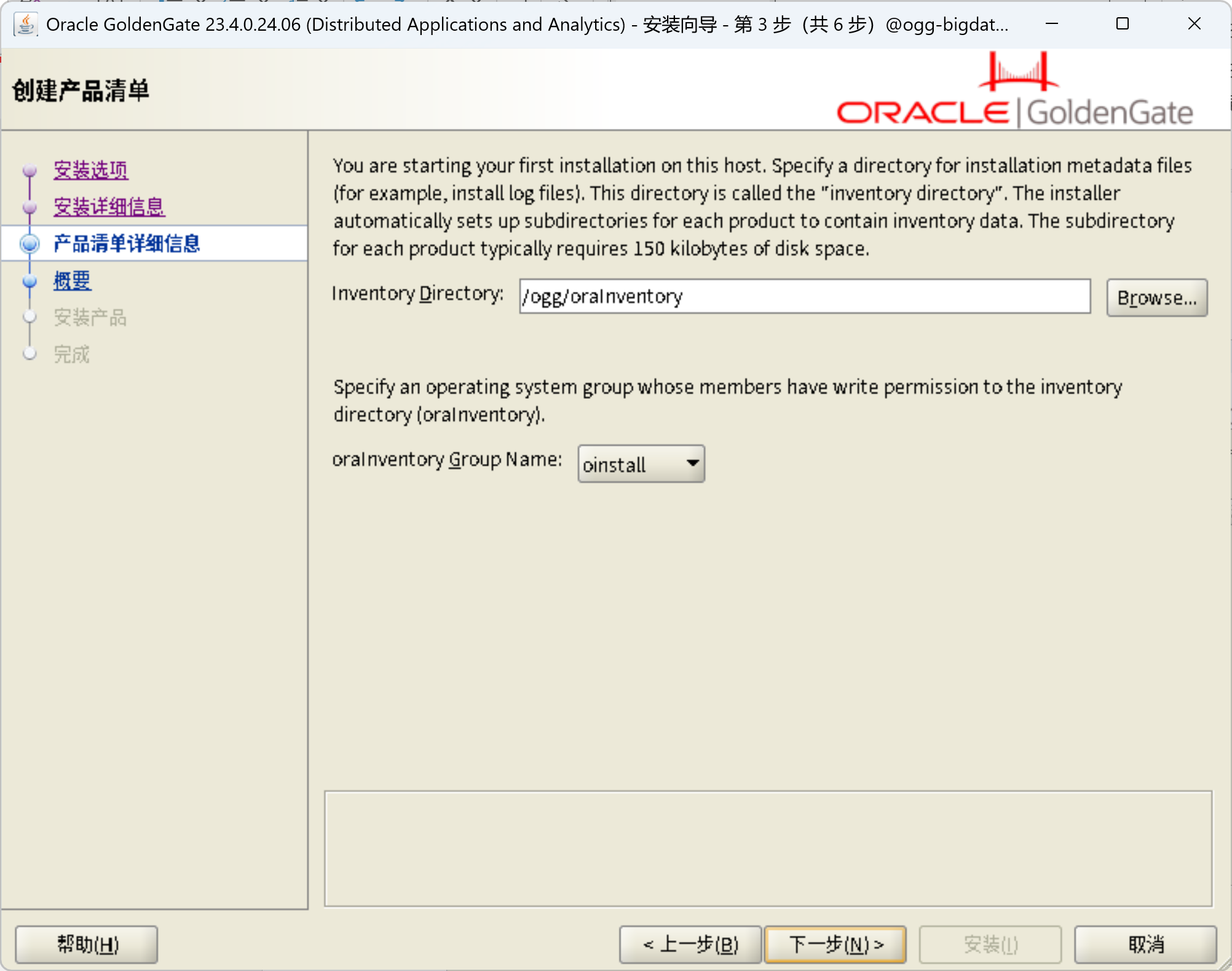
安装OGG for DAA 23.4
在ogg-bigdata04上面安装OGG for DAA
unzip ggs_Linux_x64_BigData_services_shiphome.zip
cd ggs_Linux_x64_BigData_services_shiphome/Disk1
./runInstaller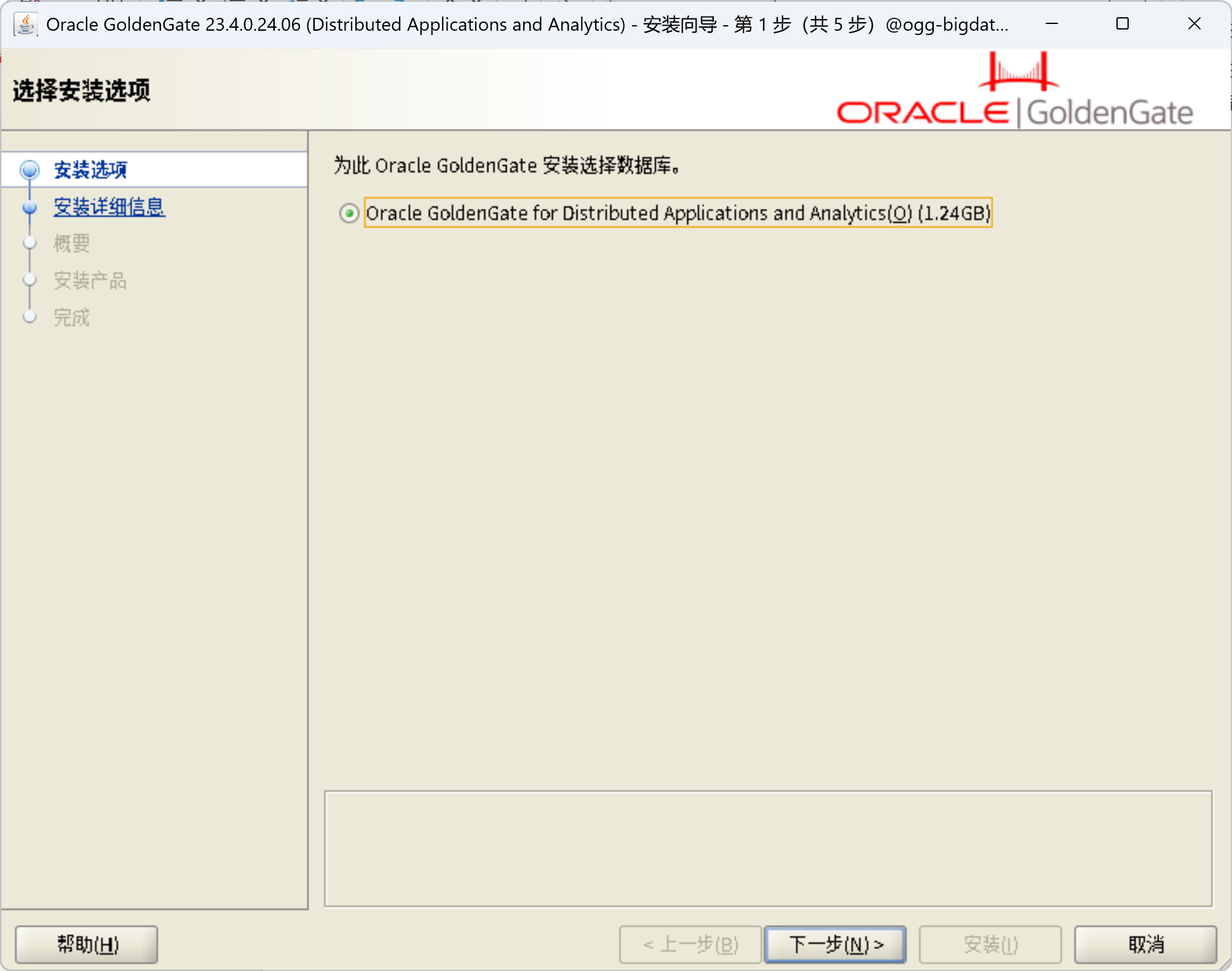
安装OGG for DAA 23.7补丁
安装补丁之前需要先替换OPatch
cd /ogg/oggma
rm -rf OPatch将OPatch文件复制到oggma安装目录然后解压缩
unzip p6880880_190000_Linux-x86-64.zip解压缩OGG for DAA 23.7补丁
unzip DAA_237000_Linux-x86-64.zip
cd 37482154
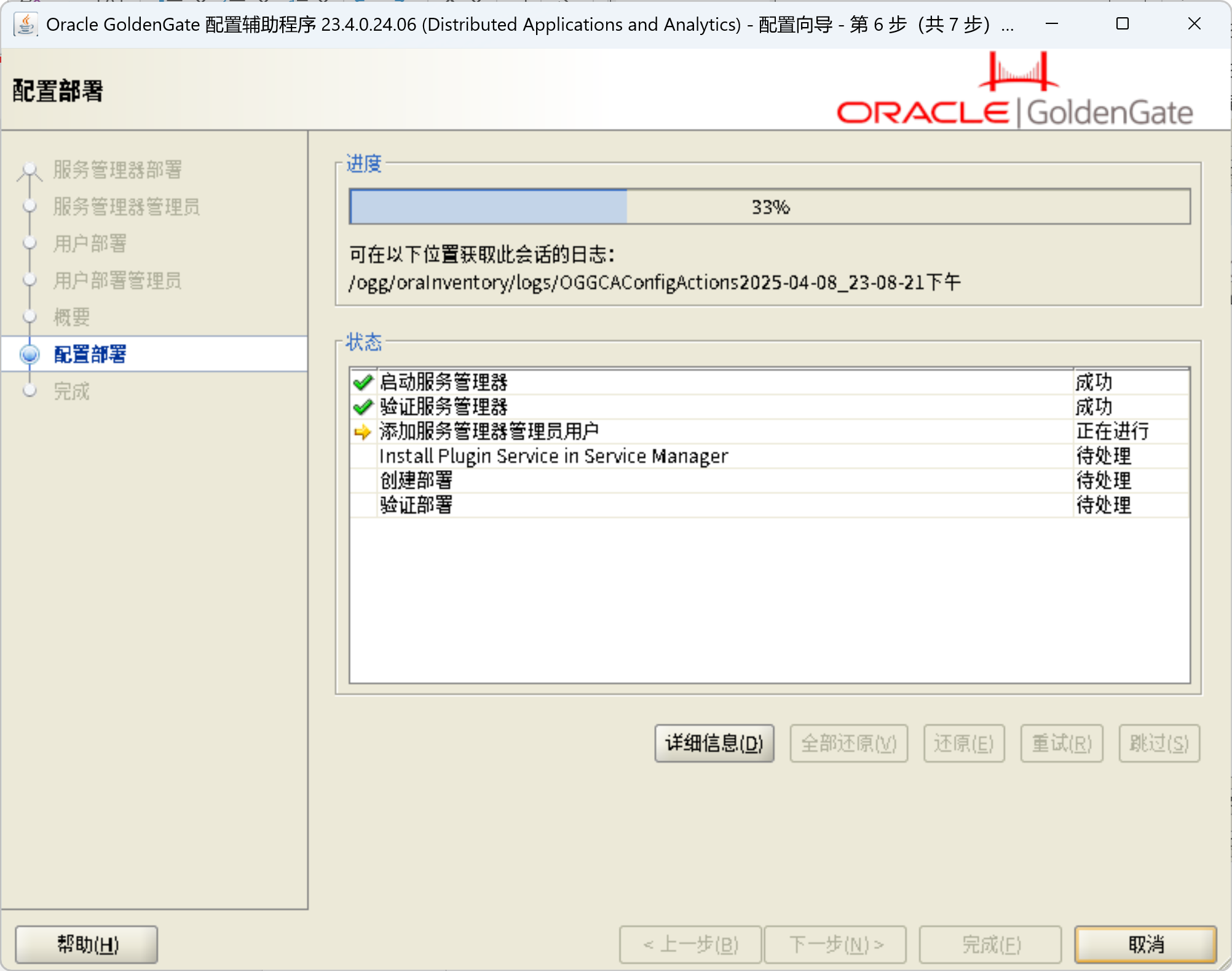
/ogg/oggma/OPatch/opatch apply -silent创建OGG部署
/ogg/oggma/bin/oggca.sh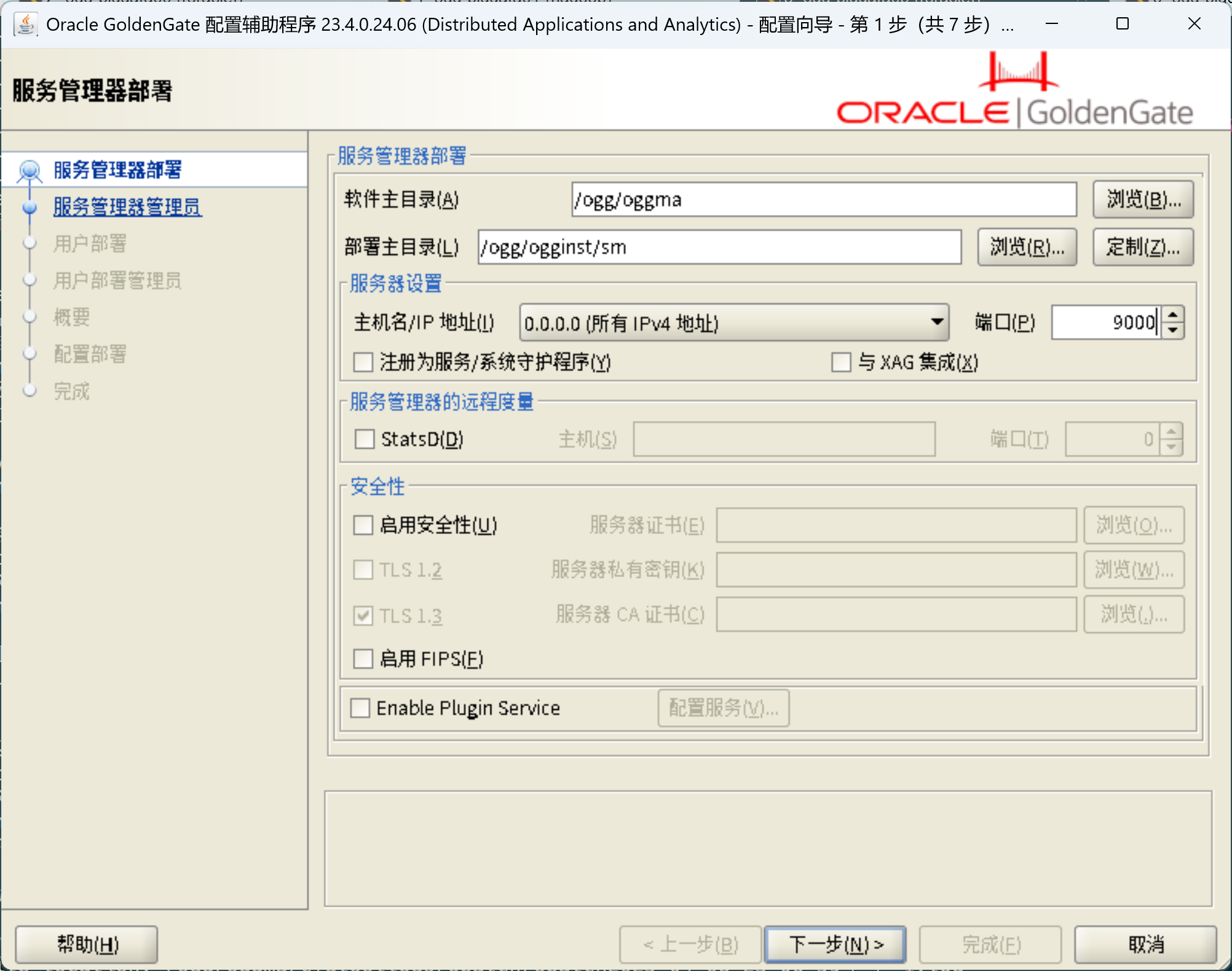
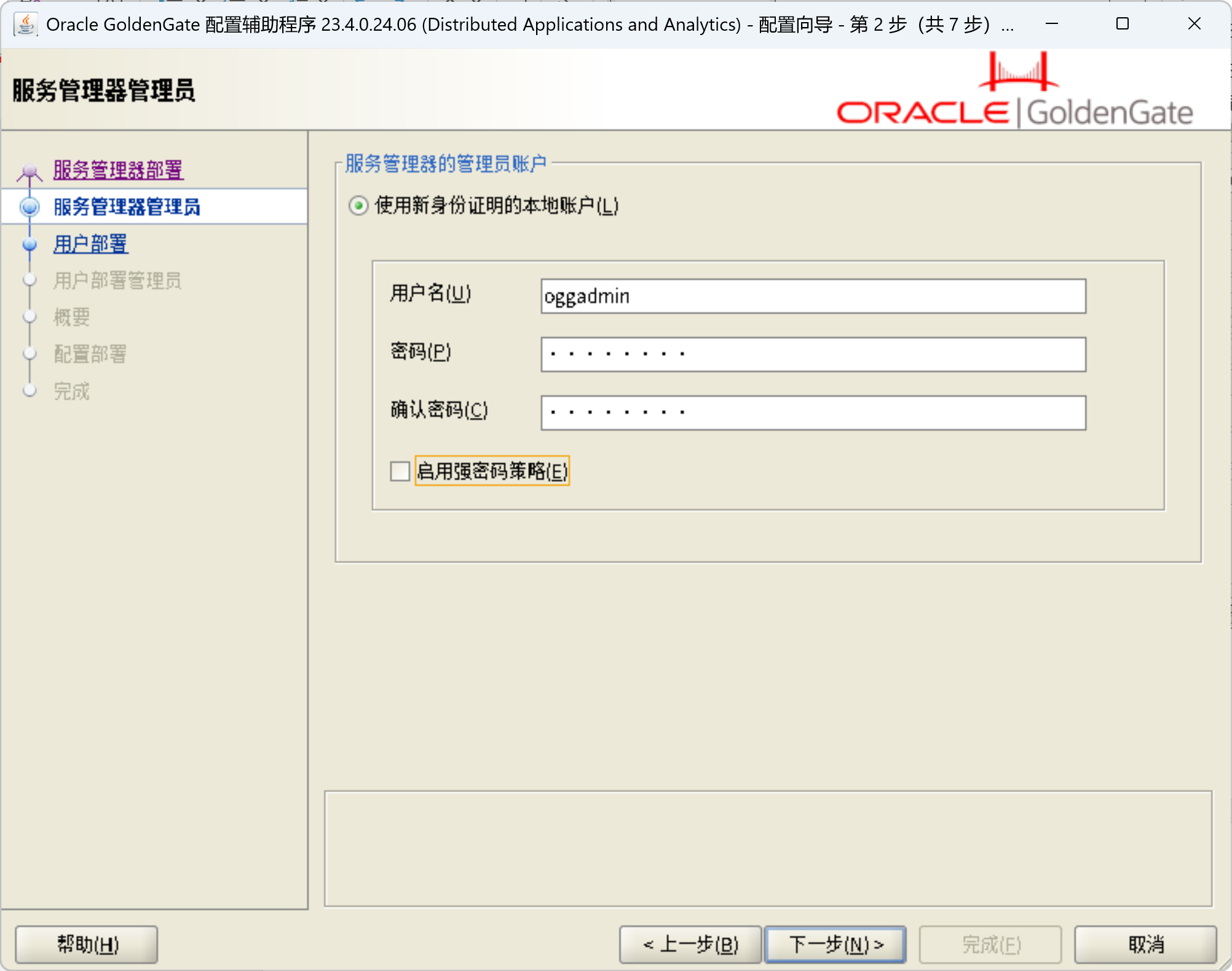
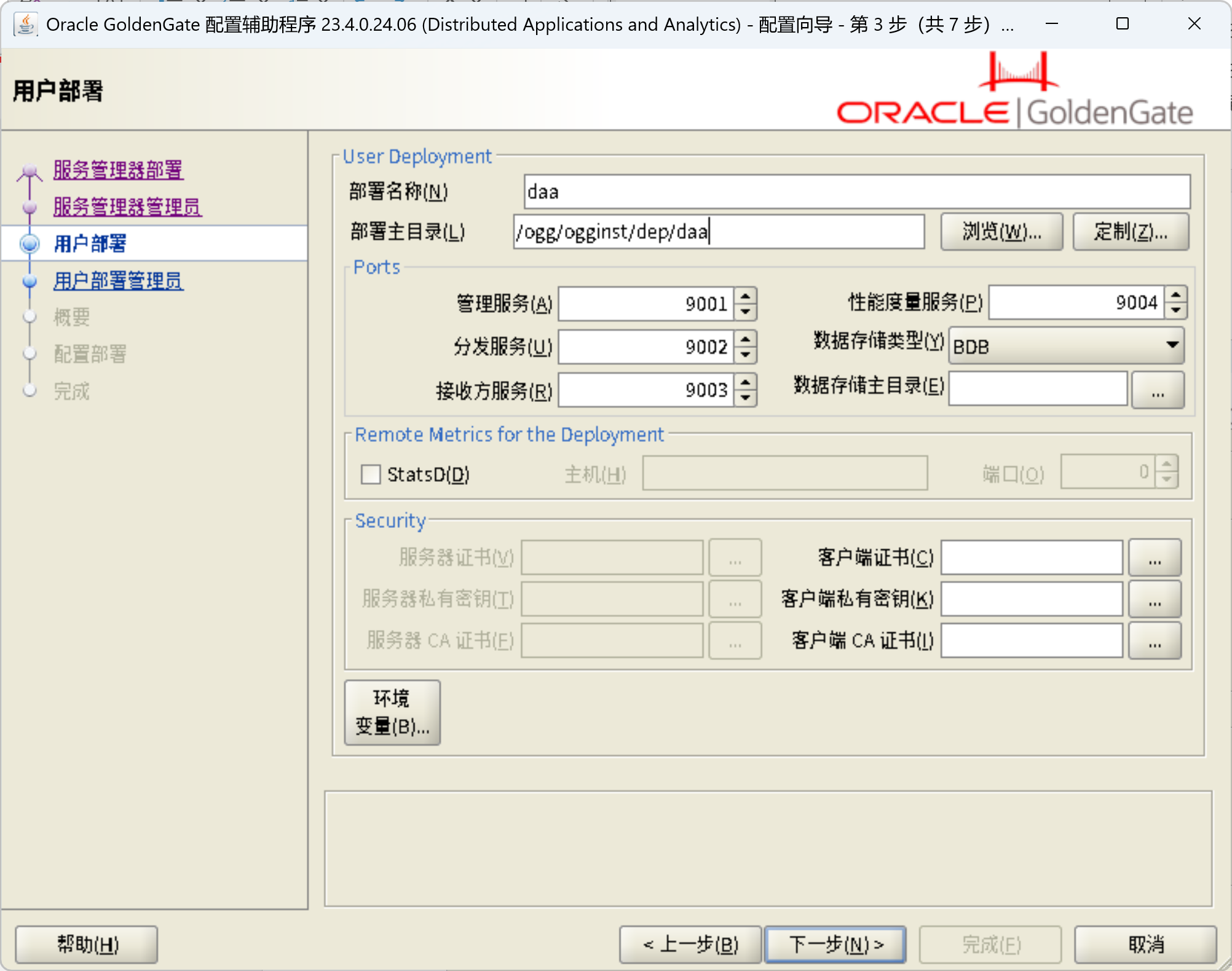
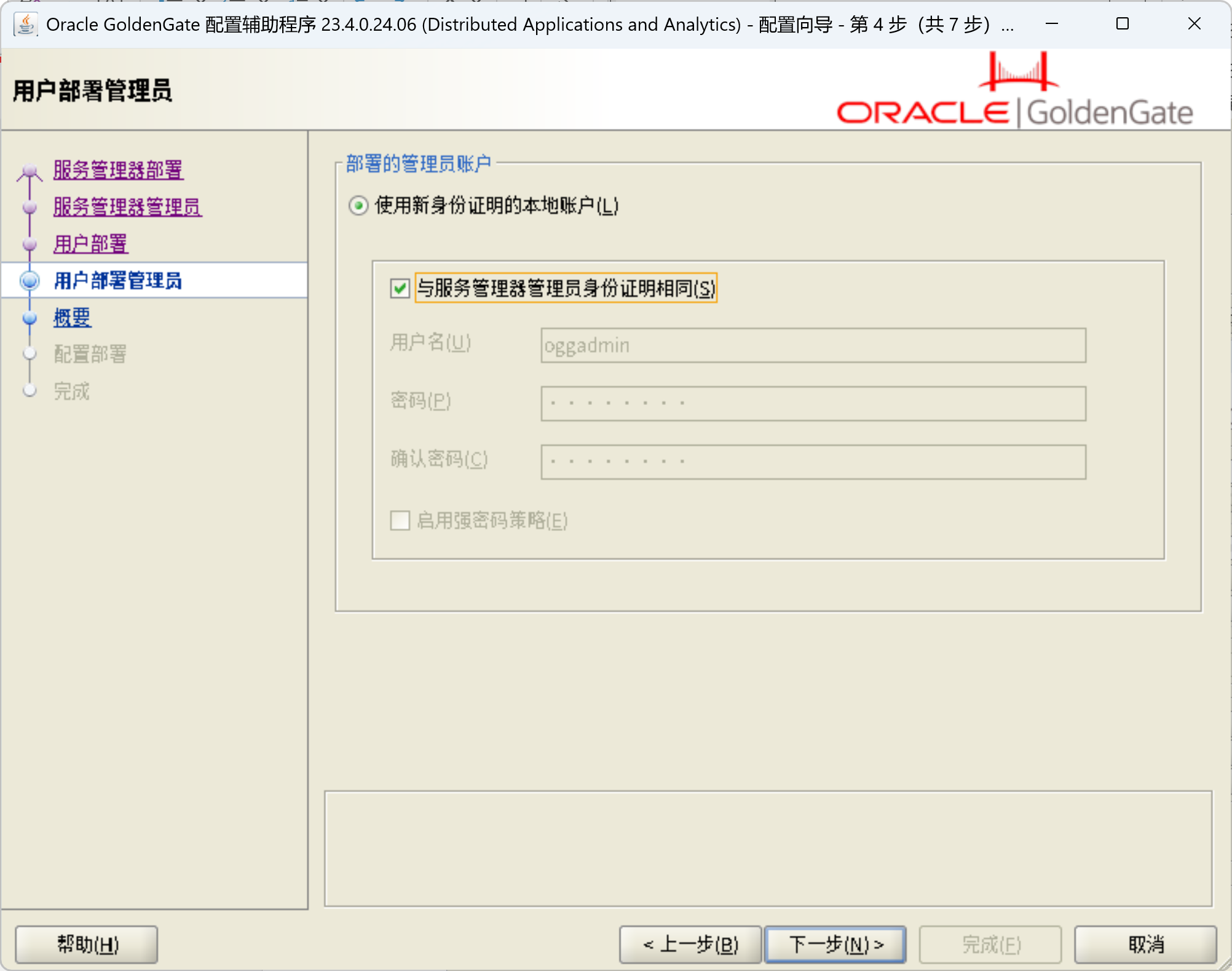
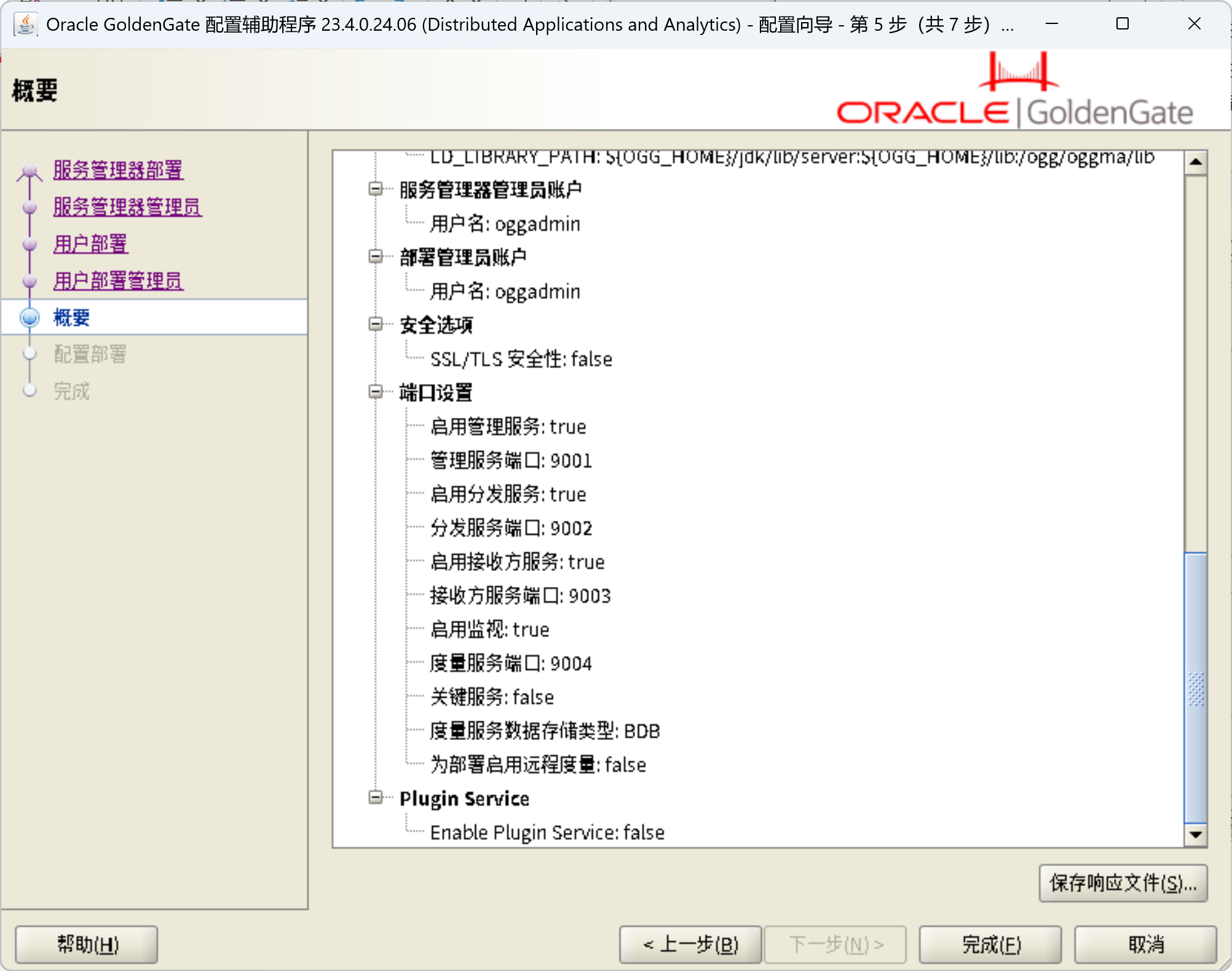
配置OGG复制进程
抽取进程和分发服务使用按照之前文档配置就行。这里描述一下目标端的配置。

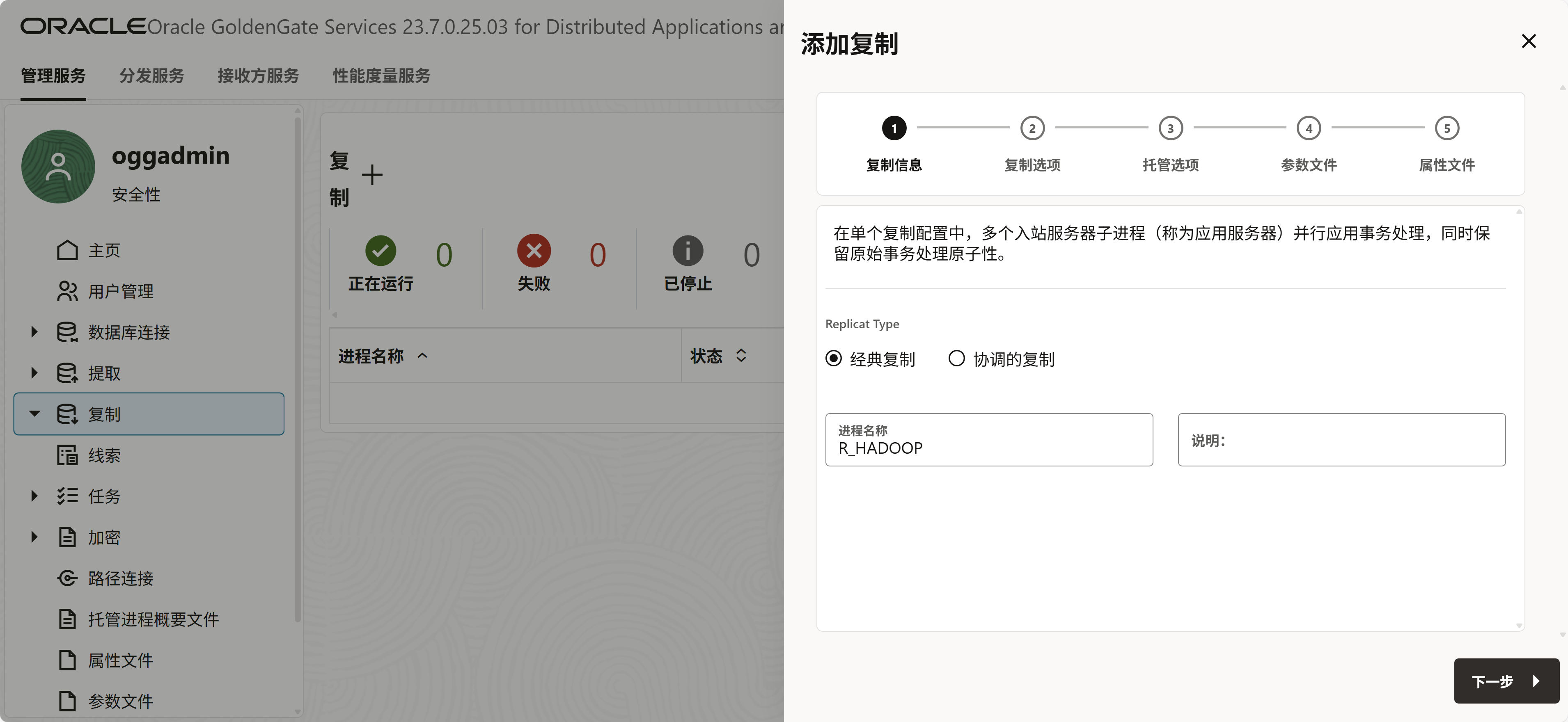
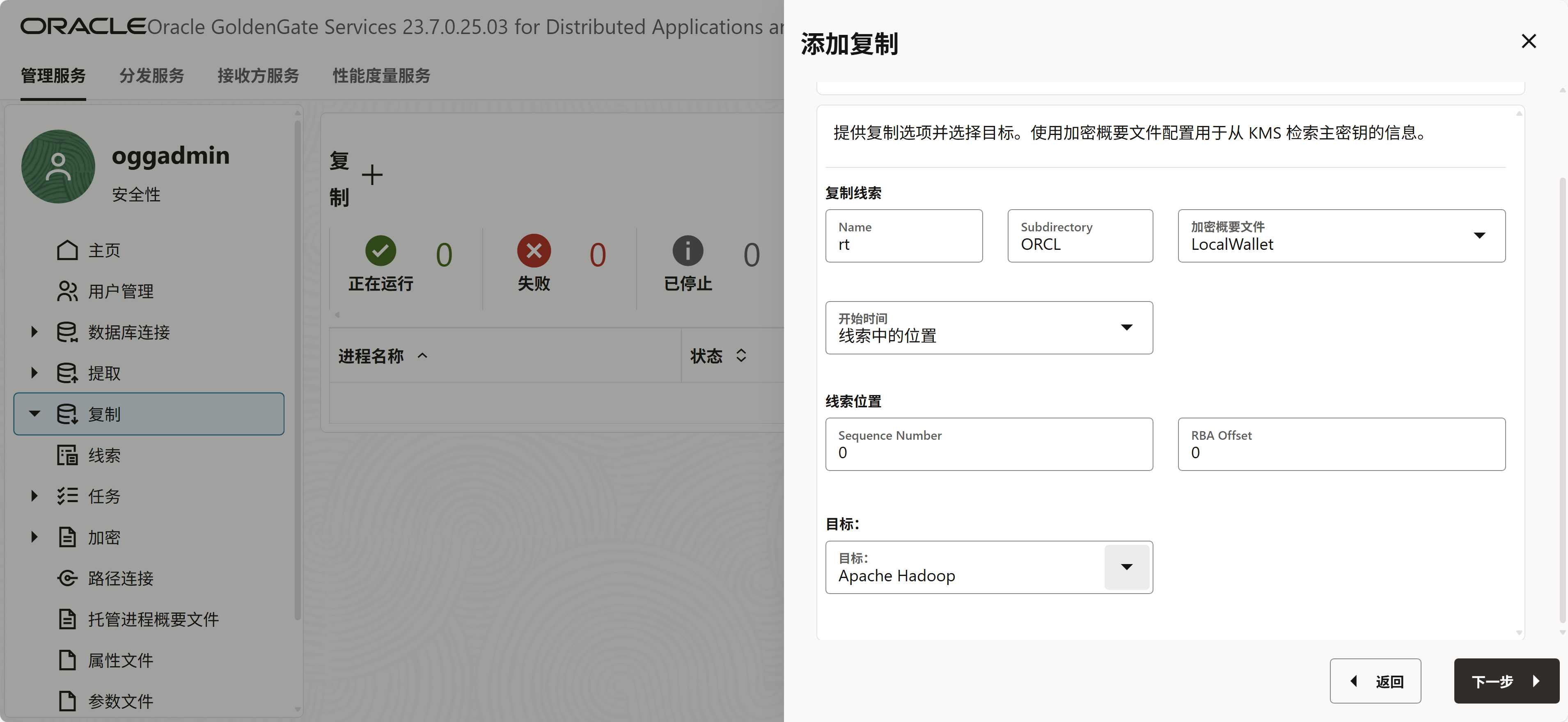
21c的时候需要选择HDFS,23ai改成了apache Hadoop
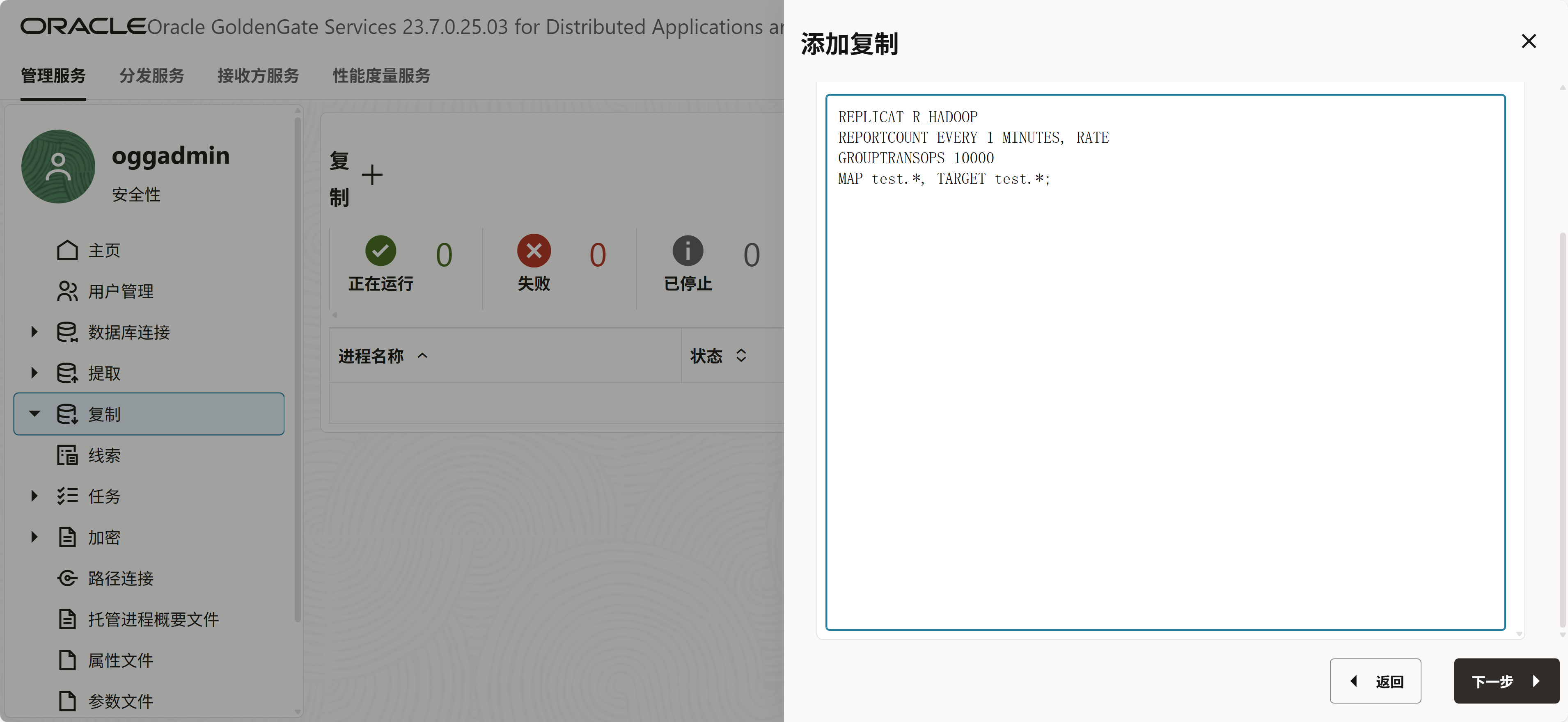
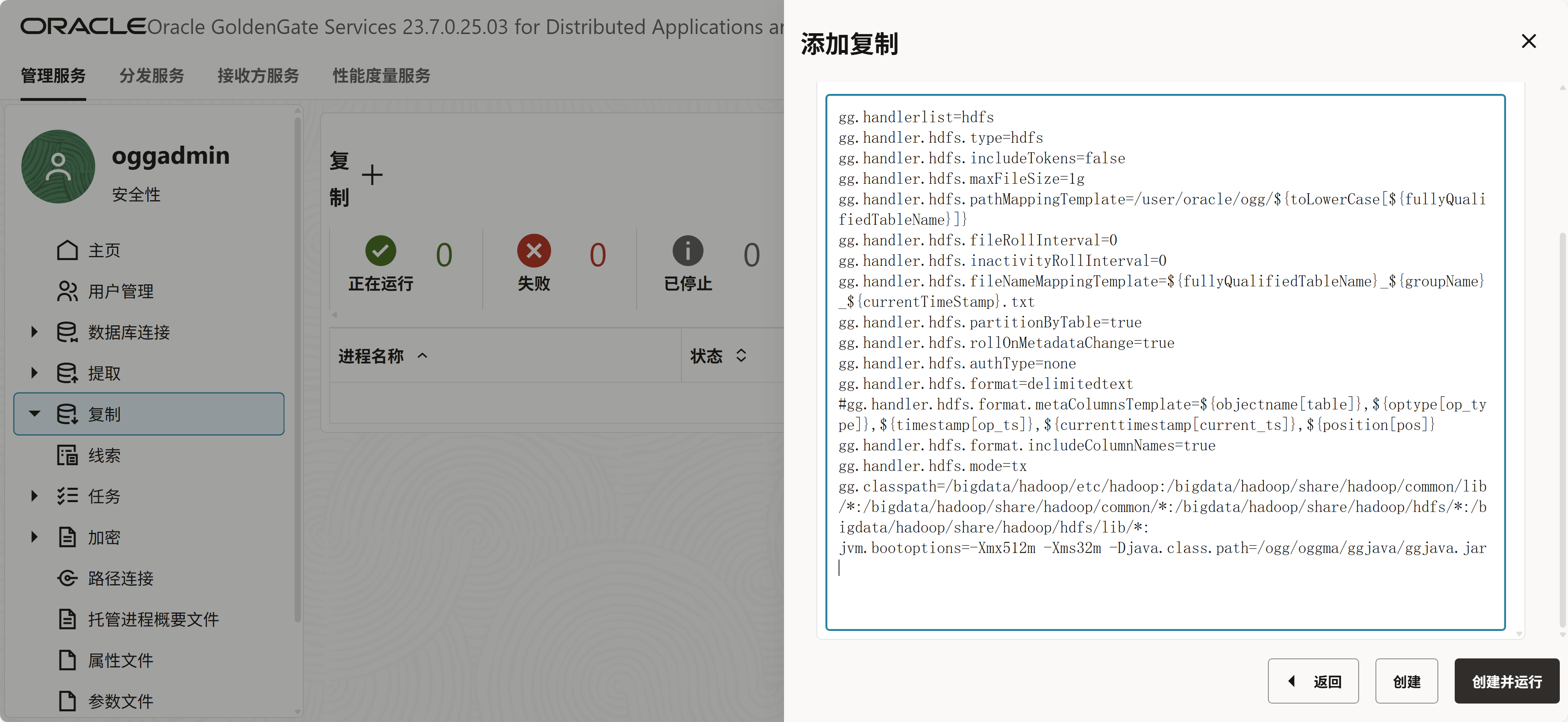
gg.handlerlist=hdfs
gg.handler.hdfs.type=hdfs
gg.handler.hdfs.includeTokens=false
gg.handler.hdfs.maxFileSize=1g
gg.handler.hdfs.pathMappingTemplate=/user/oracle/ogg/${toLowerCase[${fullyQualifiedTableName}]}
gg.handler.hdfs.fileRollInterval=0
gg.handler.hdfs.inactivityRollInterval=0
gg.handler.hdfs.fileNameMappingTemplate=${fullyQualifiedTableName}_${groupName}_${currentTimeStamp}.txt
gg.handler.hdfs.partitionByTable=true
gg.handler.hdfs.rollOnMetadataChange=true
gg.handler.hdfs.authType=none
gg.handler.hdfs.format=delimitedtext
#gg.handler.hdfs.format.metaColumnsTemplate=${objectname[table]},${optype[op_type]},${timestamp[op_ts]},${currenttimestamp[current_ts]},${position[pos]}
gg.handler.hdfs.format.includeColumnNames=true
gg.handler.hdfs.mode=tx
gg.classpath=/bigdata/hadoop/etc/hadoop:/bigdata/hadoop/share/hadoop/common/lib/*:/bigdata/hadoop/share/hadoop/common/*:/bigdata/hadoop/share/hadoop/hdfs/*:/bigdata/hadoop/share/hadoop/hdfs/lib/*:
jvm.bootoptions=-Xmx512m -Xms32m -Djava.class.path=/ogg/oggma/ggjava/ggjava.jar最重要的两个参数
gg.handler.hdfs.pathMappingTemplate生成的文件路径的模板,这里最后路径是/user/oracle/ogg/test.t1
gg.handler.hdfs.fileNameMappingTemplate生成的文件名的模板
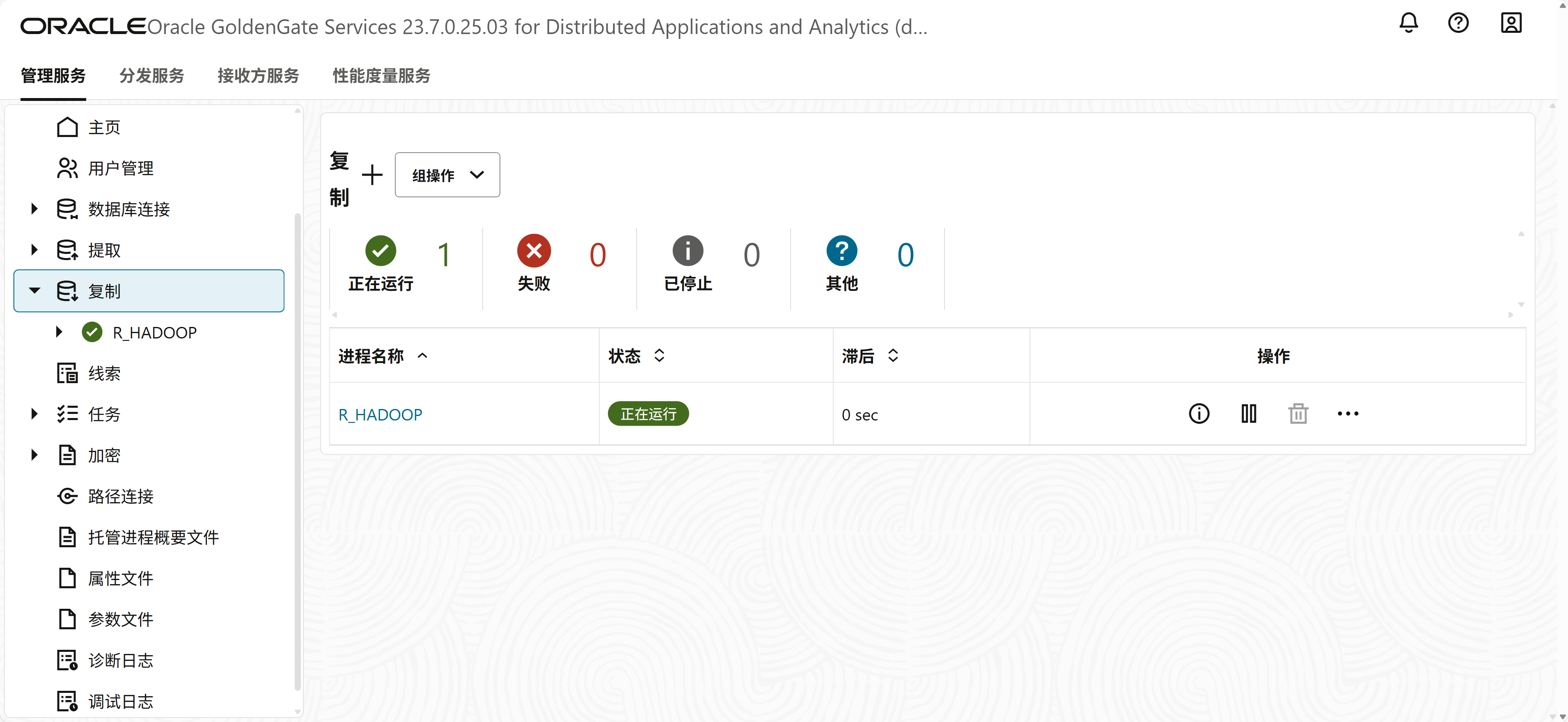
在源端生成测试数据,查看同步结果
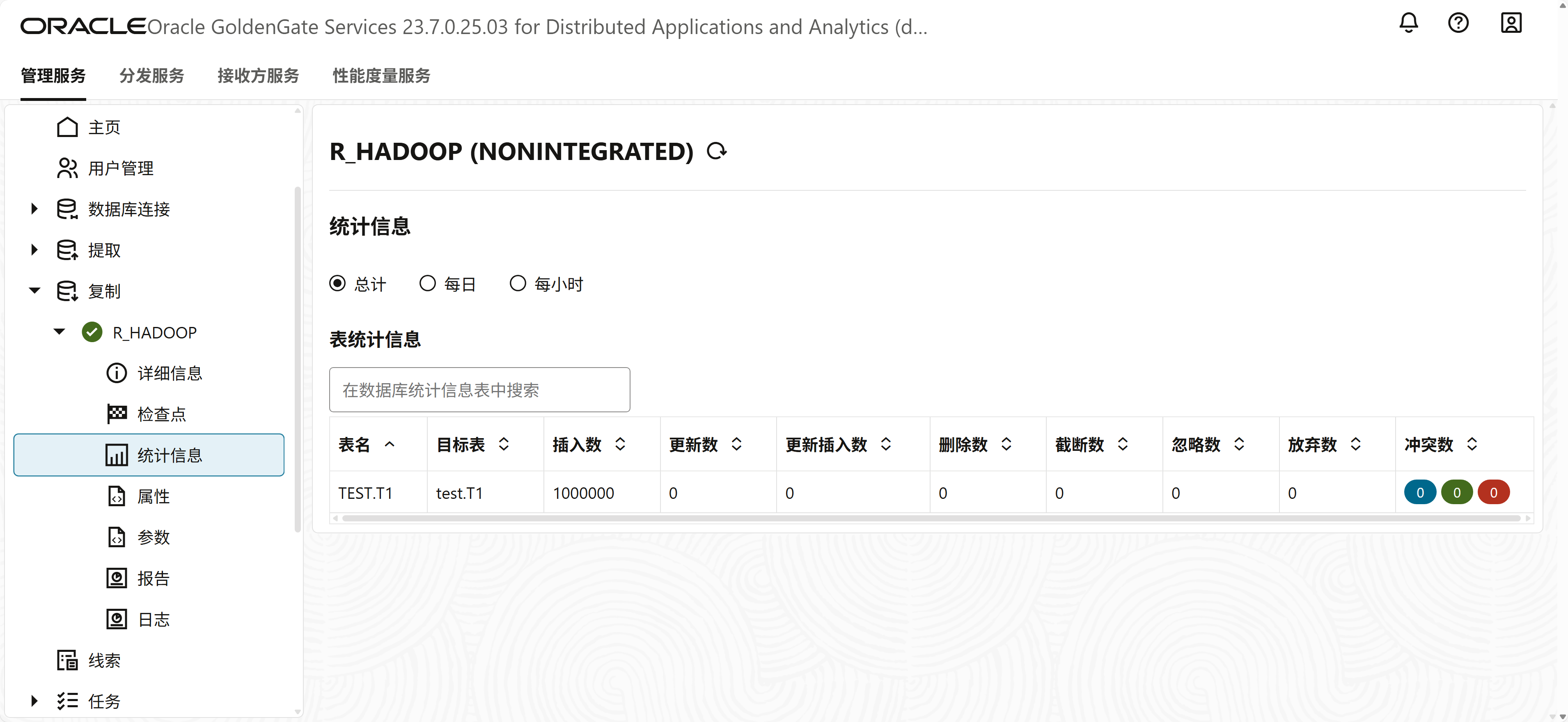
在hadoop中查看生成的数据