




概述
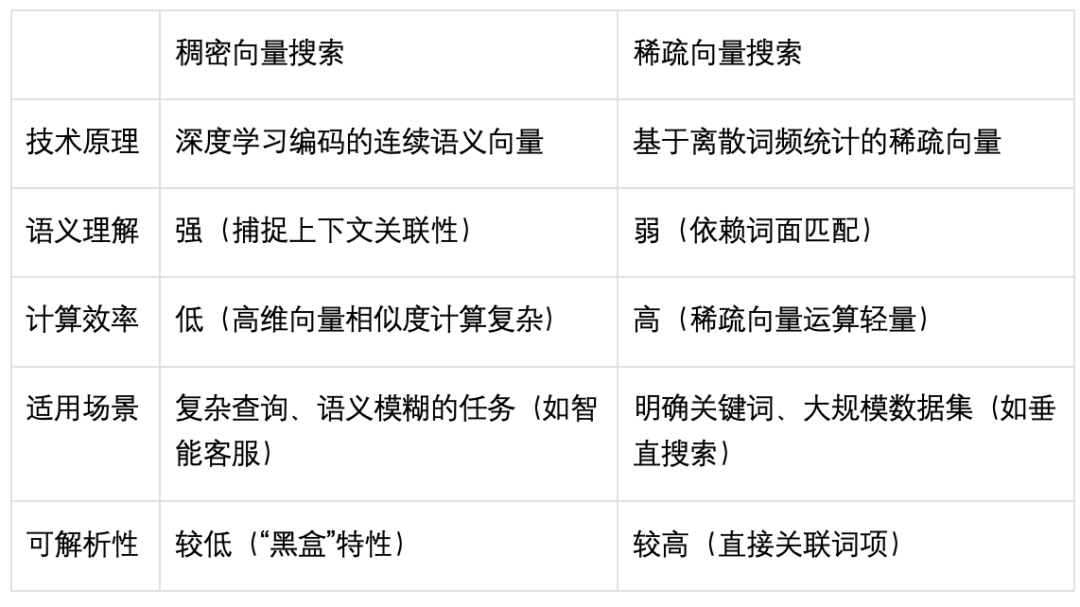
巨杉数据库在较早版本中已经支持了向量检索功能。一般情况下,向量检索特指稠密向量检索。因其对语义理解精准的特点,在很多场景,尤其是RAG中被广泛使用。但是,稠密向量也存在诸多不足:
对精确匹配支持不足:稠密向量在捕捉语义相似性方面表现出色,但在处理精确匹配查询时表现不佳。例如在搜索特定关键字时往往无法给出正确结果。
缺乏可解释性:稠密向量通常无法直接对应人类可理解的特征,这使得模型决策过程难以解释。在一些需要高解释性场景中存在限制。如信贷审批、医疗等。
对噪声敏感:稠密向量对数据中的噪声较为敏感,搜索结果准确性容易存在波动。
为解决以上问题,巨杉数据库特别增加了对稀疏向量检索的支持。
稀疏向量检索
稀疏向量是一种大部分元素为零、仅有少数非零元素的高维向量表示形式。这种表示方式在处理高维数据时,能够有效降低存储和计算的复杂度。
稀疏向量具有以下优点:
高效的存储和计算:由于稀疏向量中大部分的元素为零,仅需存储非零元素。这种表达方式大幅降低存储和计算需求。
如向量[0, 0, 1.2, 0, 0, 6.1]可表示为[(2, 1.2), (5, 6.1)]。
适用于精确匹配任务:稀疏向量在处理需要精确匹配关键词或短语的任务时表现出色。例如,在信息检索系统中,稀疏向量可以有效地捕捉查询与文档之间的关键词匹配关系,从而提高检索的准确性。
在处理专业术语或罕见关键词时,稀疏向量也能够更好地捕捉这些特征的细微差别,适应特定领域的需求。
可解释性强:在稀疏向量中,每个维度通常对应一个具体的特征或词汇,这使得模型的决策过程更加透明和可解释。例如,在文本分析中,可以明确地看到哪些词汇对模型的预测产生了影响。
BM25稀疏向量
BM25(Best Matching 25)是一种经典的信息检索算法,是基于Okapi TF-IDF算法的改进版本,旨在解决Okapi TF-IDF算法的一些不足之处。 其被广泛应用于信息检索领域的排名函数,用于估计文档D与用户查询Q之间的相关性。 它是一种基于概率检索框架的改进,特别是在处理长文档和短查询时表现出色。
对文档集合进行分词处理,生成词汇表(Token列表),词汇表的大小即为稀疏向量的维度(通常为几万到十万维)。
示例:若文档集合包含“人工智能”和“汽车”等关键词,词汇表会将这些词映射到特定维度。
2.统计逆文档频率(IDF)
1)计算每个词的IDF值,公式为:
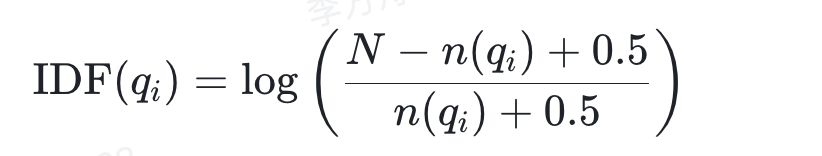
其中,N 为文档总数,n(qi )为包含词 qi 的文档数。
2) IDF反映词的稀有程度,低频词(如专业术语)权重更高。
3.计算词频(TF)与文档长度归一化
1) 词频TF计算公式:
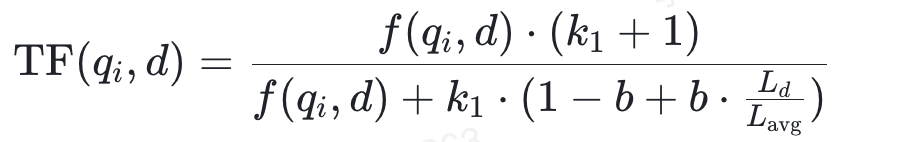
Ld 为文档长度,
Lavg 为平均文档长度
4.生成稀疏向量
1)文档向量:每个维度对应词汇表中的词,非零值为该词的TF-IDF加权得分
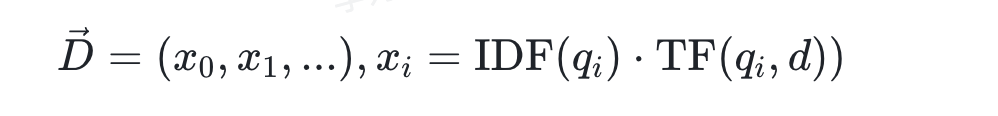
5.查询向量
1)仅包含查询词对应的维度,权重为IDF值。
2)通过dotProduct计算查询得分
示例
在准备好的成语数据集上,创建稀疏向量索引
db.runCommand({createIndexes:"chengyu_data",indexes:[{key:{"bm25_embedding":"sparseVector"},name:"bm25_vector_index",vectorSearchDefinition:{similarity:"dotProduct"}}]})
查询"鲁国,齐国",返回数据
{'_id': ObjectId('67ce46c4deaadec0f6cbc909'), 'name': '齐纨鲁缟', 'means': '古代齐国和鲁国出产的白色绢◇亦泛指名贵的丝织品。', 'score': 7.297494888305664}{'_id': ObjectId('67ce46c6deaadec0f6cbe238'), 'name': '季孙之忧', 'means': '季孙鲁国大夫;忧忧患。指内部的忧患。', 'score': 4.5486063957214355}{'_id': ObjectId('67ce46c9deaadec0f6cc001e'), 'name': '城北徐公', 'means': '原指战国时期齐国姓徐的美男子◇作美男子的代称。', 'score': 3.8497567176818848}{'_id': ObjectId('67ce46c4deaadec0f6cbc8fc'), 'name': '齐东野语', 'means': '齐东齐国的东部;野语乡下人的话。孟子蔑视农民,认为他们说的话没有根据,听信不得。比喻荒唐而没有根据的话。', 'score': 3.69185209274292}
查询"鲁仲连",返回数据:
{'_id': ObjectId('67ce46c5deaadec0f6cbd2be'), 'name': '鲁连蹈海', 'means': '战国时齐国人鲁仲连不满秦王称帝的计划,曾说,秦如称帝,则蹈东海而死◇以之表示宁死而不受强敌屈辱的气节、情操。', 'score': 3.164668560028076}{'_id': ObjectId('67ce46c9deaadec0f6cc0687'), 'name': '炳如日星', 'means': '光明如同日月星辰。', 'score': 0.5}{'_id': ObjectId('67ce46c9deaadec0f6cc0292'), 'name': '残年暮景', 'means': '残衰残。指人到了晚年。', 'score': 0.5}{'_id': ObjectId('67ce46c9deaadec0f6cc0237'), 'name': '昌亭旅食', 'means': '寄食南昌亭长处。借指寄人篱下。', 'score': 0.5}
可以看到,稀疏向量检索有效捕捉到了正确的记录。
总结
在目前RAG场景中,单一的稠密向量检索已经无法满足需求。通过混合检索(Hybrid Search),将多种检索技术进行融合排序,可以大幅提高AI系统的准确率。在后续的文章中,我们将会对该类技术进行深入探讨。
