




文章作者:陈飞 中付支付大数据工程师
文章整理:曾辉 白鲸开源
大家好,很高兴通过SeaTunnel Demo 方舟计划和大家分享一个 简单但常见的 MySQL 到 MySQL 数据同步与合并场景案例。
我是陈飞,目前就职于中付支付基础架构部,从事大数据相关工作,日常主要负责交易数据的实时清洗和计算处理。今天的案例也是我在实际工作中遇到的问题,希望能抛砖引玉,欢迎有更丰富经验的大佬一起分享交流。
演讲回放
版本要求:
Apache SeaTunnel --> Apache-SeaTunnel-2.3.9
场景描述
在我们的业务系统中,存在两个 MySQL 源库:
source_asource_b
这两个库中存在一张表结构相同的表,但数据来自不同的业务线,两边都会同时产生数据,因此存在 主键重复 的问题。
我们的目标是将这两个源库的表数据 合并同步到一个目标库(我们称为 C 库),以便于统一分析和查询。
面临的挑战
两个源库的表结构虽然一致,但主键重复,需要避免冲突 后续可能存在字段不一致或字段新增的需求 同步过程需尽量实时,且不能产生重复数据
解决方案
我们采用了如下方式来实现这个同步与合并的方案:
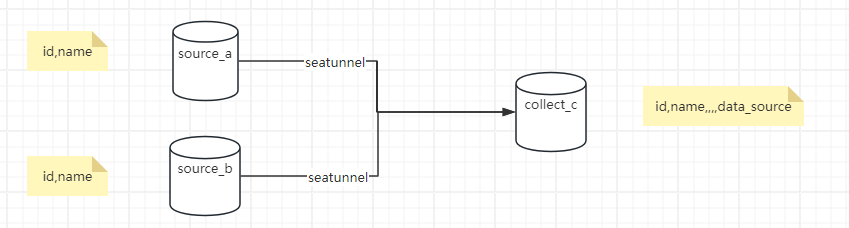
在 C 库新建目标表:
表结构需要覆盖两个源表的所有字段(当前一致,未来可能扩展) 增加一个额外的字段: data_source
,用于标识数据来源(source_a
或source_b
)不可为空的字段需要有默认值
设置联合主键与唯一约束
使用 原主键 + data_source
作为联合主键,确保不会因为两个源的主键重复而导致冲突
使用两个 Seatunnel 进程进行数据同步:
分别使用 MySQL CDC 连接器 监听 source_a
与source_b在每条数据中打上来源标识字段 data_source使用 JDBC Sink 写入到 C 库
实战演示
下面我们直接进入实战环节,关于 SeaTunnel 的基础知识,这里就不再赘述,上一期的大佬已经讲得非常清楚了,我们直接进入正题。
上期文章链接:【实操回顾】基于Apache SeaTunnel从MySQL同步到PostgreSQL——Demo方舟计划
使用 MySQL CDC 前的准备工作
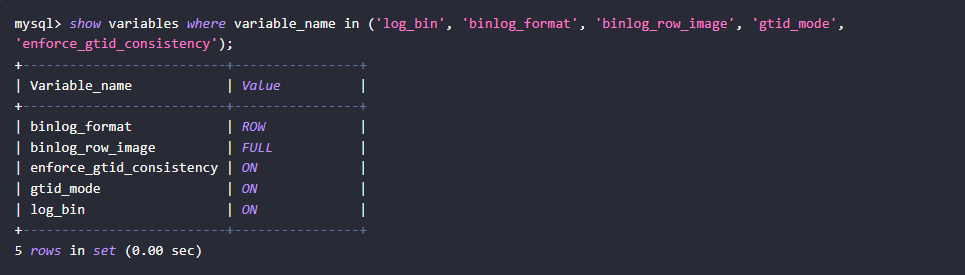
要使用 mysql-cdc
连接器,有两个必要的前置条件:
MySQL 源库需开启 Binlog 日志
binlog_format
必须设置为ROWbinlog_row_image
设置为FULL
-- 检查当前配置
SHOWVARIABLESLIKE'binlog_format';
SHOWVARIABLESLIKE'binlog_row_image';
-- 如果未开启,可在 my.cnf 文件中添加以下配置:
[mysqld]
server-id = 1
log-bin = mysql-bin
binlog-format = ROW
binlog-row-image = FULL
以上权限说明及设置方式可以参考官网文档,文档中提供了详细的权限说明与示例,建议大家同步查阅。
准备拥有复制权限的账号
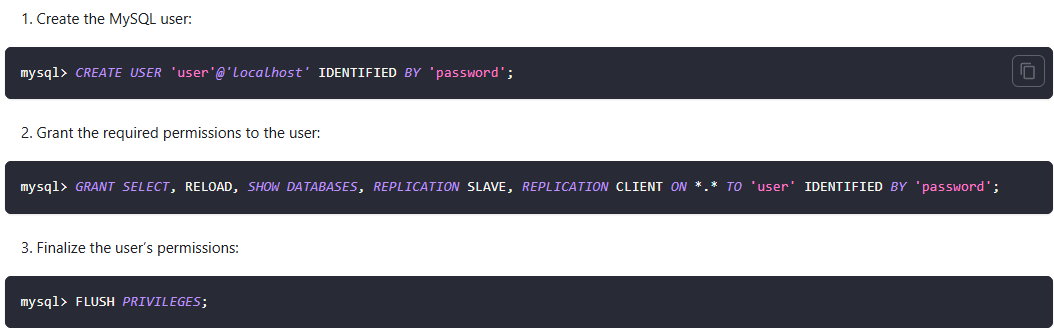
-- 创建同步账号
CREATE USER 'cdc_user'@'%' IDENTIFIED BY 'your_password';
-- 授予必要权限
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cdc_user'@'%';
FLUSH PRIVILEGES;
准备 SeaTunnel 运行包与插件
方式一:下载官方二进制包
适合 服务器可访问外网 且 无需复杂定制 的场景。
下载地址:官方 Releases 页面 需要手动添加插件及插件驱动(如 mysql-cdc
,jdbc
)插件安装说明可参考官方文档:插件管理
wget "https://archive.apache.org/dist/seatunnel/${version}/apache-seatunnel-${version}-bin.tar.gz"
config/plugin_config保留需要的插件
bin/install-plugin.sh
方式二:从 GitHub 克隆源码自行编译
适合对插件有特殊需求或希望获得完整插件支持的用户。
sh ./mvnw clean install -DskipTests -Dskip.spotless=true
seatunnel-dist/target/apache-seatunnel-2.3.9-bin.tar.gz
自行编译后生成的包中默认已集成所有插件及对应依赖,无需额外操作。
本案例使用的插件:
mysql-cdcjdbc
插件说明与驱动依赖也可参考对应的文档!
Apache SeaTunnel 部署方式简介
SeaTunnel 支持多种部署方式:
使用 Seatunnel 自带引擎(Zeta)
作为 Spark Flink 作业运行
使用 Zeta 引擎时的三种模式:

配置文件结构说明
集群搭建完成后,我们开始准备配置文件。
一般情况下,SeaTunnel 的配置文件可以分为以下四个部分:
Env:引擎相关配置 Source:源数据读取配置 Transform:数据转换信息(可选) Sink:写出目标库的配置
Env引擎配置
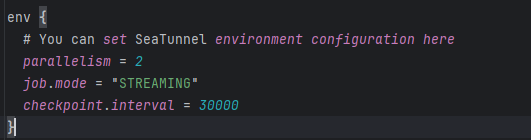
parallelism
:并行度,表示任务运行的并发度,数值越大越快,具体要结合资源情况设置。job.mode
:作业运行模式。由于我们使用的是mysql-cdc
插件,因此必须设置为 Streaming 模式。checkpoint.interval
:检查点间隔,Streaming 模式下默认是 30 秒一次,可以根据需要调整。
Source数据源配置(MySQL CDC)
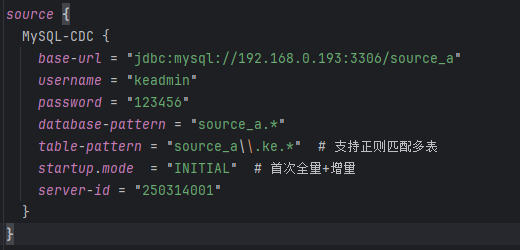
使用的插件是 mysql-cdc
,需要配置以下内容:
连接信息:包括数据库地址、用户名、密码等。 库名与表名:可以通过 database-names
和table-names
显式指定,也可以使用正则表达式模糊匹配。startup.mode:CDC 的启动模式,默认为“先全量后增量”,适合大多数同步场景。如需了解其他启动模式的区别,可以参考官方文档。 server-id:MySQL 的 CDC 读取服务 ID,虽然可以不写,但建议明确指定,防止与已有的从库 ID 冲突。 MySQL 配置建议:在使用 mysql-cdc
前,需要确保:binlog
功能已开启;binlog-format
设置为ROW
;binlog-row-image
设置为FULL
;MySQL 账号需具备读取 binlog
、主从复制、查询所有表等权限。
Transform数据转换配置(可选)
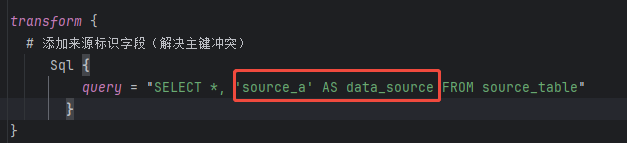
在本案例中,我们需要给每条数据添加一个字段,用于标识数据来源,例如:data_source
字段,值可以是 source_a
或 source_b
。
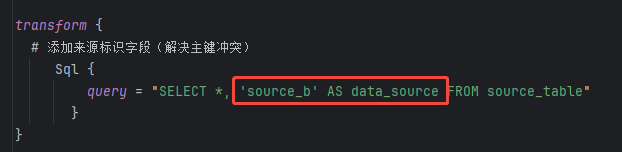
这个转换过程使用 sql
插件实现,通过添加常量字段的方式,将数据来源信息加到每条数据中。
需要注意:
每个源表可以单独指定转换规则; source_table
是保留字,表示上一个处理环节中的表名。
Sink写入配置
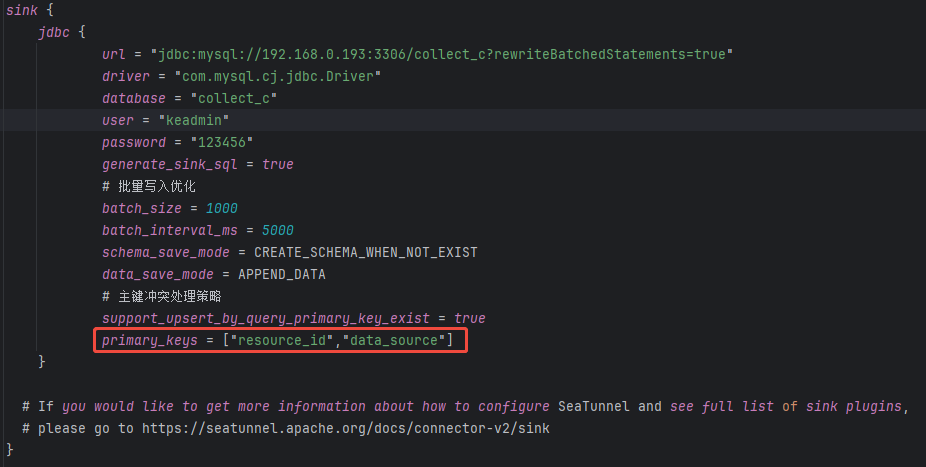
Sink 使用的是 jdbc
插件,配置项主要包括:
目标库地址、驱动、用户名、密码等连接信息; 根据目标表结构生成写入 SQL; 如果字段或结构不一致,可以自定义写入语句以匹配表结构。
小结
以上配置组合完成后,我们就可以实现从多个源库(如 source_a
和 source_b
)实时同步数据到目标库的需求。在同步的同时,我们还增强了字段,使数据能够被标识来源并统一写入。
整个流程既支持复杂数据结构,又能灵活适配业务场景,是一个适合实际生产的数据集成案例。
Sink 写入优化与效果验证
在配置 Sink 时,我们还可以做一些写入性能方面的优化:
批量写入策略
批量大小 和 写入间隔:满足任意一个条件就会触发写入操作。
关键配置参数说明
schema_save_mode:结构保存策略
如果结构已存在则忽略;如果不存在,则根据上一个环节的输出结构自动创建。 data_save_mode:数据保存策略
这里我们选择的是 追加(append) 模式。 support_upsert_by_query_primary_key_exist:是否支持根据主键做 Upsert
本次开启了该功能,用于支持主键冲突时的更新。 primary_keys:指定写入数据的主键
这里必须指定,包括原表的主键和我们 transform 阶段新增的 data_source
字段。
提交任务
./seatunnel.sh --config ../config/demo/collect_a.config -e cluster --cluster sz-seatunnel --name collect_a --async
./seatunnel.sh --config ../config/demo/collect_b.config -e cluster --cluster sz-seatunnel --name collect_b --async
--config:指定配置文件
-e:运行模式 cluster/local
--cluster:集群名称,部署集群时配置,默认是seatunnel
--name:任务名称
--async:后台运行
实际运行效果验证
到这里,配置部分就全部完成了。接下来我们来看下实际运行的效果:
当前有 a
表和b
表,c
表为空。先运行 a
的同步进程。查看 c
表,已经写入了a
表的数据,且data_source
字段为source_a
。接着运行 b
的同步进程。再查看 c
表,写入了b
表的数据,data_source
字段为source_b
。修改一下 a
表的数据。因为我们设置了批量写入策略,这里等个两秒,再去看 c
表。对应的数据已更新,符合预期。

到这里整个数据同步和合并的流程就全部完成啦!
非常感谢大家的聆听 🙏,希望这个案例能为大家提供一些思路,也欢迎大家分享自己在 Apache SeaTunnel 使用中的更多经验,我们一起交流学习!
 活动推荐
活动推荐
本次Meetup分享基于Apache SeaTunnel的二次开发,重点针对复杂数据处理场景中的功能短板进行了系统性增强,在保持原有架构优势的基础上,深度优化了数据处理全链路能力。
Apache SeaTunnel
Apache SeaTunnel是一个云原生的高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会ApacheSoftware Foundation正式宣布Apache SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达8k+,社区达到6000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等170多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
同步Demo
新手入门

最佳实践

测试报告

源码解析
Apache SeaTunnel
