




现在所熟知的大数据技术有storm,spark,flink,本文将对这几种框架做简单的了解,同时进行技术选型,并对选型技术进一步的学习。
流处理技术的演变
Apache Storm是流处理先锋,提供了低延迟的流处理,但也为实时性付出了一些代价:很难实现高吞吐,并且其正确性没有达到通常所需要的水平,换句话说,它不能保证exactly-once,即便它能够保证正确性级别,其开销也是相当大的。
在低延迟和高吞吐的流处理系统中维持良好的容错性是非常困难的,为了得到有保障的准确状态,出现了一种替代方法:将连续事件中的流数据分割成一系列微小的批量作业,如果分割的足够小(即所谓的微批处理作业),几乎可以实现真正的流处理,但因为存在延迟,无法做到完全的实时,这就是spark批处理引擎上运行的Apache Spark Streaming。使用微批处理的方法,可以实现exactly-once语义,从而保障状态的一致性,但是在延迟性方面付出了很大的代价,不具备实时处理能力。
Flink的出现,避免了上述弊端,并且拥有所需的诸多功能,还能按照连续事件高效的处理数据。
那Flink是如何做到的呢?
Flink初探
Apache Flink is a framework and distributed processing engine forstateful computations over unbounded and bounded data streams.Flink has been designed to run in all common cluster environments,perform computations at in-memory speed and at any scale.
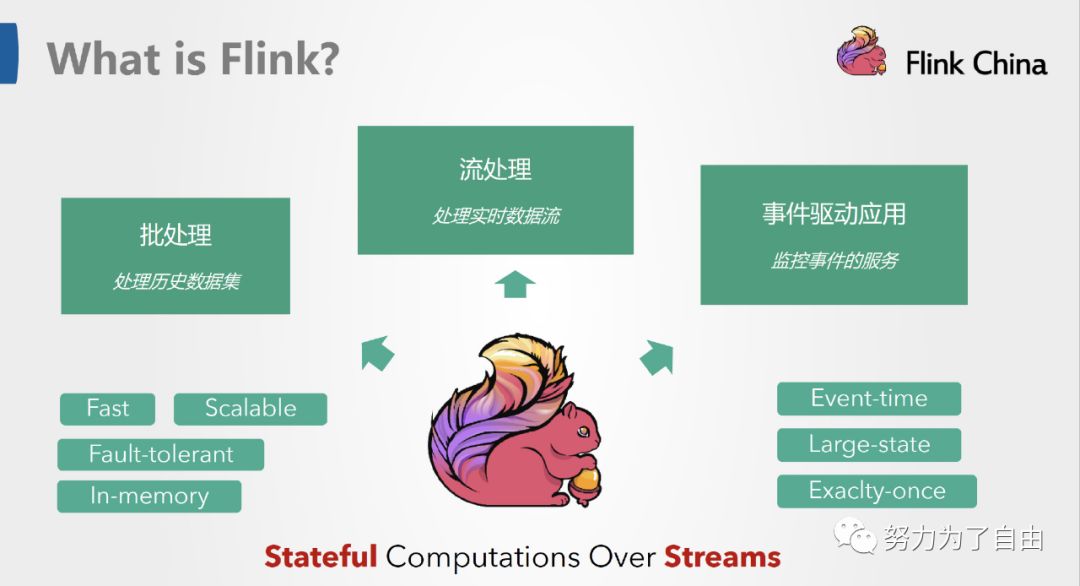
这是官方网站上的介绍,flink是一个分布式处理引擎,对有界和无界数据流进行有状态计算,flink可以运行在所有的集群环境中,在内存中进行任意规模的运算。
介绍几个概念:
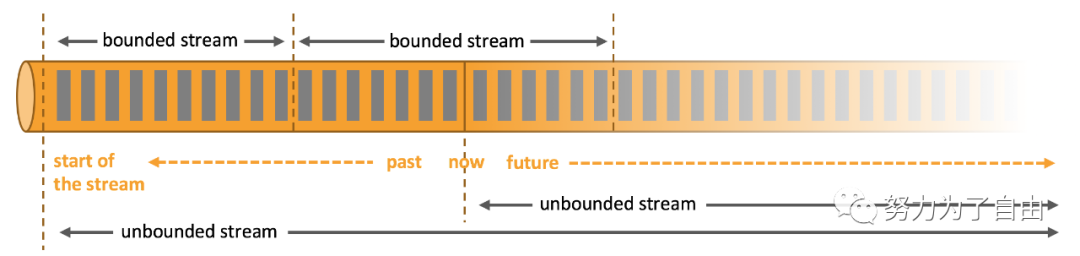
Bounded streams have a defined start and end. Bounded streams can beprocessed by ingesting(接收) all data before performing any computations.Ordered ingestion is not required to process bounded streams becausea bounded data set can always be sorted. Processing of boundedstreams is also known as batch processing(批处理).
Unbounded streams have a start but no defined end. They do not terminate(结束)and provide data as it is generated. Unbounded streams must be continuouslyprocessed,i.e., events must be promptly(立即) handled after they have beeningested.It is not possible to wait for all input data to arrive because theinput is unbounded and will not be complete at any point in time. Processingunbounded data often requires that events are ingested in a specific order,such as the order in which events occurred(事件发生的先后顺序), to be able toreason about result completeness.
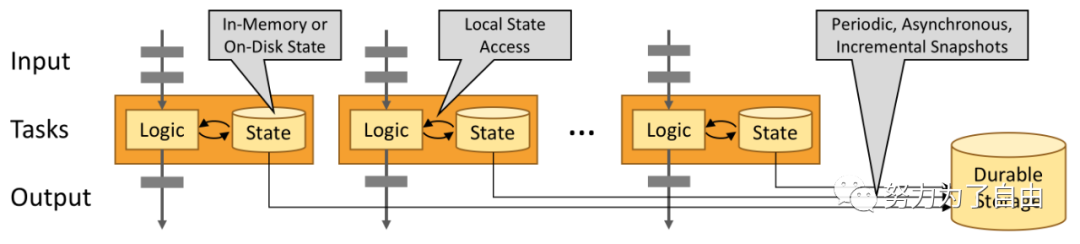
Stateful(有状态) Flink applications are optimized for local state access.Task state is always maintained in memory or, if the state size exceedsthe available memory, in access-efficient on-disk data structures.Hence, tasks perform all computations by accessing local, often in-memory,state yielding very low processing latencies. Flink guaranteesexactly-once(一致性) state consistency in case of failures by periodicallyand asynchronously checkpointing the local state to durable storage.
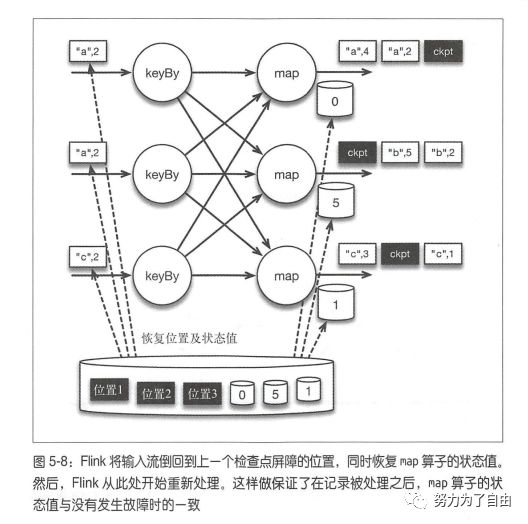
state checkpoint
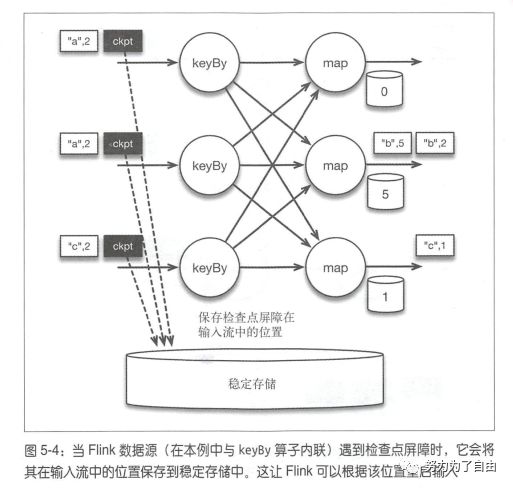
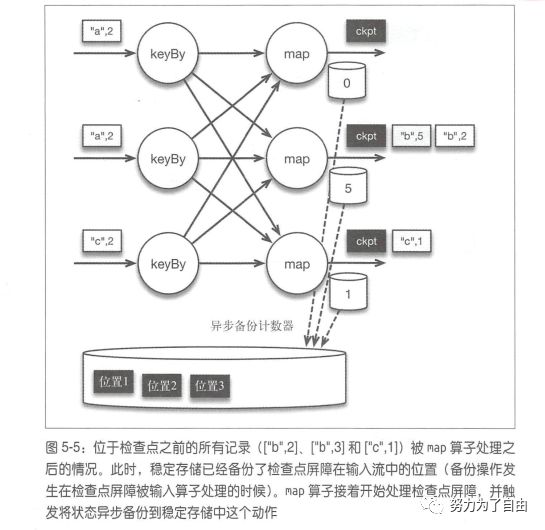
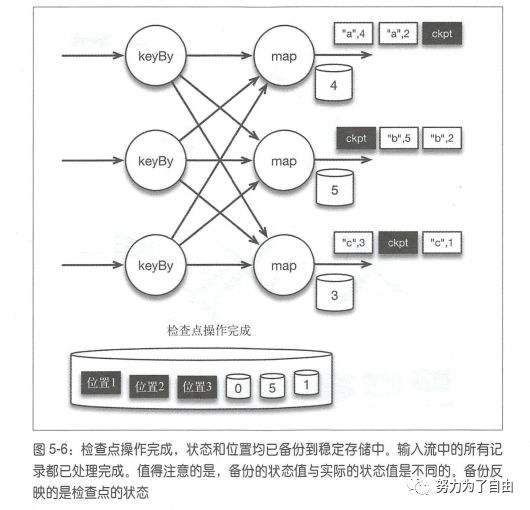
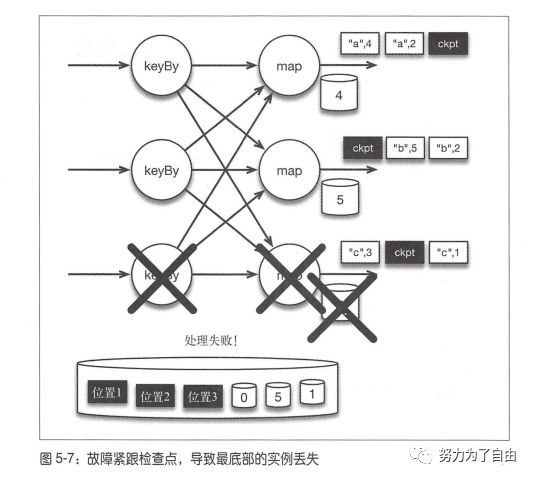
有状态流处理维护所有已处理记录的状态值,并根据每条新输入的记录更新状态,flink引入检查点的特性,在出现故障时将系统重置回正确状态。正因为检查点特性,flink可以保证exactly-once,并且不牺牲性能。


time window
在流处理中,主要有两个时间概念
事件时间,即事件实际发生的事件,每个事件都有一个与它相关的时间戳,并且时间戳是数据记录的一部分,事件时间其实就是时间戳
处理事件,即事件被处理的时间,处理事件其实是处理事件的机器所测量的时间

上图说明了事件时间和处理时间的区别


当采用事件时间定义窗口时,应用程序可以处理乱序事件流以及变化的事件时间偏差,并根据事件实际发生的时间计算出有意义的结果。
窗口
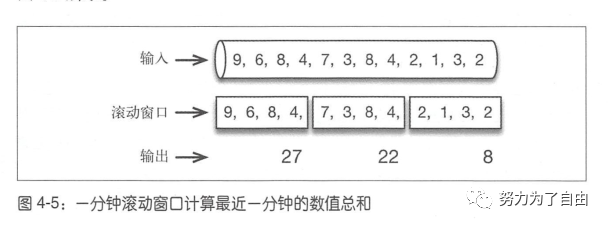
时间窗口支持滚动和滑动,举例说明。
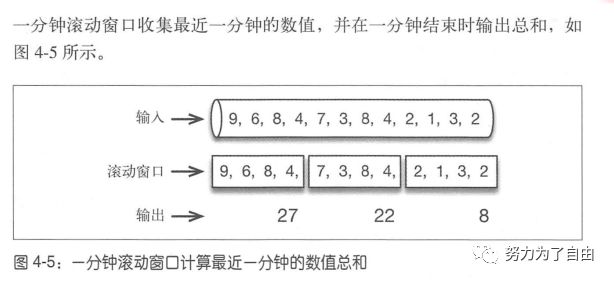
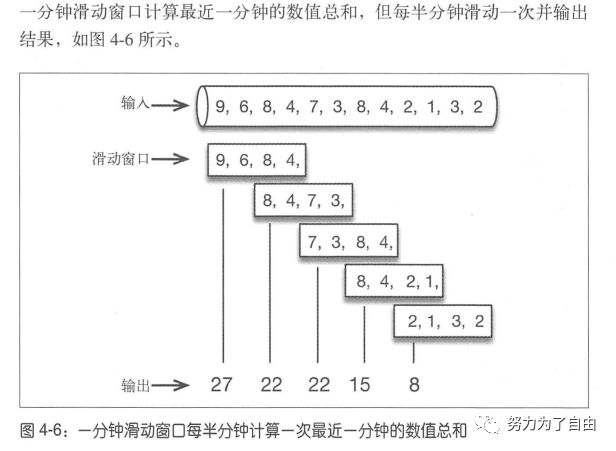
flink一分钟滚动窗口定义如下:stream.timeWindow(Time.minutes(1))每半分钟(30s)滑动一次的一分钟滑动窗口定义如下stream.timeWindow(Time.minutes(1),Time.seconds(30))
计数窗口
计数窗口分组的依据不再是时间戳,而是元素的数量。计数窗口的滚动滑动分别定义如下:
stream.countWindow(4)stream.countWindow(4,2)(每两个元素滑动一次)
计数窗口存在数量永远达不到导致窗口无法关闭的可能,被该窗口占用的内存也就浪费了。一种解决办法是用时间窗口来触发超时。
会话窗口
会话窗口由超时时间设定,即希望等待多久才任务会话已经结束。
以下代码表示,如果用户处于非活动状态长达5分钟,则任务会话结束。stream.window(SessionWindows.withGap(Time.minutes(5)))
触发器
触发器控制生成结果的时间,即合适聚合窗口内容并将结果返回给用户。每一个默认窗口都有一个触发器。例如,采用事件时间的时间窗口将在收到水印时被触发。对于用户来说,除了收到水印时生成完整、准确的结果之外,也可以实现自定义的触发器。
时空穿梭
实时流处理总是在处理最近的数据,历史流处理则从过去开始,并且可以一直处理至当前时间。
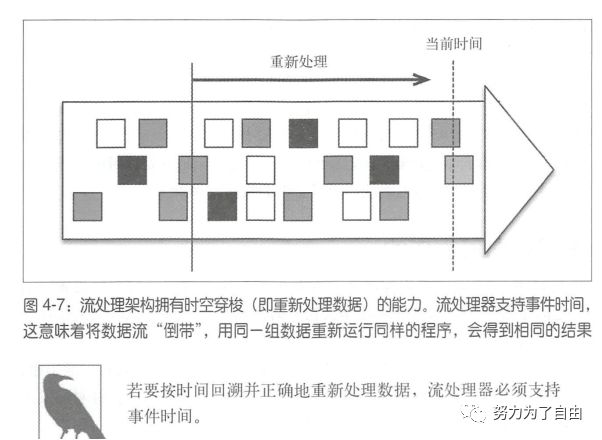
如果窗口的设定时根据系统时间而不是时间戳,那么每次运行同样的程序,都会得到不同的结果。事件时间使数据处理结果具有确定性,因为用同一组数据运行同样的程序,会得到相同的结果。
水印
支持事件时间对于流处理架构而言至关重要,因为事件时间能保证结果正确,并使流处理架构拥有重新数据的能力。当计算基于事件时间时,如何判断所有的事件是否都到达,以及何时计算和输出窗口的结果呢?换言之,如何追踪事件时间,并知晓输入数据已经流到某个事件时间了呢?为了追踪事件时间,需要依靠由数据驱动的时钟,而不是系统时钟。


水印是如何生成的?


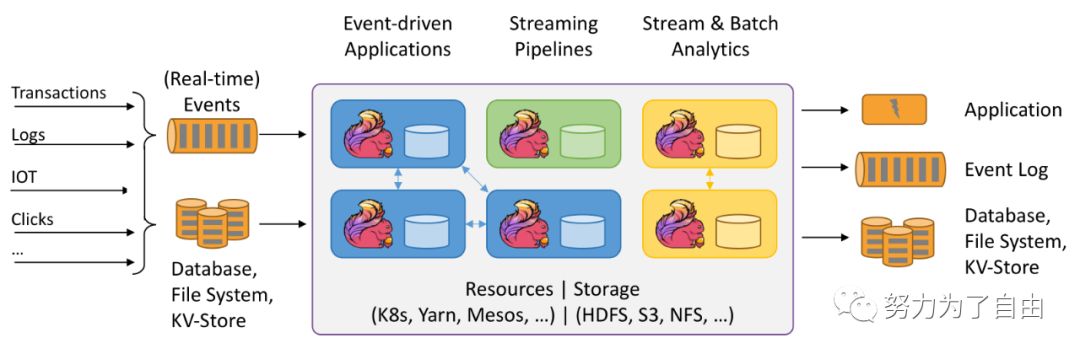
本文只做一些概念性的了解,接下来会进行项目实战演示。
