




字节跳动的分布式图数据库:ByteGraph
一、ByteGraph2.0
1、架构
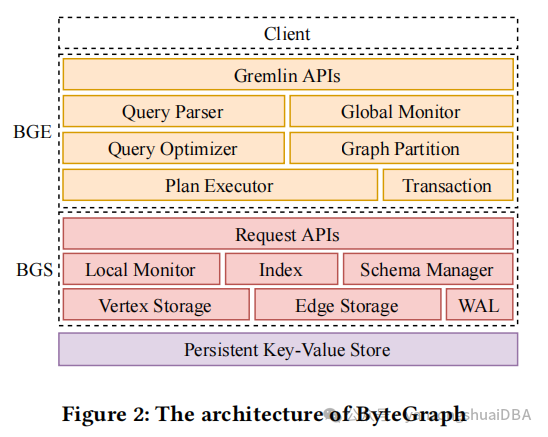
底层存储依赖于一个分布式KV存储,也是一个计算与存储分离的架构。一个ByteGraph集群由三层组成:执行层(BGE)、内存cache层(BGS)、基于一个持久化KV存储的存储层。执行层注意处理计算密集型操作,比如排序和聚合,BGS关注原生cache数据管理和日志管理。每一层都可以独立扩展。持久化存储层存储BGS产生的所有KV对儿(图数据、logs和元数据)。KV存储层可以使用RocksDB、TerarkDB等,在ByteGraph中作为一个黑盒存在。
ByteGraph使用Gremlin查询语言;提供了rule-based和cost-based优化器,为了增加cache hit率,使用一致性hash算法将图进行逻辑分片,每个分片映射到一个BGS实例。因此,同一个分片上的点进行了分组并通过RPCs打包发送给关联的其他BGS实例进行进一步处理。
BGE通过监控心跳,维护一个全局BGS实例的视图,并且分布式事务使用2PC协议。
可以在多个机器上部署各自的BGS,相当于一个缓存层,2.0每个节点一个partition,通过hash算法分片到一个BGS中,该partition包括点的邻接表(边树)
1)查询解析和重写:将gremlin解析成语法树并将其改写成执行计划,并支持查询计划缓存
2)优化器基于规则和代价的优化:RBO主要基于Gremlin开源实现中自带优化规则、针对字节应用的算子下推、自定义的算子优化;CBO本之上对每个点的出入度做统计,把代价用方程量化表示
3)执行器基于push-based pipeline:理解GS数据分partition逻辑,找到相应数据并下推部分算子,保证网络开销不会天大,最后合并查询结果
2、数据存储

Bytegraph也采用属性图模式管理图。图3中的例子,有两个点类型(User、Video)和4个边类型(Like、Post、Comment、Follow);点和边的类型不同,schema也不同,比如点(User{name,age},Video{tag})。
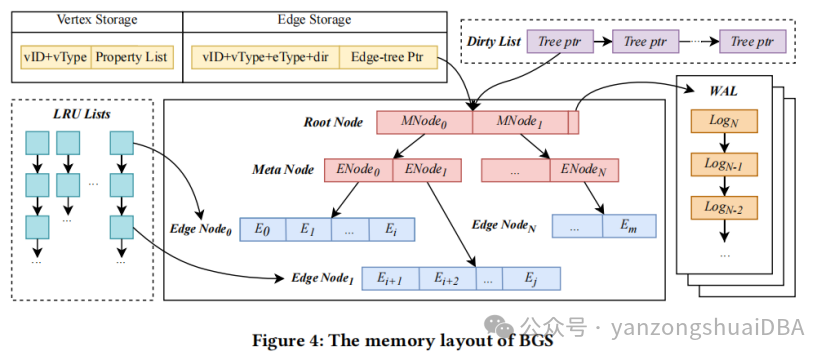
1)内存中分别以Vertex Storage和Edge Storage缓存点和边
2)每个点和它的属性构成KV对儿,key是唯一ID和点类型,value是点属性链表,将他们一起存储在KV中
3)图3中User A的key是<A,User>。访问点属性:BGS使用get()请求KV存储,并将该KV对儿放到Vertex Storage中;一旦点的任何属性被更改,都会通过set()立即刷到磁盘
4)边以邻接表形式组织,边的key:<起点vID,起点vType,eType,dir>,汇聚成一个Edge Storage,再把Edge Storage组织成Btree,有自己独立的WAL,多个Edge Storage形成一个森林,访问不同的邻接表时不需要做并发管理。图4所示,edge-tree有3种类型点:Root Node、Meta Node、Edge Node,每个都以KV对儿存储。和B-tree类似,仅Edge Node存储物理边数据。
5)每种类型额节点都有一个上下边界大小用来平衡读写放大问题
6)最开始,edge-tree有2层:root node和edge node。Root node索引的edge node超过了上界后,会创建meta node作为中间层索引edge node(和B+tree的中间节点功能类似),同样如果edge node大象超过它的上界,edge node会分裂成2个nodes;若两个edge nodes小于下届大象,会合并成一个。根据经验,将上下边界设置成1000/2000,3层edge-tree的容量是八十亿,足够存储一个真实graph的邻接表
7)每个边实例由目标点的ID、类型和边属性链表组成
8)edge-tree中指定一个排序键进行排序,由边属性的schema决定。默认无排序键时,以tsUs(edge插入的时间戳)排序,也可以根据真实负载进行配置或者动态调整
9)通过WAL功能异步更新edge-tree:更新先以WAL持久化到磁盘,然后内存进行更新,标记为dirty node。BGS周期性将dirty nodes刷盘
10)图4中,BGS维护一个全局Dirty List表示包含dirty nodes的edge-trees,将脏edge-tree插入该链表的条件:(1)最近一个checkpoint后WAL量超过了阈值;或者(2)LRU链表中选择一个最少用的node,以腾出更多可用空间(和InnoDB的Buffer Pool管理类似)。一个edge-tree的WAL通过一个单调递增的ID进行index,Root node将最后持久化操作的ID作为检查点。
3、edge-tree是什么
一个partition(即一个edge-tree)的定义:一个起点 + 一种特定边类型扇出的一跳所有邻居。在GS中将一个partition按照排序键(可以显式设置或系统默认维护,即下图的pagekey1等)组成Btree,每个Btree都有独立的WAL,独立维护自增logid。如下图所示,就是一个edge-tree:
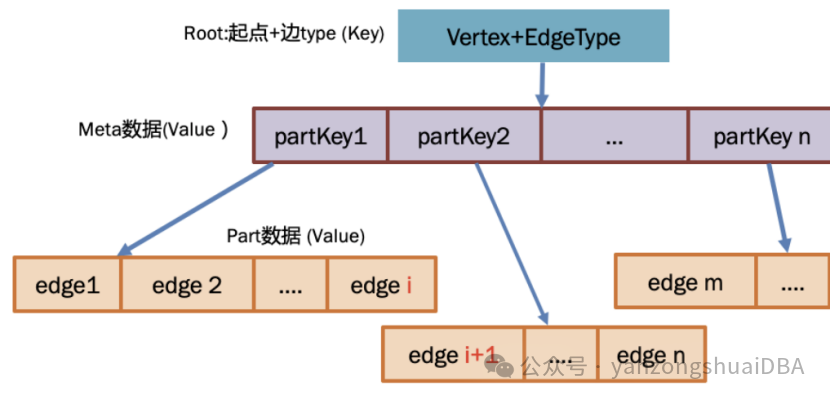
1)某一个起点的同一个边type的所有终点是一个存储单元,即一个edge-tree
2)一级存储形式:点的出度 < 一个阈值时
(1)起点ID + 起点Type + 边Type + 方向作为key
(2)同一个起点,相同type且相同方向的所有边组成一个value
3)多级存储形式(edge-tree):点的出度超过阈值时,如上图
(1)所有边均匀切分成EdgePage,并分配对应PartKey,所有Partkey组成meta数据
(2)Metapage整体作为Value存储,KV表示:(点,边类型)->(PartKey1,PartKey2,...)
(3)EdgePage存储格式和一级存储类似,KV表示:(PartKey)->(Edge1,Edge2,...)
(4)metaPage可以有多级,和EdgePage整体组成Btree,通过COW实现读写并发
(5)PartKey可以是边的某些属性,这样Btree就是边的属性有序
4)一级存储和多级存储之间可以动态转化
5)根据点ID和边类型进行hash分片,将它进行分割,放到分布式存储的各个shard中,一个shard对应一个存储节点
每个页都存储为一个独立的KV对:
1)Meta Page的KV:<起点+边类型,page数据:PartKey1,PartKey2,...>
2)Edge Page的KV:K保存在meta Page中,就是PartKey;V:edge1等(标点的ID、类型和边属性链表)
理解下为什么这么存储?即KV建模存储图怎么做才可以最优
1)基于KV的建模,最简单且直观的方式就是一个KV对应一条边,它的写放到也很小。因为粒度太细,做1跳领域的查询时,涉及到大量的随机读写,数据的局部性就没有了,性能退化很大
2)如果用一个KV保存一个起点的所有边,局部性很好,但它的写放到会很大。比如改了对应一个点上的一条边,就需要将整个V都更高
3)所以ByteGraph做了一个折中,一个点同一个边type的所有终点是一个存储单元,也就是基于起点ID+起点类型+边类型去做group by,具有相同值的所有边集合认为逻辑上属于一个分区
4)如果这个分区仍然很多点,比如某一个关注关系,粉丝1000W,用一级的一个page去存肯定不够,ByteGraph就将他拆成多页,组成一个Btree。这样使用多级分区的方式降低了读写放到的问题,同时起到了一个非常平衡的设计
4、edge格式
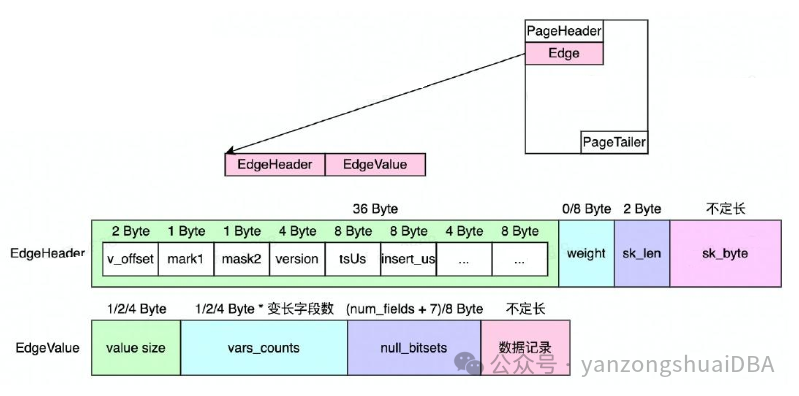
多属性的数据结构:header中保存schema版本,快速增加属性,快速访问终点ID/Type、Weigh、tsUs等边固有属性,支持Int/String两种终点ID/Type。属性在前,点在EdgeValue
5、存储引擎整体架构
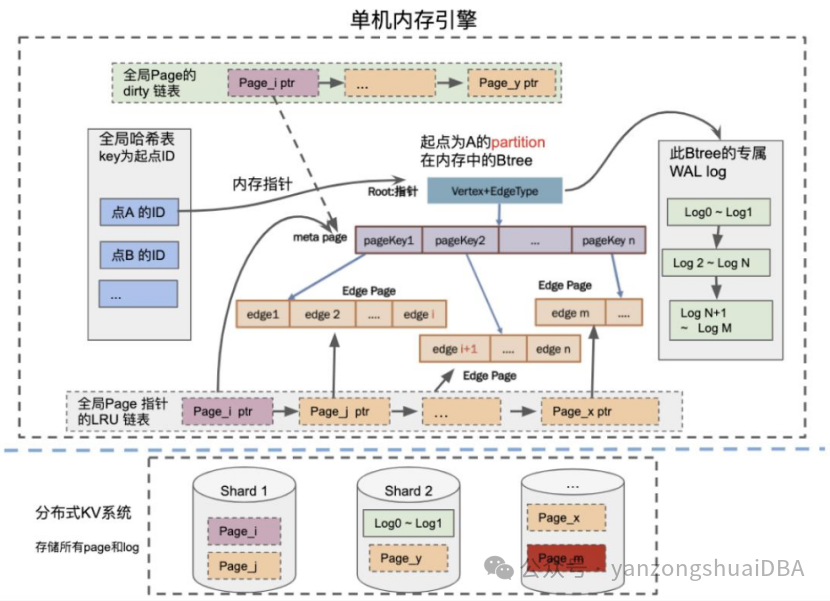
内存的整体结构:
1)全局hash表:key是起点ID+边type,当确定点ID时,实现快速查找
2)Hash表的每个元素都是一个partition,partition组织成btree,实现快速scan
3)单机全局多个Btree,构成森林关系
4)全局LRU表:partition和page按需加载到内存,根据LRU策略swap到磁盘KV
5)全局dirty表,某个页更改后,WAL同步写到磁盘,page插入脏页链表,异步写回
6)每个Btree单一写入,防止并发写入导致不完整;并且有自己独立的WAL日志流,写入请求只写入WAL并修改内存中数据。只有整个数据再次被从磁盘捞到内存中时会把原有磁盘上的就数据apply WAL,生成新数据,放到内存中。保证内存中始终是最新数据:从磁盘上再次读取,比如崩溃重启的时候。
6、图索引
局部索引:对给一个起点和边类型后,对边上属性构建的索引。用于边属性过滤和边属性排序。与对应的原始数据使用同一个日志流,保证一致性。默认,对于同一个起点,采用边上的属性(时间戳)作为主键索引,也可以支持其他元素(终点、其他属性)来构建二级索引。索引和原数据在同一个实例。
全局索引:基于一个属性值,能查到当前在整个图里面,具有特定属性的所有点的ID(点属性全局索引)。依据分布式事务能力维护数据和索引之间的一致性。索引和原数据一般不在同一个实例
7、查询优化
1)基于规则的优化:
(1)apache tinkerpop的gremlin开源实现有一些简单的优化规则
(2)过滤器合并、算子下推,将尽量多的计算下推到底层,减少数据传输
(3)算子融合,将部分step序列进行融合,更为高效
(4)数据预取与子查询消除,减少不必要的查询开销,以及提升查询并发度
2)基于代价的优化
(1)统计信息:点的出度
(2)代价:网络通信成本+计算成本+磁盘读取成本

比如基于代价的优化,上图做两跳的expand,先找到我到他的一跳邻居,然后依次让一跳邻居找他的二跳邻居,看有多少人当中有他。另外一种方式:找到我的一跳邻居后,找他的一跳入住邻居,然后依次做一个join,显然第一种方式开销少。
抽空研究下gremlin和ByteGraph开源版的优化器,看下代价估算模型和规则基于图是什么样的。
8、查询处理
查询路由到一个随机的BGE实例,具备rule-based优化器(29个规则,涉及step fusion、谓词下推、limit forward、数据预取、子查询消除)和Cost-based优化器。
1)查询会检测给定两个点直接是否存在边,我们可以在两个点的邻接表中定位target边
2)查询从较少邻居的点开始,减少数据访问
3)Edge-tree的每个root点会记录边数量
4)每个BGE实例会缓存最近查询的结果,同样的查询避免冗余处理。查询cache周期性更新,仅缓存对数据实时性要求不高,查询频率高的查询结果
5)通过一致性hash对一个图进行分区,每个分区分配给一个BGS实例。点和它的邻接表通过他们的key进行分区,因此点和它的edge-tree仅出现在一个BGS实例中,不会在KV存储上有写冲突
一致性hash算法:Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web.
参考
2022年VLDB论文:ByteGraph: A High-Performance Distributed Graph Database in ByteDance
2024年SIGMODE论文:BG3: A Cost Effective and I/O Efficient Graph Database in Bytedance
https://www.modb.pro/doc/95037
https://www.modb.pro/db/410316
https://www.modb.pro/db/113701
https://www.modb.pro/db/88523
