





在网络信息飞速发展的今天,我们常常希望能保存一些微信视频号里喜欢的内容。那么,如何使用 Python 实现微信视频号的下载呢?这篇文章将为你详细介绍其核心思路、技术实现步骤、关键难点及解决方案,还有一些必须注意的事项。掌握这些知识,能让你在合法合规的前提下,轻松获取所需视频资源。
技术原理剖析

实现微信视频号下载,首先要明白其背后的技术原理。抓包分析是关键的第一步,我们可以借助抓包工具,比如 Charles (https://www.charlesproxy.com/)或者 Fiddler (https://www.telerik.com/fiddler),来拦截微信 PC 端的网络请求。在众多的请求数据中,努力找到视频的 m3u8 或 mp4 直链。这就像是在一个巨大的信息宝藏中挖掘出我们需要的那颗宝石。只有精准定位到视频的真实链接,后续的下载操作才有可能顺利进行。
参数解析也是不容忽视的一环。微信视频链接往往带有加密参数,像 _wv、token 等。这些参数如同给视频链接加上了一把复杂的锁,需要我们动态提取或者逆向接口来解开这把锁。只有正确解析这些参数,才能确保我们发送的请求是有效的,进而成功获取视频资源。模拟请求则是利用 Python 发送 HTTP 请求,通过这个请求来下载视频流或文件,就像是派出一个使者去远方带回我们想要的东西。
实现步骤详解
抓包获取视频真实地址是实现下载的重要基础。在这一步,我们要做好工具准备,安装抓包工具,以 Charles 为例,安装完成后还需精心配置微信 PC 端代理。一切准备就绪后,打开微信 PC 端,播放我们想要下载的目标视频号内容。此时,抓包工具就像一个敏锐的观察者,开始记录所有的网络请求。我们要在众多请求中,仔细筛选出视频链接,通常它们是 mp4 或 m3u8 格式,这需要我们有一定的耐心和细心。
有了视频真实地址,接下来就是用 Python 代码下载视频了。给出的通用示例代码,虽然有一定的通用性,但需要根据实际抓包结果灵活调整参数。在代码中,我们不仅要设置好替换为抓包获取的真实视频地址,还要模拟微信客户端请求头。这个请求头就像是我们的身份标识,告诉服务器我们是正常的微信客户端请求。发送请求下载视频时,要根据服务器返回的状态码判断下载是否成功,成功则将视频内容写入文件,失败则输出相应的错误信息。
import requestsimport redef download_wechat_video():# 替换为抓包获取的真实视频地址(可能含动态参数)video_url = "https://example.weixin.qq.com/video/xxx.mp4?_wv=123&token=abc"# 模拟微信客户端请求头headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1326.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090621)","Referer": "https://example.weixin.qq.com/"}# 发送请求下载视频response = requests.get(video_url, headers=headers, stream=True)if response.status_code == 200:with open("video.mp4", "wb") as f:for chunk in response.iter_content(chunk_size=1024):if chunk:f.write(chunk)print("视频下载完成!")else:print("下载失败,状态码:", response.status_code)if __name__ == "__main__":download_wechat_video()
关键难点突破
动态参数,如 _wv 和 token,是实现微信视频号下载过程中的一大难点。这些参数就像变幻莫测的精灵,它们的存在给我们的下载工作带来了挑战。由于它们可能是短期有效的,所以我们需要逆向微信接口或者使用抓包工具实时捕获最新参数。只有这样,才能保证我们获取的视频链接始终是有效的,避免因为参数问题导致下载失败。在实际操作中,这需要我们不断尝试和探索,积累经验。
m3u8 视频流处理也是一个需要攻克的难关。如果视频是 m3u8 分片格式,我们不能直接下载,而是要先解析并合并 TS 文件。这就好比把一堆零散的拼图碎片拼接成完整的图案。通过引入专门的库,如 m3u8_downloader,我们可以更方便地完成这个任务。按照相应的代码示例,输入正确的 m3u8 链接和请求头,就能实现文件的下载,将碎片化的视频整合为一个完整的视频文件。
from m3u8_downloader import M3u8Downloaderm3u8_url = "https://example.com/video.m3u8"downloader = M3u8Downloader(m3u8_url, headers=headers)downloader.download("output.mp4")
如果视频需要登录权限,需在代码中附加 Cookie:
cookies = {"wxtoken": "xxx","session_id": "yyy"}response = requests.get(url, headers=headers, cookies=cookies)
注意事项强调
在使用 Python 实现微信视频号下载时,法律与版权问题必须引起我们的高度重视。我们要明确,这种操作仅限个人学习研究,绝对禁止将下载的内容用于商业用途或者随意传播他人的视频。这不仅是对版权所有者的尊重,也是我们作为合法公民应尽的义务。下载他人视频很可能违反微信的《服务协议》,一旦被发现,可能会面临各种处罚,所以我们一定要严守法律底线。
反爬机制也是我们需要小心应对的方面。微信为了保护自身的系统安全和数据稳定,设置了反爬机制。频繁的请求很可能导致 IP 被封禁或者账号受到限制,这会严重影响我们的正常使用。因此,我们要合理控制请求频率,避免过度请求。另外,动态参数如 token 可能在短时间内就失效,这就要求我们实时更新参数,确保请求的有效性,从而顺利完成视频下载。
替代方案推荐
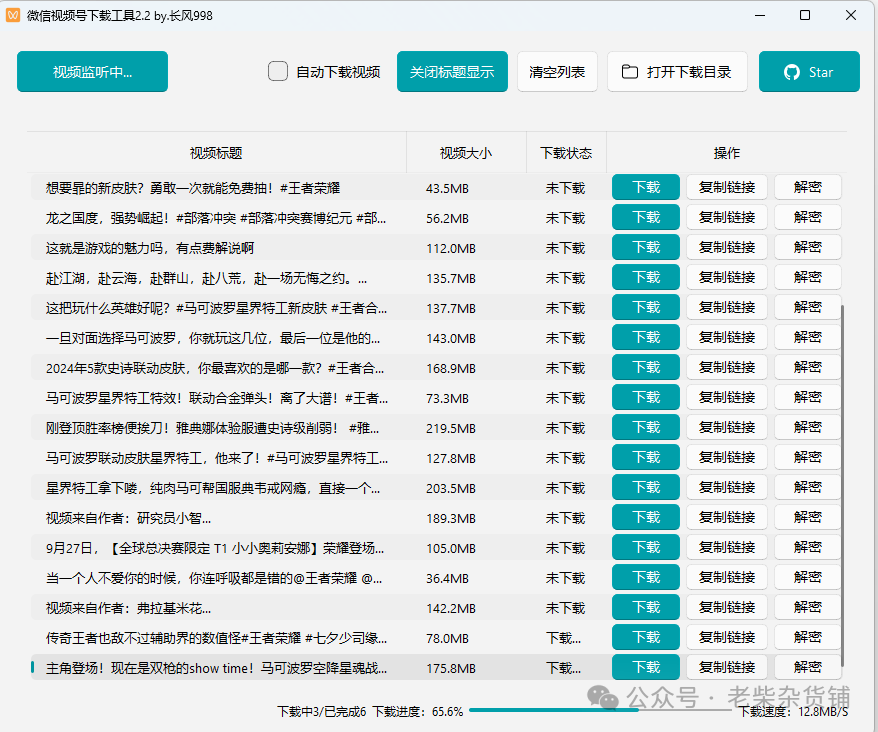
若不想在实现微信视频号下载的过程中花费过多精力去编写代码,重复造轮子,那么直接使用现成的开源工具是一个非常不错的选择。比如 WeChatVideoDownloader(https://github.com/qiye45/wechatVideoDownload),它的核心逻辑与我们前面介绍的代码类似,但已经将完整的功能进行了封装。这就好比我们不用自己动手去搭建一个复杂的工具,只需要直接使用别人已经精心打造好的成品,大大节省了我们的时间和精力。
使用这些开源工具,我们可以更轻松地实现微信视频号的下载。它们经过了众多开发者的测试和优化,在稳定性和功能上都有一定的保障。当然,如果我们对实现细节有更高的要求,比如逆向接口或者自动化监听等,还是需要结合抓包工具,仔细分析实际请求参数,进一步深入研究和探索,以满足我们更个性化的需求。
END

