




DrissionPage 是一个基于 Python 的网页自动化工具,结合了 requests 和 selenium 的优点,旨在简化网页操作和数据抓取流程。以下是关于 DrissionPage 的核心功能、使用场景及快速入门指南:
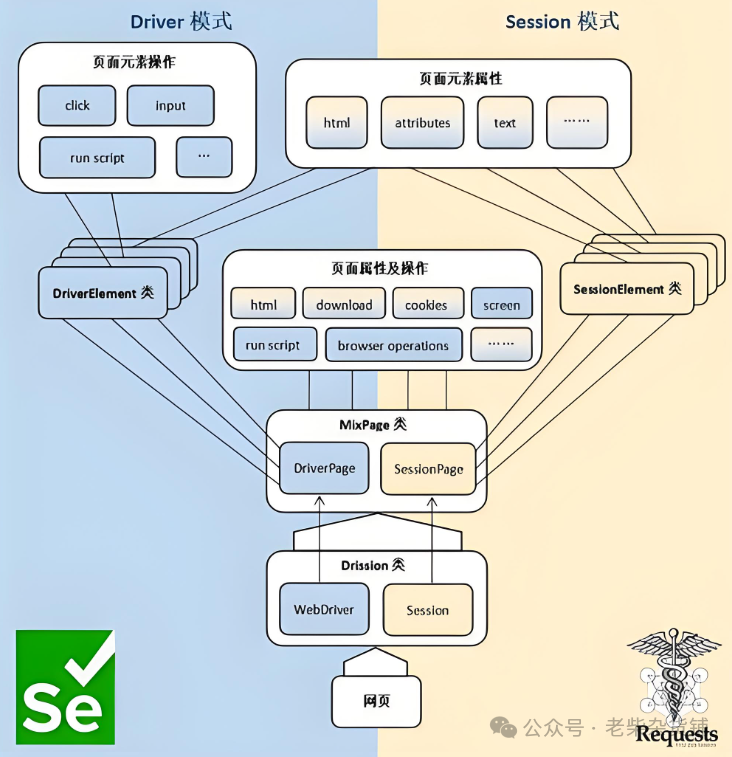
一、核心特点
双引擎驱动:
支持 requests(纯 HTTP 请求)和 WebDriver(浏览器自动化)两种模式,可自由切换。
自动管理 Cookies 和 Session,无缝衔接两种模式的操作。
简洁 API:
提供类似 jQuery 的链式语法,简化元素定位和操作。
支持同步和异步请求(需搭配 aiohttp)。
高效处理动态内容:
内置智能等待机制,自动处理动态加载的页面元素(如 Ajax 请求)。
支持直接解析 JavaScript 渲染的页面。
二、适用场景
数据抓取:高效爬取动态网页(如电商商品信息、社交媒体内容)。
自动化测试:模拟用户操作(登录、表单提交、点击验证)。
网页监控:定时检测网页内容变化(如价格变动、新闻更新)。
RPA 流程:集成到自动化工作流中,处理需要浏览器交互的任务。
三、快速入门
1. 安装
pip install drissionpage
2. 初始化浏览器(WebDriver 模式)
from drissionpage import ChromiumPage# 启动浏览器(自动下载驱动)page = ChromiumPage()page.get('https://www.example.com')
3. 元素定位与操作
# 通过 CSS 选择器定位搜索框并输入内容page.ele('#search-input').input('Python自动化')# 点击搜索按钮page.ele('#search-btn').click()# 获取搜索结果items = page.eles('.result-item')for item in items:print(item.text)
4. 切换为 Requests 模式(无头爬虫)
from drissionpage import SessionPagepage = SessionPage()page.get('https://www.example.com/api/data')# 直接解析 JSON 数据data = page.json()print(data)
四、进阶功能
1. 处理动态加载内容
# 等待元素出现(最多10秒)element = page.ele('#dynamic-content', timeout=10)print(element.text)
2. 文件下载
# 设置下载路径page.set.download_path('/path/to/download')# 下载文件page.download('https://example.com/file.pdf')
3. 异步请求(需安装 aiohttp)
from drissionpage import AsyncSessionPageasync def fetch_data():page = AsyncSessionPage()await page.get('https://api.example.com/data')print(await page.json())# 运行异步任务import asyncioasyncio.run(fetch_data())
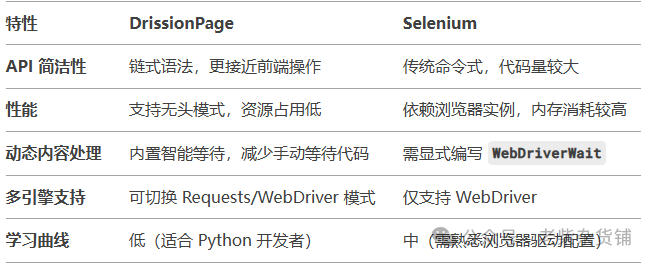
五、与 Selenium 的对比
六、常见问题
1. 如何解决证书错误?
page = ChromiumPage(ignore_certificate_errors=True)
2. 如何设置代理?
page = SessionPage(proxies={'http': 'http://127.0.0.1:1080'})
3. 如何处理验证码?
方案 1:手动介入(暂停脚本,人工输入)。
方案 2:集成第三方验证码识别服务(如打码平台)。
七、最佳实践
优先使用 Requests 模式:对于静态页面或 API 请求,无头模式更快更轻量。
合理使用等待机制:避免硬编码 time.sleep(),用内置智能等待提升稳定性。
异常处理:封装重试逻辑,应对网络波动或封禁。
from drissionpage.common import retry@retry(times=3)def safe_get(url):page.get(url)
官方资源
文档:DrissionPage 官方文档:https://drissionpage.cn/
GitHub:https://github.com/g1879/DrissionPage
社区支持:通过 GitHub Issues 或 QQ 群(文档中提供)提问。
总之,针对爬取“所见即所得”网页信息,DrissionPage有一定的优势:
1、结合DevTools的Xpath元素拷贝,实现“所见即所得”
2、绕过检测,免去header缠绕的烦恼
3、监听、拦截信息包,获得完整的信息
4、随时接管浏览器,实现目标抓取。
