官方链接:https://huggingface.co/,但是官方网站需要科学,有一个国内镜像网站同样可用:https://hf-mirror.com/models
一、什么是Hugging Face
Hugging Face 是一个开源的机器学习平台,专注于自然语言处理(NLP)和人工智能(AI)。它提供了模型、数据集(文本、图像、音频、视频)、类库(比如transformers、datasets、accelerate)和教程等资源。
Hugging Face 起初是一家总部位于纽约的聊天机器人初创服务商,后来因为开源了一个Transformers库而在机器学习社区迅速火起来,目前已经共享了超过100,000个预训练模型和10,000个数据集,变成了机器学习界的github。
Hugging Face的成功不仅仅在于技术,还在于它构建了一个强大的开发者社区。通过开源项目和在线平台,Hugging Face鼓励开发者分享模型、数据集和代码。这种开放协作的模式,使得AI技术能够以更快的速度迭代和优化。
Hugging Face的Model Hub是一个典型的例子。这是一个在线平台,开发者可以在这里上传和下载预训练的AI模型。目前,Model Hub上已经有数万个模型,涵盖了从文本生成到图像识别的多种任务。这种“模型即服务”的模式,极大地降低了AI开发的门槛。
此外,Hugging Face还推出了Spaces功能,允许开发者快速构建和部署AI应用。无论是个人开发者还是企业用户,都可以通过Spaces展示自己的AI项目,并与全球用户互动。
二、Hugging Face 的核心特点
合作平台:提供无限模型、数据集和应用程序的托管和协作服务。
加速机器学习:通过其开源堆栈,帮助用户加速机器学习项目。
多模态探索:支持文本、图像、视频、音频甚至3D内容的机器学习任务。
构建个人作品集:用户可以共享自己的工作,构建自己的机器学习作品集。
企业级服务:提供企业级安全性、访问控制和专业支持的高级平台,帮助企业构建AI。
广泛应用:超过50,000个组织正在使用Hugging Face,其中包括Allen Institute for AI、Meta、Amazon Web Services、Google、Intel、Microsoft等。
开源精神:Hugging Face秉承开源精神,与社区一起构建机器学习工具的基础。
Hugging Face 社区包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。目前包括模型236,291个,数据集44,810个。
Hugging Face 也提供了一些核心组件,如Transformers、Dataset、Tokenizer等,这些组件支持了预训练的语言模型和相关工具,使得研究者和工程师能够轻松的训练和使用海量的NLP模型。
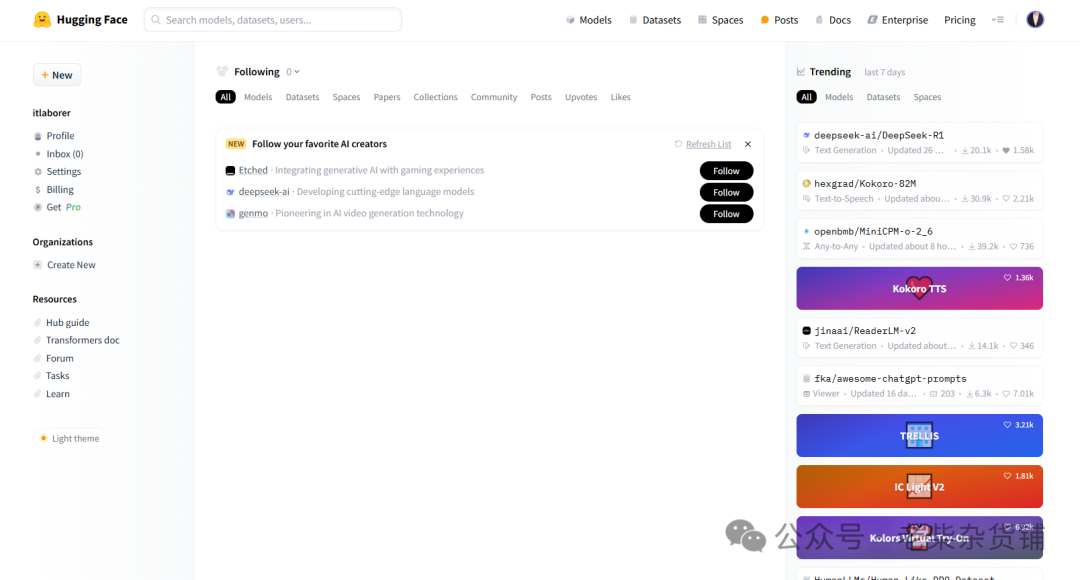
Models(模型),包括各种处理CV和NLP等任务的模型,上面模型都是可以免费获得
Datasets(数据集),包括很多数据集
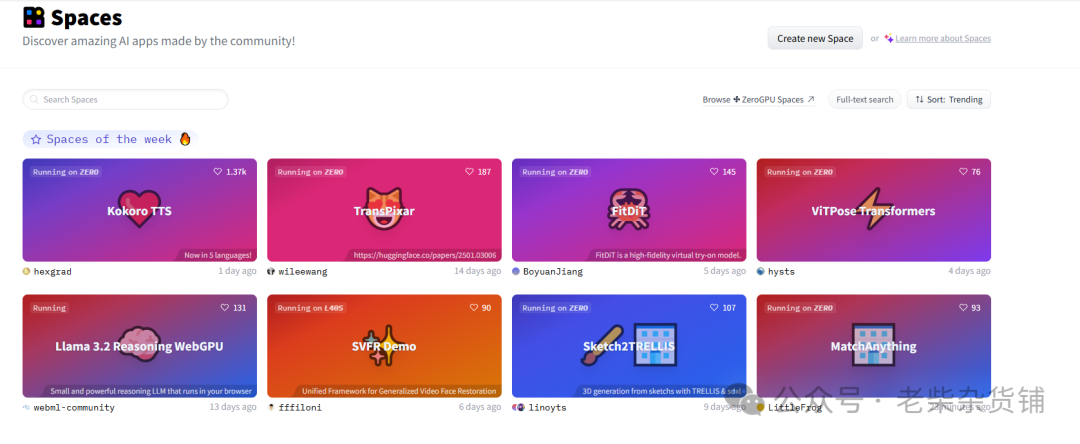
Spaces(分享空间),包括社区空间下最新的一些有意思的分享,可以理解为huggingface朋友圈,嗯,这儿有好东西,重点关注下
Docs(文档,各种模型算法文档),包括各种模型算法等说明使用文档
Solutions(解决方案,体验等),包括others
Pricing(dddd) ,懂的都懂
四、查看model并使用api
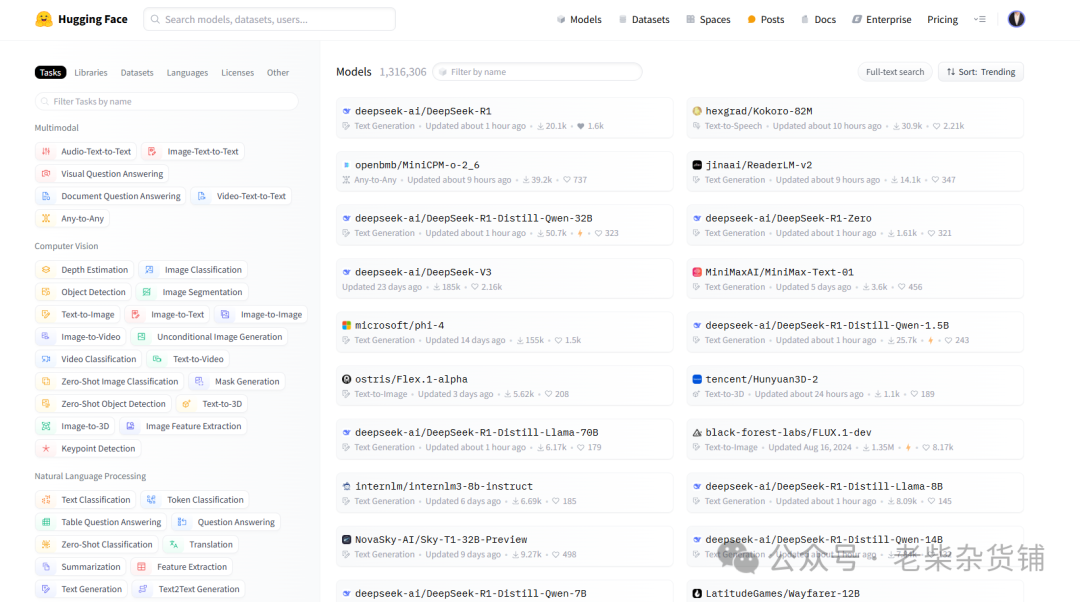
在model界面可以看种开源模型,比如最近比较火的deepseek r1
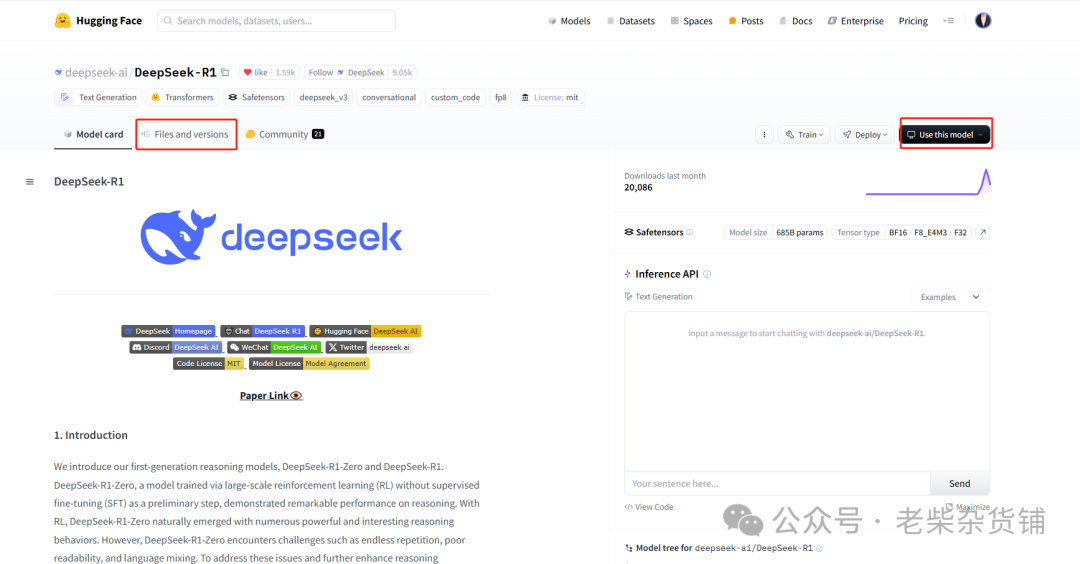
files and versions可以查看源码,不过只能一个一个文件下载。。。。。或者用git clone下载
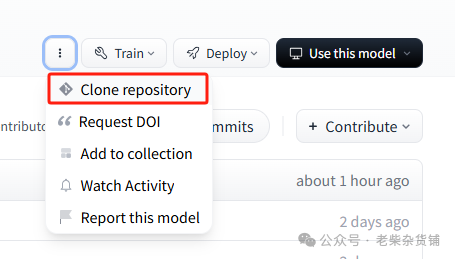
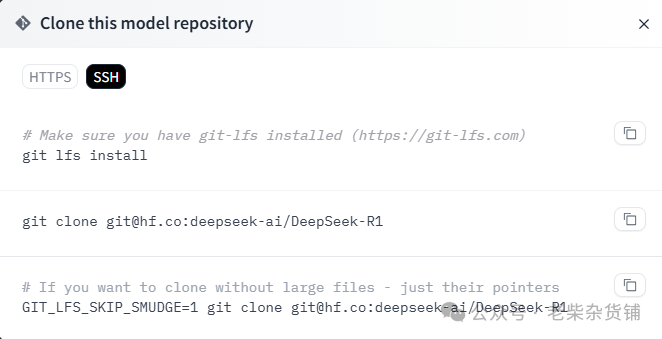
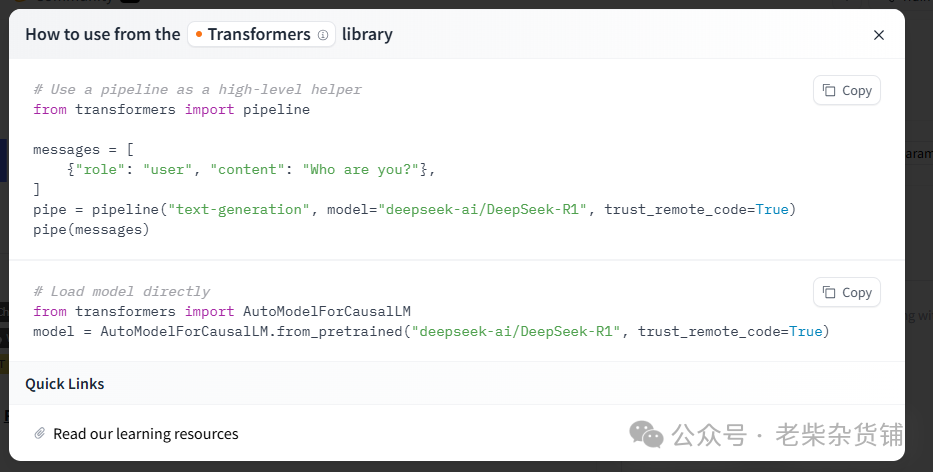
use this model可以查看接口调用方法,默认使用transformers方式
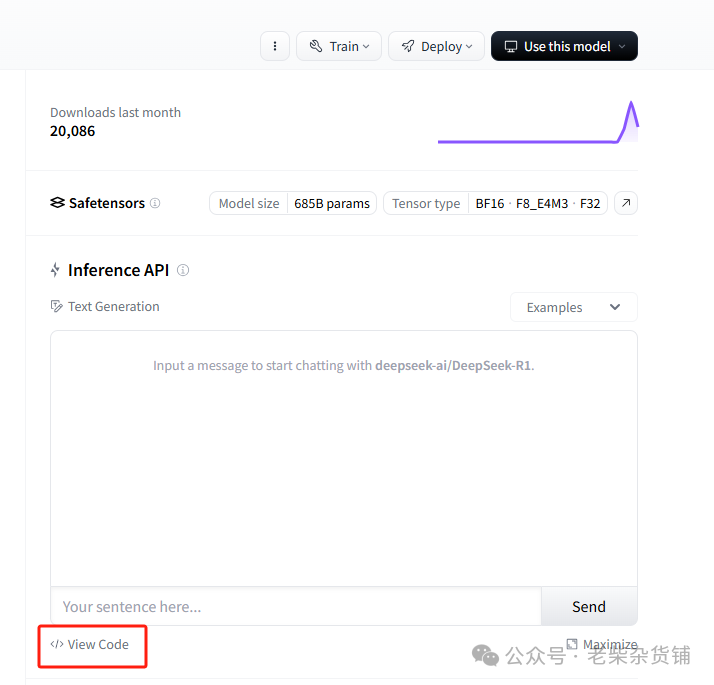
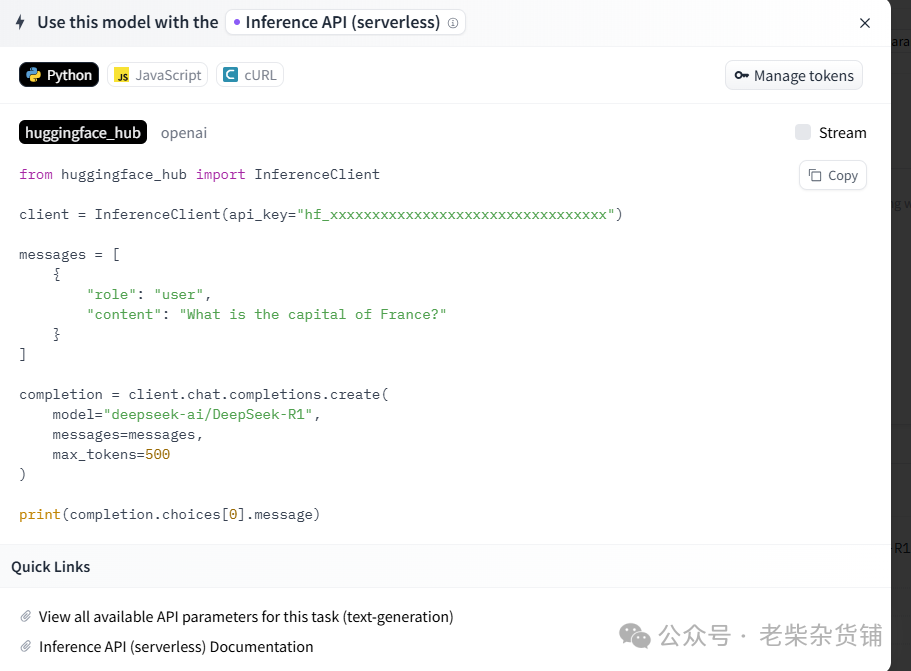
推荐使用国内镜像站hf-mirror,网站主页有教程,也可以写成下面的脚本自动下载(脚本已经实现网络错误后,自动续下)。需要提前安装huggingface_hubpip install -U huggingface_hub#下面脚本在linux环境下,保存为download_model.sh,然后直接命令行./download_model.sh#!/bin/bash# 把openai-community/gpt2换成自己的需要下载的模型,例如ALmonster/braingpt-1.0等,--local-dir可以指定保存路径export HF_ENDPOINT=https://hf-mirror.comCOMMAND="huggingface-cli download --resume-download openai-community/gpt2 --local-dir openai-community/gpt2"# 循环执行命令,直到成功while true; do$COMMANDif [ $? -eq 0 ]; thenecho "Command executed successfully."breakelseecho "Command failed, retrying..."sleep 5 # 可选:等待5秒后重试,避免过于频繁的重试fidone
六、模型使用方法
需要提前安装transformers库,可以直接pip install transformers安装。还有Pytorch或TensorFlow库,请自行下载。
下载完后可以使用pipeline直接简单的使用这些模型。第一次执行时pipeline会加载模型,模型会自动下载到本地,可以直接用。第一个参数是任务类型,第二个是具体模型名字。
from transformers import pipelineunmasker = pipeline('fill-mask', model='bert-base-uncased')unmasker("Hello I'm a [MASK] model.")#模型下载在本地的地址:C:\Users\【自己的用户名】\.cache\huggingface\hub
当然,不同模型使用方法略有区别,直接通过页面学习或文档学习最好(一般都有介绍)
#可以自定义加载输入分词器:使用AutoTokenizerfrom transformers import AutoTokenizer#下面这种方式可以自动加载bert-base-uncased中使用的分词器tokenizer=AutoTokenizer.from_pretrained("bert-base-uncased")#可以自定义加载模型结构:使用AutoModel#不包括输入分词器和输出部分!!!from transformers import AutoModel#下面这种方式可以自动加载bert-base-uncased中使用的模型,没有最后的全连接输出层和softmaxmodel=AutoModel.from_pretrained("bert-base-uncased")#可以自定义加载模型和输出部分:使用AutoModelForSequenceClassification等from transformers import AutoModelForSequenceClassification#下面这种方式可以自动加载bert-base-uncased中使用的模型(包括了输出部分),有最后的全连接输出层model=AutoModel.AutoModelForSequenceClassification("bert-base-uncased")#模型保存model.save_pretrained("./")#保持到当前目录
七、下载数据集方式
下载数据集脚本如下,也使用国内镜像下载,保存为download_dataset.sh,然后直接命令行./download_dataset.sh
#!/bin/bash# 把TigerResearch/pretrain_zh换成需要的路径export HF_ENDPOINT=https://hf-mirror.comCOMMAND="huggingface-cli download --repo-type dataset --resume-download TigerResearch/pretrain_zh --local-dir TigerResearch/pretrain_zh"# 循环执行命令,直到成功while true; do$COMMANDif [ $? -eq 0 ]; thenecho "Command executed successfully."breakelseecho "Command failed, retrying..."sleep 5 # 可选:等待5秒后重试,避免过于频繁的重试fidone
或者直接在页面查看使用方式:
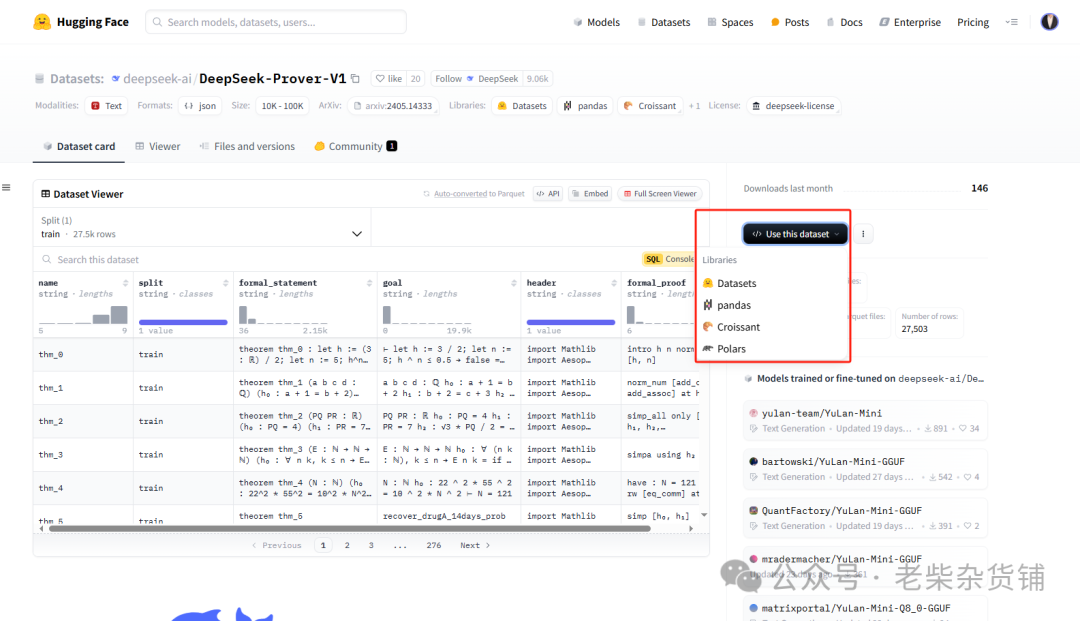
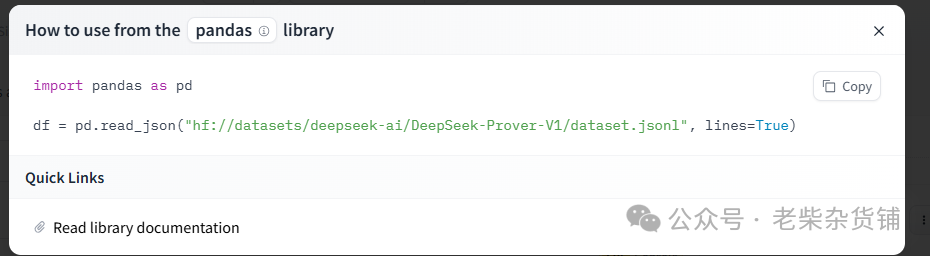
导入数据集方法(提前pip install datasets)
from datasets import load_datasetdatasets=load_dataset("glue","mrpc")#glue下还有其他数据集print(datasets)train_data=datasets['train']print(train_data[0])
八、训练模型方法
#下面给出bert-base-uncased的例子,实现对两个句子的相似度计算#导入tokenizerfrom transformers import AutoTokenizertokenizer=AutoTokenizer.from_pretrained("bert-base-uncased")#https://huggingface.co/bert-base-uncased#input=tokenizer('The first sentence!','The second sentence!')#测试#print(tokenizer.convert_ids_to_tokens(input["input_id"]))#实际使用tokenizer的方法,得到tokenizer_datadef tokenize_function(example):return tokenizer(example["sentence1"],example["sentence2"],truncation=True)from datasets import load_datasetdatasets=load_dataset("glue","mrpc")tokenizer_data=datasets.map(tokenize_function,batched=True)print(tokenizer_data)#训练参数from transformers import TrainingArgumentstraining_arg=TrainingArguments("test-trainer")#训练参数,可以自己去改,参数意思参考https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArgumentsprint(training_arg)#看下默认值#导入模型from transformers import AutoModelForSequenceClassificationmodel=AutoModelForSequenceClassification.from_pre_trained("bert-base-uncased",num_labels=2)#num_labels自己定义了,所以不会导入输出层#导入数据处理的一个东西DataCollatorWithPadding,变成一个一个batchfrom transformers import DataCollatorWithPaddingdata_collator=DataCollatorWithPadding(tokenizer=tokenizer)#导入训练器,进行训练,API : https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Trainerfrom transformers import Trainertrainer=Trainer(model,training_arg,train_dataset=tokenizer_data["train"],eval_dataset=tokenizer_data["validation"],data_collator=data_collator,tokenizer=tokenizer)trainer.train()
最近一周比较火的模型,有空可以研究一下