




Telegraf 是 InfluxData 的插件驱动的服务器代理,用于收集和报告指标。目前有超过200个输入插件,这意味着有很多方法可以将数据写入到InfluxDB中。然而,我经常看到新 Influx 用户在 InfluxData 社区站点上询问如何将数据从CSV写入到InfluxDB。从一个CSV文件来写入数据是将同样的数据插入到 InfluxDB 的一种简单方法,这可以使你更容易地熟悉这个平台。
将数据从CSV 导入到InfluxDB中的需求和设置
在之前的博客(https://www.influxdata.com/blog/getting-started-writing-data-to-influxdb/ )中,我分享了三种向数据库插入数据的简单方法(包括一个将CSV数据转换为行协议的Python脚本,line protocol(行协议)是InfluxDB的数据提取格式)。本博客是关于如何使用Telegraf文件输入插件从CSV中写入数据的指南。Telegraf文件输入插件写入数据的速度比Python脚本快,这在执行批量导入时非常有用。通过它,我希望消除新用户可能产生的任何困惑。我假设你是一个MacOS用户,并且使用Homebrew安装了InfluxDB 和 Telegraf,因为这是在本地启动和运行它们的最快方式(或者,你可以从我们的下载页面下载二进制文件,或者运行sandbox)。
随附的这篇博客文章的仓库源可以在这里(https://github.com/Anaisdg/csv_to_influxdb )找到。要从CSV写入数据,我们将使用带有CSV解析器的文件输入插件。
要求:
Telegraf 1.8.0 或更高版本
InfluxDB 1.7.0或更高版本
安装完成后,在终端中键入以下命令,确保InfluxDB正在运行并且Telegraf已经停止运行: brew services list。

如果你没有看到InfluxDB正在运行,请执行brew services start influxdb来启动它。类似地,如果Telegraf正在运行,你可以使用brew services stop telegraf来停止该服务。
首先,我需要下载一个带有合适的输入和输出插件的Telegraf配置文件。根据Telegraf文档的“开始使用Telegraf”章节,我将在我选择的目录的终端中使用以下命令。

-sample-config标记将生成telegraf配置文件。-input-filter和-output-filter标记分别指定数据的输入源和输出源。>后面的文本用来命名配置文件。我发现在我正在使用的telegraf插件后面使用它来命名我的telegraf配置文件非常有用,这样我以后就能很容易地区分我的配置文件了。运行命令后,我打开file.conf。我发现我的telegraf配置总共有454行,并已经配置好了文件输入插件和InfluxDB输出插件。
通过四步来将CSV数据提取到InfluxDB中
第一步: 我对配置文件所做的第一个更改位于Output Plugins部分。我想为我的CSV数据指定目标数据库。我将把第97行从默认的# database = "telegraf"更改为database = csv(或者我选择的任何数据库的名称,以便我可以轻松地找到csv数据)。
我的csv数据看起来像这样:
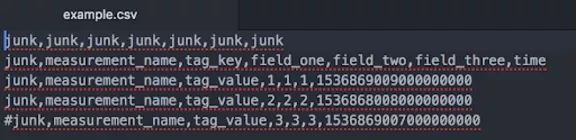
第一行和第一列都是junk。我还把最后一行注释掉了。我的时间戳是Unix时间,精度为纳秒(ns)。在第二步中,我通过在配置文件中添加一些行来确保不会在数据提取中包含这些行和列。
第二步: 接下来,我想对配置文件中的Input Plugins部分进行配置。首先,我将在telegraf配置文件的第455行中指定我的csv文件的所在路径。因为我的配置文件与csv在同一个目录中,所以第455行只是我的文件名: files = ["example"](否则请确保引入完整的$pwd)。我还将在我的配置文件底部的Input Plugins部分添加以下几行,以确保只提取我关心的数据:
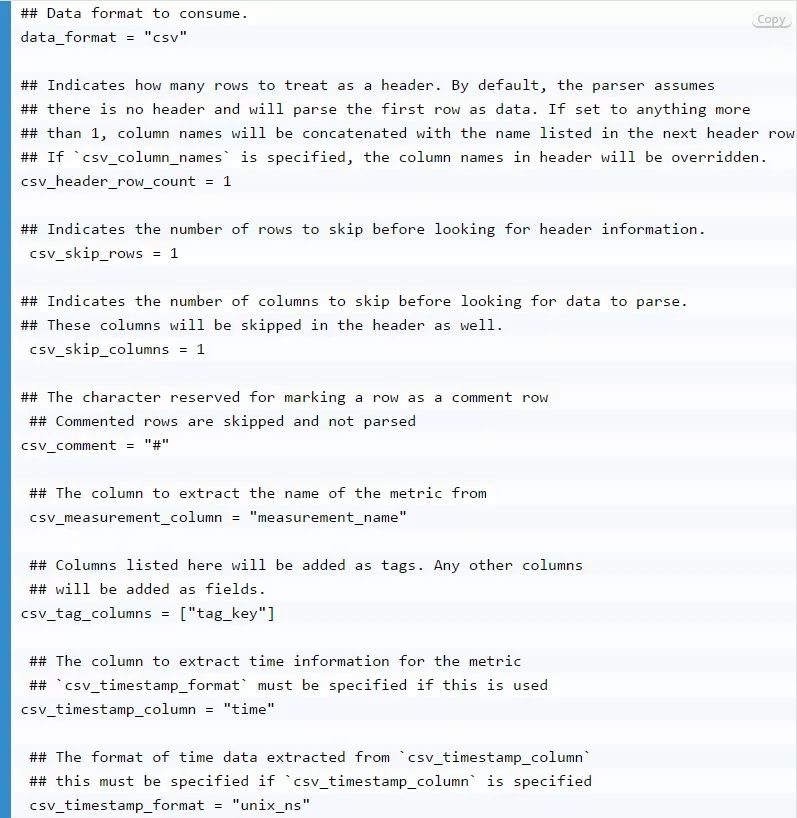
额外的配置选项: 还是有必要在配置文件中查看一下几个其他变量。
第36行默认为metric_batch_size = 1000。它控制Telegraf发送到InfluxDB的写入数据的大小。如果要执行批量数据导入,可能需要增加该值。要确定合适的metric_batch_size,我建议你查看这些“硬件尺寸指南(https://docs.influxdata.com/influxdb/v1.6/guides/hardware_sizing/#general-hardware-guidelines-for-a-single-node )”。最后,如果你正在使用OSS版本并试图导入几十万个数据点,请查看如何启用TSI。启用TSI可以提高一系列cardinality(基数)性能。查看这个链接(https://docs.influxdata.com/influxdb/v1.7/administration/upgrading/ ),了解如何在InfluxDB 1.7中启用TSI。
第69行默认为debug = false。如果你在将数据点写入到InfluxDB时遇到问题,请将debug变量设置为true来获取调试日志消息。
第三步: 在你的终端中复制粘贴以下代码来用我们刚刚编辑的配置文件运行Telegraf:

如果你设置了debug = true,那么你会看到以下输出:
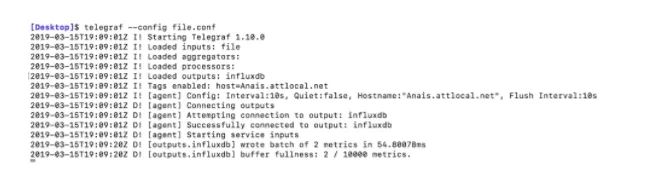
第四步: 现在我们准备好来查询数据了。你可以在终端中运行influx来启动influx shell。
运行 use csv来选择数据库,并通过以下查询来验证数据插入是否成功: select * from measure rement_name limit 3。使用precision rfc3339将时间戳转换为人可读的格式。
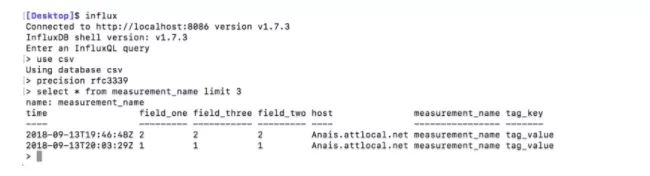
这就是配置文件输入插件并从CSV文件中将数据写入到InfluxDB的全部过程。请注意,文件输入插件接受许多其他数据格式,包括:json、行协议和collectd,仅举几个例子。如果你需要更多有关使用CLI的帮助,请参阅此文档(https://docs.influxdata.com/influxdb/v1.7/tools/ )。
结论
最后,我强烈推荐使用Telegraf插件来将数据写入你的数据库,因为Telegraf是用Go编写的。Go比Python快得多,但是如果你决心使用Python,我建议你查看这个csv-to-influxdb仓库源。最后,Telegraf有tagpass /tagdrop/ fieldpass /fielddrop配置参数,这些参数可以用于任何输入来筛选并指定哪些标签和字段将被传递。它们还允许你选择将哪些数据包含在提取结果中。而且,Telegraf是完全开源的。我鼓励你学习如何编写自己的Telegraf插件,并贡献新的插件,如果你愿意的话!
希望本教程能开启你的Influx之旅。如果你有任何问题,请在社区站点发文或推特联系我们@InfluxDB。
英文原文:https://www.influxdata.com/blog/how-to-write-points-from-csv-to-influxdb/?utm_campaign=javascript&utm_medium=newsletter&utm_source=cooperpress
译者:天天向上
