





我们很高兴地宣布,Meta 最新一代大模型 Llama 4 系列现已正式登陆 Azure AI Foundry(国际版)和 Azure Databricks!这意味着开发者可以在 Azure 上直接使用 Llama 4 构建更个性化、跨模态的 AI 应用。
该模型采用创新架构,能够将文本和图像无缝整合至统一的模型骨干中。这种设计使开发者能够在需要处理海量未标注文本、图像和视频数据的应用中充分发挥 Llama 4 的潜力。
此次上线的模型包含 Llama 4 Scout 模型和 Llama 4 Maverick 模型,您可以直接在 Azure AI Foundry(国际版)中作为托管计算资源(Managed Compute)使用。
Llama 4 Scout 模型
Llama-4-Scout-17B-16E
Llama-4-Scout-17B-16E-Instruct
Llama 4 Maverick 模型
Llama-4-Maverick-17B-128E-Instruct-FP8
Azure AI Foundry(国际版)专为多智能体(multi-agent)应用场景打造,能够支持多个 AI 智能体之间的无缝协作。这项能力为 AI 应用开辟了全新领域,从复杂问题求解到动态任务管理都将受益匪浅。
设想一下,您有一组 AI 智能体:
一个负责分析数据
一个负责撰写内容
一个负责校对和优化
一个实时抓取外部信息
这些智能体就像一个虚拟团队,可以互相协作、分工处理复杂任务。
为了满足不同的使用场景和开发需求,Llama 4 提供了大小不同的模型版本。既适合在轻量化环境中部署,也能胜任高强度算力需求的复杂任务。
更重要的是,Llama 4 在模型开发的每一个阶段(从预训练、微调到部署)都集成了安全防护机制,帮助开发者抵御潜在的攻击或应对潜在的风险。
Llama 4 还支持系统级的可调式防护,开发者可以根据应用需求灵活调整,让模型既保持高性能,也更加可靠、可控、安全。无论您是在做聊天助手、内容生成,还是企业内部自动化任务,Llama 4 都能提供稳定、可信赖的体验。
#1
Llama 4 Scout 模型:
性能与精度的双重提升
Llama 4 Scout 模型性能远超 Llama 3,还能在单张 H100 GPU 上运行,性能和效率兼顾,是当前最强的轻量级多模态模型之一。其最大亮点是 —— 上下文长度直接拉到了惊人的 1000 万 tokens,远超行业普遍的几十万 token 水平。这意味着它可以:
🔍 支持跨多个文档的内容整合与摘要生成
📊 能够理解用户的长时间行为数据并个性化响应
🧠 在海量代码库或知识库中进行复杂推理
在摘要生成、个性化推荐、多文档理解等场景中,Llama 4 Scout 表现尤为突出。它不仅能“读得多”,还能“记得住、理得清”,为开发者提供更真实、更贴近实际业务的 AI 能力。
比如说,它可以一次性“读完”整个企业 SharePoint 文档库,精准回答您提出的查询;也可以阅读一份长达几千页的技术手册,提供故障排查建议。正如它的名字 —— Scout(侦察兵),它就是为了在信息密集的场景中帮您高效“打前站”,您只需一句 prompt,它就能穿梭于海量数据,提炼关键内容,提供精准答案。
#2
Llama 4 Maverick 模型:
实现大规模创新
作为一款通用型大型语言模型,Llama 4 Maverick 拥有活跃参数 170 亿、专家网络 128 个、总参数量高达 4000 亿,相较于 Llama 3.3 的 70B 模型,它在保持高质量性能的同时,具备更高的性价比。
Maverick 在图像与文本理解方面表现尤为出色,支持多达 12 种语言,特别适合需要跨语言、高质量表达的应用场景。它非常适合用于图像精准识别和创意写作,是构建通用助手和聊天场景的理想选择。对于开发者而言,Maverick 提供了领先的智能表现与响应速度,并针对回答的质量与语气进行了优化,带来更加自然、贴切的交互体验。
重点应用场景包括:
多语言客服助手,支持识别用户上传的图像;
AI 创作伙伴,能与用户用多种语言对话并协作创作内容;
企业内部智能助手,支持多模态输入,回答员工的各种问题。
Maverick 是 Llama 4 家族中的旗舰聊天模型,您可以把它理解成“多语言 + 多模态 + 聊天能力全面进化版”的对话式智能助手。它在对话中的表现更加自然、有礼貌,也更贴近真实人类沟通风格。
借助 Maverick,企业可以构建出高质量的智能助手,不仅能够与全球用户进行自然且礼貌的对话,还能在需要时利用视觉感知能力提供更精准的服务。
#3
Llama 4 的架构创新:多模态
早期融合与 MoE 高效加速
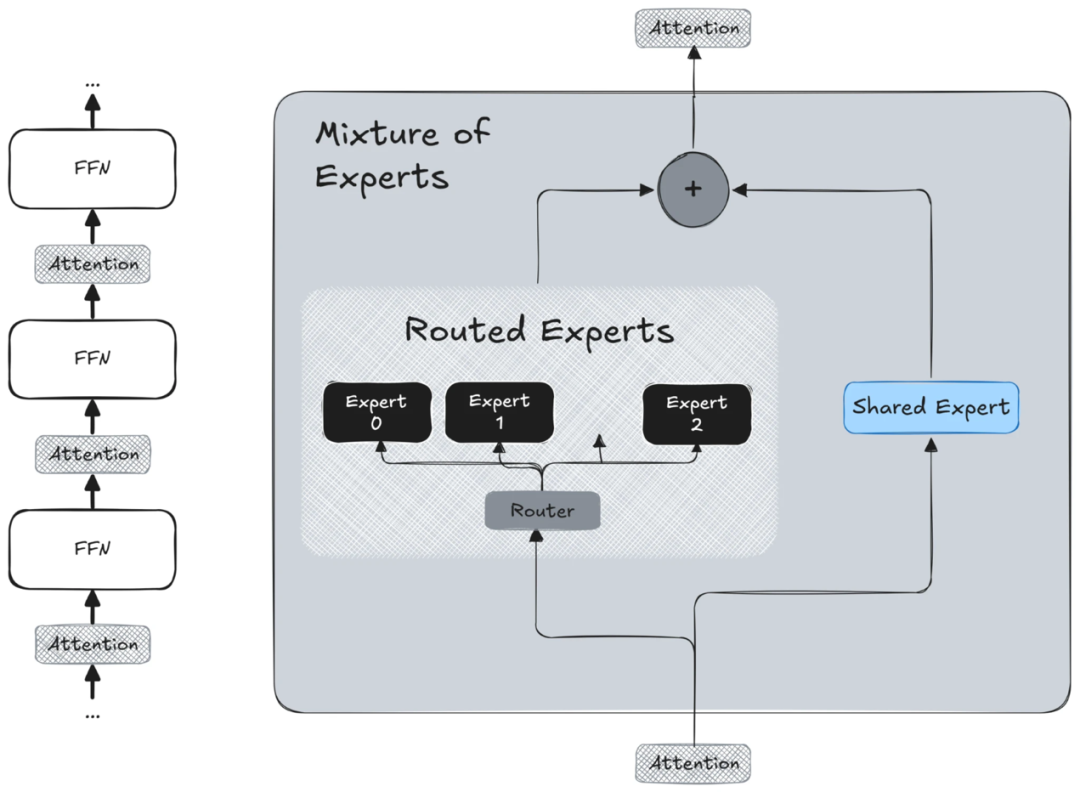
Meta 最新发布的 Llama 4,具备两项核心创新,使其在众多模型中脱颖而出:一是原生支持多模态并采用早期融合机制,二是采用更高效、更易扩展的混合专家(MoE)架构。
多模态早期融合:图文视频统一理解、处理
Llama 4 采用早期融合的方法,从一开始就将文本、图像和视频帧视为统一的 token 序列进行处理。这使模型能够从一开始就能统一处理各种信息,从而更擅长处理多模态任务。
比如说,用户上传一份包含图表和说明的报告,或是一个有字幕的视频片段,Llama 4 不但能看懂图、读懂文字,还能结合语境给出总结或者答案。对企业来说,这意味着智能助手可以一次性处理图文视频混合内容,输出结构化信息或摘要,大幅提升信息处理的效率与质量。
MoE 架构:按需调度专家,性能效率双提升
Llama 4 采用了专家混合(MoE)的架构。简单说,这个模型里内置了很多“子模型专家”,每次处理输入时,只激活其中一小部分最合适的专家。这样的设计不仅提高了训练效率,还增强了推理阶段的可扩展性。通过将计算负载分配给不同的专家子模型,Llama 4 能够同时处理更多请求,使其能够在生产环境中运行,而无需依赖大型单一 GPU 实例。
对企业来说,这意味着用更低的成本,也能获得强大的模型能力,无论是部署在云端,还是落地到本地环境,都更加灵活易用。
#4
致力于安全性与最佳实践
在构建 Llama 4 时,Meta 严格遵循了其《AI 安全使用指南》中的最佳实践,从模型预训练、微调到上线部署,每一个环节都内置了安全防护机制。同时,系统层面也加入了可调节的安全策略,用于抵御潜在的攻击或滥用。
此外,通过将这些模型部署在 Azure AI Foundry (国际版)平台,开发者还可以依托 Azure 提供的企业级安全保障机制,获得他们所期望的稳定、安全的开发环境。
#5
立即使用
Meta Llama 4 现已在 Azure AI Foundry(国际版)和 Azure Databricks 上正式发布,请扫描下方二维码根据自身需求选择合适的平台。
登录 Azure AI Foundry 浏览模型目录体验 Llama 4:

访问 Azure Databricks 探索新的 Llama 4:


