




本文对中国人民大学、清华大学、腾讯云数据库团队联合编写的2024SIGMOD论文《SALI: A Scalable Adaptive Learned Index Framework based on Probability Models》进行解读,文共4993字,预计阅读需要20至30分钟。
在大数据时代,随着数据量呈指数级增长,高效索引数据结构对于大数据系统至关重要。传统基于树的索引在性能和内存效率上存在局限,学习型索引应运而生。然而,现有学习型索引在高并发场景下存在可扩展性问题。本文提出SALI(Scalable Adaptive Learned Index)框架,旨在解决这些问题。SALI通过设计轻量级概率模型和节点进化策略,提升学习型索引的可扩展性、效率和鲁棒性。实验表明,SALI在插入吞吐量和查找吞吐量方面表现出色,相比其他学习型索引有显著优势。
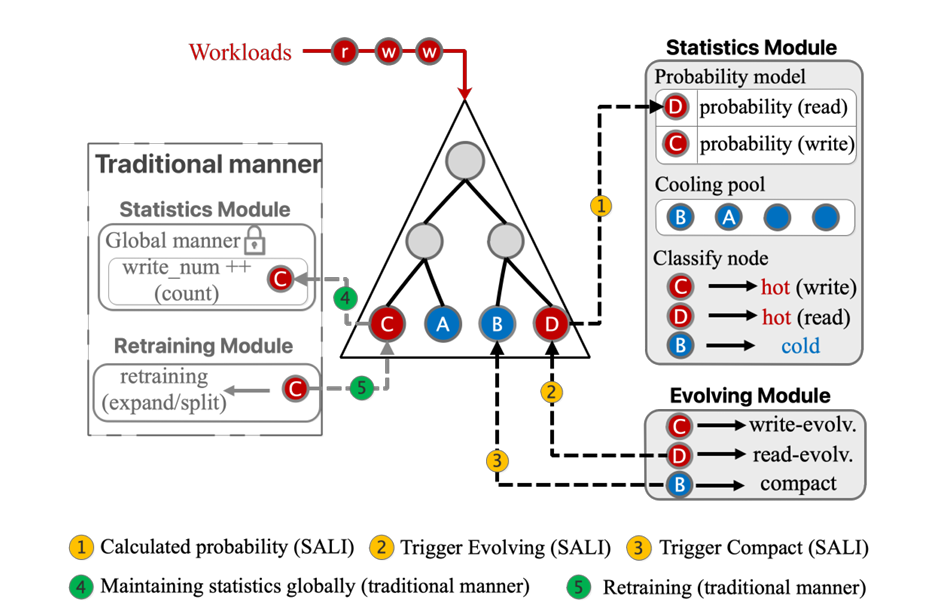
SALI框架结构
1.1学习型索引原理
学习型索引核心是利用一组学习模型估计存储数据的累积分布函数(CDF),以此预测数据存储位置。每个节点(或仅最低层叶节点)存储线性函数的斜率和截距,对应线性模型负责近似目标键位置,减少传统树型索引中的间接搜索操作,有望显著提升索引查找性能。
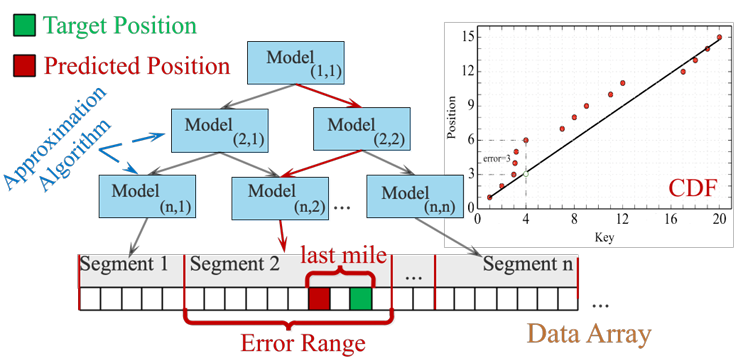
学习型索引方案
1.2索引结构可扩展性评估
现有学习型索引在单线程环境性能良好,但并发性能存在瓶颈。其插入策略主要有基于缓冲区的插入(如XIndex、FINEdex)和基于模型的插入(如ALEX、LIPP)。

学习索引中的更新策略
1.2.1缓冲区策略(离线插入)
基于缓冲区的策略因密集存储键(无间隙)导致误差大。实验表明,精确查找可提升并发性能,细粒度锁有助于插入可扩展性,但维护统计信息可能限制索引可扩展性。新数据先写入缓冲区,满溢后合并到上层段并重建模型。
问题:存储密集导致预测误差大,并发时 “最后一英里” 搜索消耗大量内存带宽(如XIndex、FINEdex)
1.2.2模型策略(原地插入)
基于模型的策略中,“移位” 方法(ALEX)在冲突时移动键会引入误差,“链式” 方法(LIPP)虽避免数据移动,但维护统计信息会引发线程争用和缓存行乒乓问题。
移位法(如ALEX):冲突时移位现有键以插入新键,需粗粒度锁保护节点,线程竞争导致阻塞。
链式法(如LIPP):冲突时创建子节点,避免数据移动(精准查询),但需维护节点统计信息(如访问计数),引发缓存行乒乓效应。
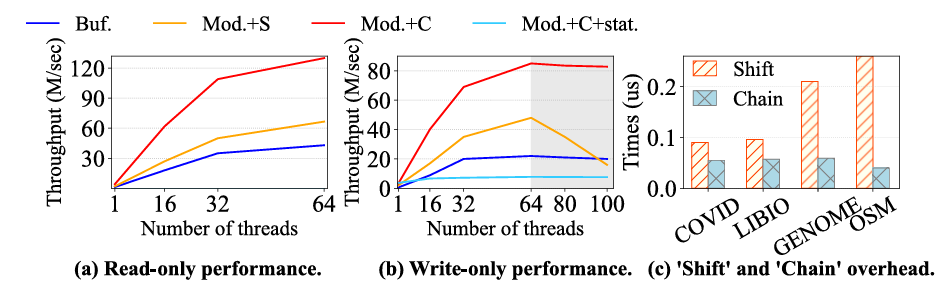
(a)只读模式表现图(b)只写模式表现图(c)移位和链模式开销图
上图展示了三种结构的性能。基于缓冲区的结构用𝑏𝑢𝑓.表示(即XIndex的结构),基于模型的Shift方法策略用𝑀𝑜𝑑.+𝑆表示(即ALEX的结构),基于模型的Chain方法策略用𝑀𝑜𝑑.+𝐶表示(即LIPP的结构)
1.3可扩展索引需求
为实现可扩展性,学习型索引应满足多方面要求。
高效并发:轻量级统计维护:避免全局统计的高竞争(如 LIPP + 的计数器导致缓存行乒乓)。
细粒度锁设计:减少插入时的键操作,降低线程阻塞(如链式法优于移位法)。
自适应性:工作负载感知:针对读写热点动态调整结构(如扩展写热点节点、扁平化读热点子树)。
空间优化:压缩冷节点以减少内存占用。
低开销基础性能:精准预测:避免 “最后一英里” 搜索(链式法优于移位法和缓冲区策略)。
原地插入:模型策略优于缓冲区策略,减少数据移动和重建成本。
2.1概述
2.1.1 框架结构
SALI框架包含基于概率的轻量级统计维护方法和自适应进化策略。基于Mod.+C(LIPP结构)构建在考虑的选项中具有最高的可扩展性。
建立在Mod.+C的SALI模型
基于LIPP的链式法,支持细粒度锁和精准查询,作为验证两种核心策略的载体。
概率模型:轻量级统计维护,替代传统全局计数器,计算节点进化的触发概率(如插入速率、冲突概率)。
进化策略:根据概率模型分类节点为 “热”(读写频繁)或 “冷”(极少访问),执行扩展、扁平化或压缩操作
SALI利用基于概率的轻量级方法来维护统计信息,同时保持节点重新训练/进化的时间准确性,不会阻塞多个线程的插入操作
2.1.2 SALI关键操作
查询:线性模型预测位置,热节点用SIMD加速定位,冷节点用二分搜索处理误差(算法1)。
插入:预测位置为空则直接插入,冲突时创建子节点(算法2),避免数据移动和粗粒度锁。
进化:通过RCU机制避免读阻塞,确保并发安全(如节点重构时读取旧版本数据,完成后切换到新版本)。
构建操作:ALI利用LIPP的构建最快最小冲突度(FMCD)。在SALI中,非线性近似算法是未来研究的至关重要且引人入胜的途径。
2.1.2 SALI不同操作之间的协调
SALI验证正在读取的项目(即数据或子指针)未被修改,读取操作就可以在不获取锁的情况下进行。并发写入时针对目标槽位采用锁机制,只有细粒度锁才能保证互斥写入,因此在均匀的工作负载下,写入冲突很少发生。
2.2进化策略
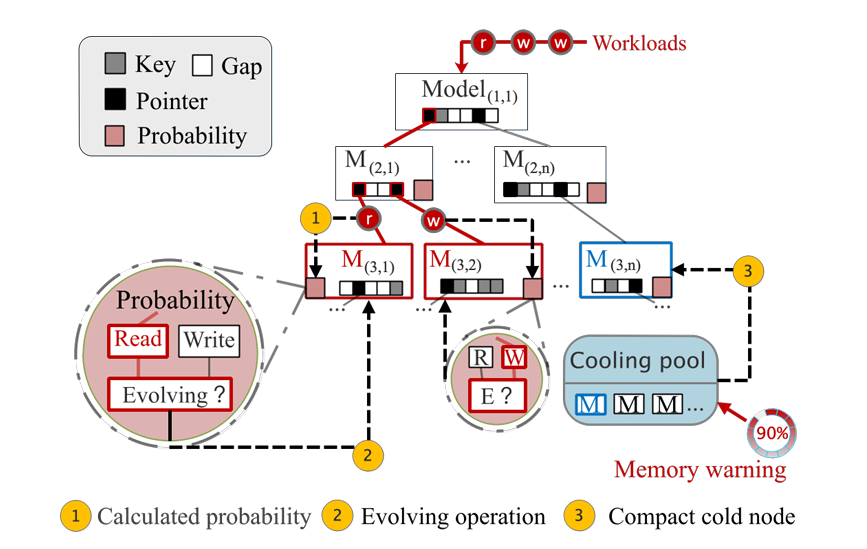
SALI提出的进化策略从插入、查找和冷节点识别三个方面提升学习型索引的并发性能。
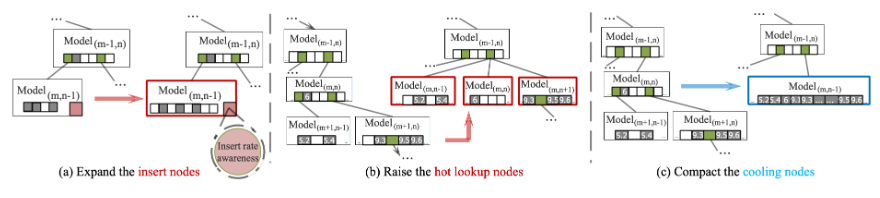
进化的策略
2.2.1 插入触发
包括SALI在内的大多数重新训练方法都涉及扩展目标节点或其子树。这种扩展创建了更多可用于插入键的间隙,从而提高了整体插入性能。当插入率增加时,应预留更多空隙以提高插入性能
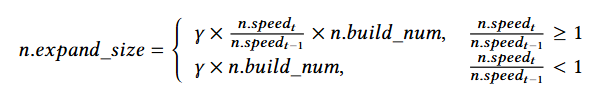
𝑛代表一个特定的节点,𝑛.𝑏𝑢𝑖𝑙𝑑_𝑛𝑢𝑚表示当前节点的大小。𝑛.𝑠𝑝𝑒𝑒𝑑代表时间𝑡的累积率,表示在该特定时间点新键插入节点的插入率。这意味着将比之前的扩展操作保留更多的空位。扩展因子𝛾的定义如下
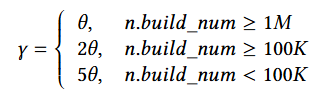
式中表明,不同大小的节点应该有不同的扩展因子。根据插入速率调整扩展因子,高插入速率时预留更多间隙,减少冲突和子节点创建。小节点(如< 100 键)采用更大扩展因子,快速适应突发写入,实现动态调整因子。
2.2.2 查询触发进化
热读节点开发了一种进化策略,以进一步提高在偏斜负载下的并发读性能。请注意,如果工作负载均匀,SALI可以选择禁用此进化功能或将每个节点视为热读节点。
子树扁平化:对高频访问节点,按相邻键间隙分割段,生成多个线性模型(算法4),降低树高并利用SIMD加速查询。
将线性模型的斜率乘以相应的倍数以扩展相应的空间。保留间隔使得存储数据的CDF更容易拟合直线,从而提高查找性能。
2.2.3 冷节点触发
冷节点压缩进化策略,以优化SALI在倾斜负载下的空间使用
冷却池机制如下,节点创建时以10%概率加入冷却池,长期未访问则压缩(取消预留间隙,用PLA算法线性拟合,算法5)。
压缩比达31%-37%,节省内存同时不影响热点节点性能。
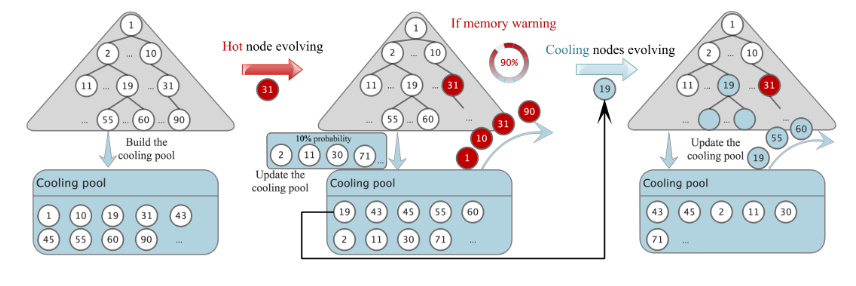
识别冷节点框架
2.3 概率模型
现有的高冲突统计技术严重限制了学习索引的可扩展性,为解决现有高争用统计技术限制索引可扩展性的问题,SALI提出基于概率的策略。通过设计概率模型模拟信息累积,以低成本触发进化操作
2.3.1 触发插入概率模型
大多数重训练都是由学习索引因插入操作而恶化触发的。然而,从索引性能的整体角度来看,应该根据调整后的局部结构是否将继续看到新键的高频插入来考虑调整。
插入进化触发条件:
条件1:新插入键数超过节点容量阈值,用插入速率和时间估计当前键数,避免全局累加计数器。
条件2:冲突率超过阈值,用几何分布估计冲突次数,冲突时触发概率计算,减少高频统计操作。
查询进化触发条件:
设定热点节点概率阈值(Phl),每10次查询执行伯努利试验,结合插入速率(Pacc)判断是否触发扁平化。
2.3.2 触发查找进化
定义目标节点由于查找操作被识别为热点读取节点,记为𝑃,这是一个可以设置为适当值的超参数。同时,设置读取触发概率的条件还需要考虑以下情况:
节点在一段时间内没有通过查找操作触发演变操作。
节点通过插入操作积累数的速度并不慢。对于条件(1),如果一个节点的演变操作是由热点查找触发的,说明节点没有严重退化,新的插入键的数量可能很少。
3.1实验设置
硬件:双路16核CPU(64线程),384GB内存。
基准:6个学习型索引(ALEX+、LIPP+、XIndex等)和2个传统索引(Masstree、ART-OLC)。
数据集:5个真实数据集(COVID、FACE、OSM等),涵盖均匀和复杂分布。
工作负载:纯写、读写混合、热点读写等,测试不同并发场景。
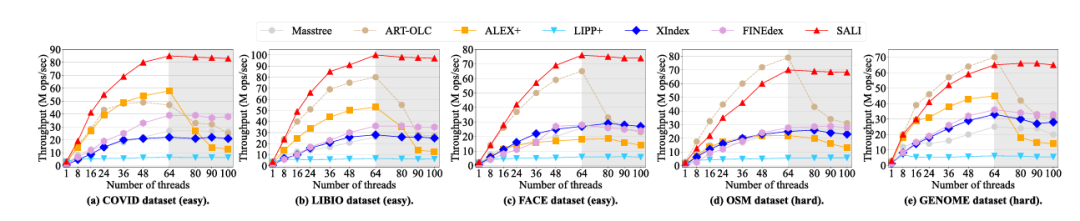
索引在读写工作负载中的可扩展性
3.2整体性能
3.2.1 纯写工作负载
并发插入通常面临三个挑战:
a)高竞争的统计信息维护导致线程阻塞;
b)粗粒度写锁导致线程阻塞;
c)写放大和查找错误导致内存带宽耗尽。SALI有效地解决了这些问题,从而实现了卓越的可扩展。
SALI的优势在于Easy数据集(COVID、FACE)中,吞吐量比ALEX + 和ART-OLC高47%-73%;在Hard数据集(OSM、GENOME)中,吞吐量提升2.5-10倍,尾延迟最低。
关键原因:细粒度锁避免线程阻塞,概率模型减少统计竞争,动态扩展策略降低冲突率。
仅写入的工作负载
3.2.2 读写混合工作负载
在读取密集型和平衡工作负载下,不同索引的性能如下图:

索引在读写工作负载中的可扩展性
在密集数据集中,SALI的性能比其他学习型索引高出2.5倍至10倍,因为SALI可以精确地拟合复杂的累积分布函数(CDF),因此其性能可以与ART-OLC相匹配,同时性能甚至超过了逻辑线程的数量,而相比之下,ART-OLC的性能急剧下降。
读密集场景:SALI吞吐量比ART-OLC和ALEX + 高37%-55%,得益于扁平化策略减少子树深度。
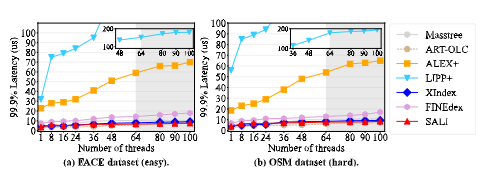
3.2.2 纯读工作负载
下图展示了只读工作负载的评估。SALI和LIPP+在简单和复杂数据集上都优于其他索引,因为它们采用基于模型的插入+链结构,这可以实现精确查找,SALI因冷节点识别引入轻微开销,略低于LIPP+,但尾延迟更低。

只读工作负载下的索引可扩展性
3.3进化策略效果
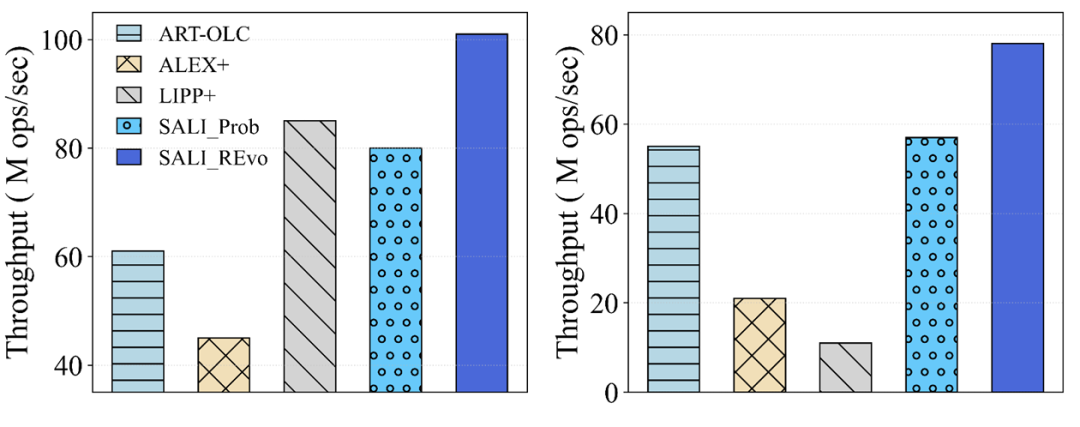
3.3.1 热点读触发进化
在OSM数据集上两个热读工作负载中学习索引的性能。SALI_Prob指的是仅使用概率模型的SALI,而SALI_REvo使用由读触发的演变策略。该图显示,在两个热读工作负载中,SALI_REvo分别比SALI_Prob高出27%和36%。在Hot-read-A工作负载中,SALI_REvo的性能已经超过了LIPP+。
进化策略的性能
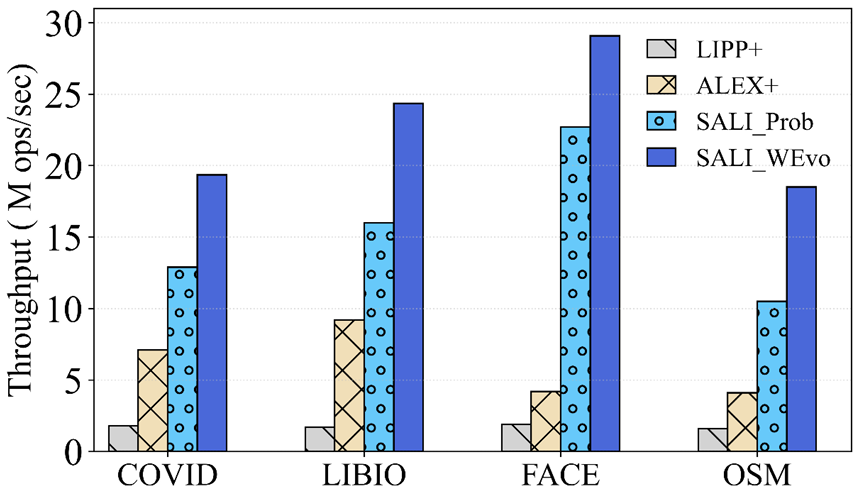
3.3.2 热点写触发进化
使用48线程的热写入工作负载的评估。SALI _WEvo 包括概率模型和由插入触发的演变策略。SALI _Prob仅包括概率模型和配备固定𝑛.𝑠𝑝𝑒𝑒𝑑(如公式(1)所述)的调整策略,类似于现有学习索引使用的调整方法,即扩展系数固定,在调整期间扩展相应的节点。
动态扩展优势:SALI_WEvo(自适应扩展)比固定扩展策略性能提升32%-80%,高插入速率时预留更多间隙,减少冲突和子节点创建。
热写触发进化性能
3.3.3 冷节点压缩
展示了OSM上学习索引的大小。值得注意的是,OSM上学习索引的大小大约是简单数据集的1.5倍。特别是,图14(a)显示了索引的内部结构大小,表明SALI产生的空间开销最小。空间节省:OSM和GENOME数据集压缩比分别为37%和31%,在不影响热点性能的前提下降低内存占用。
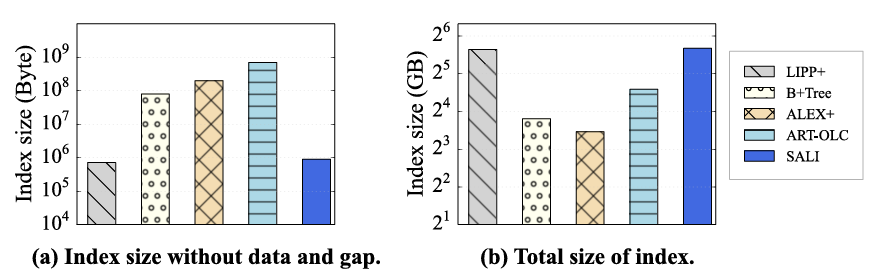
不同框架的索引大小
3.4消融研究
概率模型vs传统统计:SALI_Prob(概率模型)比SALI_Stat(全局统计)在60线程下性能高35%,证明轻量级统计的优势。
采样法vs概率模型:SALI_Samp(采样统计)性能介于两者之间,说明概率模型在减少竞争和保持精准性上的平衡。
4.1讨论解析
4.1.1 通用性与适用性
在任何应用场景中,包括但不限于并发设置,如果维护全局统计信息成为性能瓶颈,对于索引,采用基于概率的轻量级统计维护方法可以帮助提升性能。
1.概率模型:
可推广至其他学习型索引(如 DILI、LIPP),解决磁盘场景下的统计维护开销(如 ALEX 和 LIPP 的块读取开销)。
优于传统采样法(如 Anneser et al. 的全局采样),因概率计算本地化,竞争更低。
2.进化策略:
写进化:适用于缓冲区和模型策略索引,动态分配空间以提升插入性能。
读进化:在 HTAP 等大规模数据场景,通过 SIMD 加速多节点扁平化,进一步提升查询效率。
冷压缩:需针对缓冲区策略设计新压缩算法,为未来研究方向。
4.1.2 局限性
研究中也存在一定局限性如:
读进化开销:简单数据集(如LIBIO)因子树深度浅,启用读进化会引入节点判断开销,需动态开关优化。
不支持重复键:基于LIPP结构,未来计划通过溢出列表实现重复键插入
4.2相关工作
4.2.1 学习型索引发展过程
1.初代索引:RMI(静态,不支持更新)、FITing-tree(缓冲区策略,高预测误差)。
2.可更新索引:ALEX(移位法,粗粒度锁)、LIPP(链式法,统计竞争)、XIndex/FINEdex(缓冲区策略,并发性能差)。
3.SALI定位:首个结合细粒度锁、轻量级统计和自适应进化的框架,解决多核环境下的可扩展性问题。
4.2.2 与传统索引对比
Masstree/ART-OLC等模型依赖树结构优化(如基数树、自适应节点),但无法利用数据分布拟合提升预测效率。SALI的优势在于通过机器学习模型减少搜索层级,进化策略动态适应负载,在复杂数据分布下优势显著。
5.1结论
SALI通过 “结构进化 +概率统计” 双引擎,突破了传统学习型索引在多核环境下的可扩展性限制,为高效处理大规模、高并发数据提供了新范式。SALI的创新点主要体现在以下三点
框架创新:提出 SALI,通过节点进化策略(扩展、扁平化、压缩)和轻量级概率模型,解决高并发下的性能瓶颈。
性能突破:插入吞吐量平均提升 2.04 倍,尾延迟最低,在均匀和复杂数据集上均表现优异。
方法论贡献:证明自适应结构和概率统计在学习型索引中的有效性,为后续研究提供通用框架。
5.2未来展望
当前SALI可扩展学习索引框架有比较好的发展场景以及应用,在未来我们将主要聚集以下三个方面进行优化:
支持重复键和更复杂数据类型(如空间数据)。
优化读进化策略,自动确定扁平化节点数,降低简单数据集的开销。
结合深度学习模型提升 CDF 拟合精度,拓展至更多应用场景(如 HTAP、NVM 存储)
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





